YOLO v3 のアーキテクチャー[https://arxiv.org/pdf/1506.02640.pdf]
|
このページでは、YOLO アーキテクチャー を利用した物体検出の Python 実装を取り上げます。物体検出の有用なアルゴリズムである YOLO シリーズの各バージョンの Python 実装について説明します。このページの主要な目的は、web camera からのライブ映像の物体検出になります。
YOLO(You Only Look Once)とは、畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)を用いた物体検出アルゴリズムの一つです。YOLOは、SSDの物体検出アルゴリズムとは異なり、画像をバウンディングボックスで分割してクラス分類を行なっている。
YOLOのバージョンはV.2からV.8まであります。YOLOv5以降のモデルはPyTorch などには依存しませんが、Pytorch を用いてYOLOを実装する例も説明します。Pytorch のインストール方法は公式ページに行き、install ページの手順に従って、「Run this Command」のコマンドラインをコピペして下さい。PyTorch の初歩および画像分類に関する説明は、Pytorch入門のページを参照ください。
YOLOv.3までは、当時大学院生だったJoseph Chet Redmon 氏が開発したものです。YOLO v.3はDarknetというC言語コードで書かれたスクリプトをコンパイルした実行ファイルを用いて処理を行います。こちらのホームページを参照ください。その後、Aleksey Bochkovskiy氏がDarknetの Githubに依拠して、YOLOV.4の開発を行いました。そのGithub サイトはgithub.com/AlexeyAB/darknetです。
2020年に入って、Roboflowという会社が Pytorch 向けの YOLOV4 を発表しました。そのGithubがここです。さらに最近(2020年6月に)、Ultralytics社がPytorch向けのYOLO v.5 を公開しました。そのGithubはgithub.com/ultralytics/yolov5です。YOLOv5は、検出精度と演算負荷に応じてs、m、l、xまでの4モデルがあります。YOLOv5のsモデルを使用することで、YOLOv3のfullモデルに近い性能を、1/4以下の演算量で達成することができています。
2023年1月に、Ultralytics は YOLOv8 を公開しました。YOLOv8は、以前の YOLOv5 などのバージョンの成功を基盤として構築され、パフォーマンスと柔軟性をさらに高めるための新機能と改善が導入された最先端 (SOTA) モデルです。Medium の解説YoloV8: A Deep Dive Into Its Advanced Functions and New Featuresを参照ください。モデルのダウンロードについては、Ultralyticsの公式サイトを参照ください。
Last updated: 2023.11.16
YOLO(You Only Look Once) v3, v4 :darknet |
物体検出のアーキテクチャーは、一般的に、Sliding window approach または Region proposal method(RPM)と呼ばれる物体検出方法と、DNNによる深層学習による識別処理を組み合わせた構造をしています。SWAまたはRPMで対象物のある領域を検出し、その結果をディープニューラルネットワーク(DNN)による深層学習機能で物体を識別します。例えば、R-CNNといった物体検出では、Sliding window approachを用いて、画像の左上から右下にかけてウィンドウをスライドしていき、画像のすべての領域をウィンドウで探索し検出していきます。そしてウインドウごとに、逐一、ウィンドウ内に検出された物体らしきものに対して識別処理を行い、物体識別の判定を行う手法です。SWAをRPMに変えたアルゴリズムが Fast R-CNN と呼ばれるモデルです。様々な物体の画像を DNN に入力するだけで検出と識別を一貫して行う物体検出手法として注目を集めました。end-to-end の手法と言われます。
YOLOの手法は、RPMでの検出とDNNによる識別を並行的に行う方法を採用しています。YOLOの物体検出プロセスは、画像をグリッドに分割し、各セル内毎に物体のクラス確率とバウンディングボックスを予測する方法を採用します。さらに、各セルは複数のアンカーボックスを持ち、異なる形状の物体を検出できます。これにより、検出と識別の同時進行を実現しているので、高速な物体検出が可能になっています。
YOLOは、物体のクラス信頼性だけでなく、物体の位置情報、バウンディングボックスの座標を予測することにより、物体の範囲の特定が高精度に行えます。他方で、 RPMのグリッド分割の大きさは固定されているので、小さな物体や重なり合う物体の検出は不得手です。
Yolo v1 が最初のモデルで、Yolo v2が続いて開発されましたが、いくつかの不備が存在していました。Yolo v3 の登場は画期的なモデルでした。Yolo V3 は、feature pyramid network およびさまざまな検出スケールを組み込んでいるため、以前のバージョンに比べて大きな進歩を遂げています。この実装は精度と速度の点で最先端であり、2018年当時の最先端技術の地位を確立しました。
YOLO v3 のアーキテクチャー[https://arxiv.org/pdf/1506.02640.pdf]
最初に、YOLOv3を用いた物体検出の実行について説明します。ここで用いるYOLOのコードはdarknetと呼ばれるモジュールで実現されています。公式サイトはここです。この公式サイトで説明されている手続きに従って、インストールします。まずはGithubからクローンしましょう。そしてクローンしたフォルダに入ります。その後、makeしてビルドします。ここでは、Linux 系OSでのコンパイルをします。Windows ではCmakeを使用します。
$ git clone https://github.com/pjreddie/darknet.git $ cd darknet $ make
(darknet)$ ./darknet
usage: ./darknet
これで、darknetは正常に作動します。GPUを内蔵するPCで、CUDAをインストールしているときは、Makefile の先頭を
GPU=1
と修正します。その後に、make します。複数回のmake をする場合には、make clean コマンドを打ってください。
working directoryに cfg/ディレクトリが存在しているので、pretrained modelのweigtsをダウンロードすれば、YOLOV3の実行ができます。
(darknet)$ wget https://pjreddie.com/media/files/yolov3.weights
(darknet)$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BFLOPs
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs
4 res 1 208 x 208 x 64 -> 208 x 208 x 64
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BFLOPs
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
8 res 5 104 x 104 x 128 -> 104 x 104 x 128
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
11 res 8 104 x 104 x 128 -> 104 x 104 x 128
12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256 1.595 BFLOPs
13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
15 res 12 52 x 52 x 256 -> 52 x 52 x 256
-----(中略)
99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BFLOPs
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 10.278578 seconds.
truck: 92%
bicycle: 99%
dog: 99%
という結果が表示されます。検出された画像は

です。
次に、Yolov4 の使用について取り上げます。詳細は、Yolo v4 for Windows and Linuxを参照ください。対応する Google Colab はYOLO-v4.ipynbです。以下のように使用します。
$ git clone https://github.com/AlexeyAB/darknet $ cd darknet $ ./build.sh
ここでは、/build.sh を使用していますが、Cmake を使用するときに、バージョンの相違に関するエラーが起きるかもしれません。この時は、CMake のバージョンをアップデートして下さい。
$ wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights $ ./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg
結果はこうなります。pottedplant という新しい物体が検出されています。yolov3 比較して、検出精度は改善されていますが、処理スピードはかなり遅いです。やはり、GPUが必要です。
Loading weights from yolov4.weights... seen 64, trained: 32032 K-images (500 Kilo-batches_64) Done! Loaded 162 layers from weights-file Detection layer: 139 - type = 28 Detection layer: 150 - type = 28 Detection layer: 161 - type = 28 data/dog.jpg: Predicted in 27368.356000 milli-seconds. bicycle: 92% dog: 98% truck: 92% pottedplant: 33%
Yolov3 で行った物体検出と同様の画像「predictions.jpg」が保存されます。OpenCV へのアクセスがうまくいかないときは、「Not compiled with OpenCV, saving to predictions.png instead」と表示されます。
GPUを活用したYOLOv4の実証は、このColabにあります。GPUを使用するように Makefile を修正する必要があります。エディターを用いてもいいですが、以下のようなコードでも修正できます。
# change makefile to have GPU and OPENCV enabled %cd darknet !sed -i 's/OPENCV=0/OPENCV=1/' Makefile !sed -i 's/GPU=0/GPU=1/' Makefile !sed -i 's/CUDNN=0/CUDNN=1/' Makefile !sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile !make
以上のように、OPENCV=1、GPU=1、CUDNN=1、CUDNN_HALF=1 してから、 make します。実行ファイルdarknet がビルドされます。この後、画像からの物体検出を行うには、上記の .darknetb detect ... を実行します。
Scaled-YOLOv4という新しいバージョンも使用できます。上記のColabでは、このScaled-YOLOv4を用いた物体検出も実行できます。YOLOv4に比較してどの程度優れているかはよくわかりませんが、検出物体数が減少しますが、処理スピードは若干速いと思われます。
これは、Linux でのコンパイルの方法で、Windows でのコンパイルでは Visual Studio を使用します。以下の手順で行うことが推奨されています。Powershell を起動して(Start -> All programs -> Windows Powershell) 、以下のコマンドを打ちます。
PS Code\> git clone https://github.com/microsoft/vcpkg PS Code\> cd vcpkg PS Code\vcpkg> $env:VCPKG_ROOT=$PWD PS Code\vcpkg> .\bootstrap-vcpkg.bat PS Code\vcpkg> .\vcpkg install darknet[full]:x64-windows #replace with darknet[opencv-base,cuda,cudnn]:x64-windows for a quicker install of dependencies PS Code\vcpkg> cd .. PS Code\> git clone https://github.com/AlexeyAB/darknet PS Code\> cd darknet PS Code\darknet> powershell -ExecutionPolicy Bypass -File .\build.ps1
独自のデターセットでこのモデルの学習を行う方法については、このサイトを参照してください。
YOLO(You Only Look Once)v3, v4 : Pytorch |
YOLOの公式サイトはここです。このサイトには、インストールなどの手続きが説明されています。活用できるドキュメントも多数掲載されています。YOLO のアルゴリズムを解説している記事は Implement YOLO v3 from scratch にあります。
TensorFlowを使用しないので、処理速度はかなり速くなります。なお、コマンド"wget"を使用しますので、インストールされていないときは、"wget"をインストールして下さい。($ brew install wget)
最初に、Yolov3バージョンを取り上げます。パッケージ 'pytorch-yolo-v3' をダウンロードします。'pytorch-yolo-v3'は このGitHubからgit clone できます。
$git clone https://github.com/ayooshkathuria/pytorch-yolo-v3
学習済みモデルの重みをダウンロードする必要があります。ここでは、'yolov3.weights'を使います。このファイルを pytorch-yolo-v3 フォルダーの下に配置してください。
$ cd pytorch-yolo-v3 $ wget https://pjreddie.com/media/files/yolov3.weights
サイズは248MBです。物体検出にはPython コード 'detect.py' を使います。オプションを見るために、
$python detect.py -h
と打って見てください。検出するときの様々なオプションが表示されます。以下のように入力します。
$python detect.py --images imgs --det det
--images flag は検出対象の画像ファイルの指定をします。ここでは、 'imgs' に画像が入っています。--det は検出済みの画像ファイルを保存するフォルダーを指定します。'det' というフォルダーになっています。コマンドが正常に動作して、下のような表示が出ます。
Loading network..... Network successfully loaded dog.jpg predicted in 1.781 seconds Objects Detected: bicycle truck dog ---------------------------------------------------------- eagle.jpg predicted in 1.751 seconds Objects Detected: bird ---------------------------------------------------------- giraffe.jpg predicted in 1.784 seconds Objects Detected: zebra giraffe giraffe ---------------------------------------------------------- herd_of_horses.jpg predicted in 1.755 seconds Objects Detected: horse horse horse horse ---------------------------------------------------------- img1.jpg predicted in 1.847 seconds Objects Detected: person dog ---------------------------------------------------------- img2.jpg predicted in 1.842 seconds Objects Detected: train ---------------------------------------------------------- img3.jpg predicted in 1.817 seconds Objects Detected: car car car car car car car truck traffic light ---------------------------------------------------------- img4.jpg predicted in 1.768 seconds Objects Detected: chair chair chair clock ---------------------------------------------------------- messi.jpg predicted in 1.812 seconds Objects Detected: person person person sports ball ---------------------------------------------------------- person.jpg predicted in 1.850 seconds Objects Detected: person dog horse ---------------------------------------------------------- SUMMARY ---------------------------------------------------------- Task : Time Taken (in seconds) Reading addresses : 0.001 Loading batch : 3.065 Detection (11 images) : 20.594 Output Processing : 0.000 Drawing Boxes : 0.190 Average time_per_img : 2.168 ----------------------------------------------------------
Tensorflowを使うときに比較して処理速度はより速いです。保存された画像の一つは

です。carとtruckの違いを検出しています。信号機まで検出されています。
リアルタイムでの物体検出の仕方について説明します。web cameraからの映像を取り込むコードは 'cam_demo.py' です。USB接続されたwebcamからの映像をキャプチャーしたいときは、この 'cam_demo.py' の106行が 'cap = cv2.VideoCapture(0)' となっているときは、 'cap = cv2.VideoCapture(1)' に修正してください。
以下の通りに、シンプルにコマンドを入力します。1回目の入力で実行されないときは、2回目の入力をすると実行されます。
$ python cam_demo.py FPS of the video is 0.24 FPS of the video is 0.42 FPS of the video is 0.56 FPS of the video is 0.69 FPS of the video is 0.78 ------
と表示が現れて、webcamの映像で検出された物体に枠がついた動画がリアルタイムで表示されます。動画映像は保存されません。webcamの映像の動きと連動して、ほとんど瞬間的に検出画像が切り替わります。速いです
次に、Yolov4バージョンのPytorch実装を取り上げます。Github repoはpytorch-YOLOv4です。ただ、このpytorchバージョンはGPUを前提としますので、Google Colabを利用した方がいいです。作成したColabはここにあります。
$ git clone https://github.com/Tianxiaomo/pytorch-YOLOv4 $ pip install requirements.txt # 必要がある時
学習済みモデルの重み'yolov4.weights'をダウンロードする必要があります。このファイルを pytorch-YOLOv4 フォルダーの下に配置してください。
$ cd pytorch-YOLOv4 $ wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
サイズは257MBです。物体検出にはPython コード 'demo.py' を使います。以下のように入力します。
$python demo.py -cfgfile cfg/yolov4.cfg -weightfile yolov4.weights -imgfil data/dog.jpg
結果は、predictions.jpgとして保存されます。この画像を表示したいときは、python スクリプトで
from IPython.display import Image
imShow('predictions.jpg')
と入力します。
Pytorch-YOLOv5 |
次に、Yolo(You Only Look Once)v5 バージョンの実装を取り上げます。このパッケージを利用するためには、Python>=3.8 および PyTorch>=1.7 がインストールされていることが必要です。ultralytics/yolov5を参照してください。そのGoogle Colab は YOLOv5_tutorials_roboflow.ipynbにあります。以下のように git clone します
$ git clone https://github.com/ultralytics/yolov5 $ cd yolov5 $ pip install -r requirements.txt
これで準備はできました。通常は、Jupyter notebook を起動して、tutorial.ipynb を使用して実行します。
ここでは、Python スクリプトを用いた物体検出を行ってみましょう。以下のように入力して下さい。
$ python detect.py --source data/images --weights yolov5s.pt --conf 0.25
これは data/images ディレクトリにある2種類の画像からの物体検出の実行例です。結果は以下のように、 runs/detect/exp 内に保存されます。bus.jpg 、 zidane.jpg です。
result: Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='data/images', update=False, view_img=False, weights=['yolov5s.pt']) YOLOv5 v4.0-83-gd2e754b torch 1.7.1 CPU Fusing layers... Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS image 1/2 /Users/koichi/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.313s) image 2/2 /Users/koichi/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.242s) Results saved to runs/detect/exp

Zidane.jpg
「Error #15: Initializing libiomp5.dylib, but found libomp.dylib already initialized.」というエラーが出た場合は、detect.py の中に
import os os.environ['KMP_DUPLICATE_LIB_OK']='True'
という1行を挿入して下さい。このエラーは消えます。
次に、webcamera のライブ映像から物体検出を実行しましょう。webcamera を接続して、以下のように打って下さい。
$ python detect.py --source 0 ----- result: Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='0', update=False, view_img=False, weights='yolov5s.pt') YOLOv5 v4.0-83-gd2e754b torch 1.7.1 CPU Fusing layers... Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS 1/1: 0... success (1280x960 at 25.00 FPS). 0: 480x640 3 bottles, 1 sandwich, 4 books, Done. (0.365s) 0: 480x640 1 cat, 3 bottles, 1 laptop, 6 books, Done. (0.336s) 0: 480x640 3 bottles, 1 laptop, 7 books, Done. (0.341s) 0: 480x640 1 cat, 3 bottles, 1 laptop, 5 books, Done. (0.343s) --- ---
コマンドは非常に簡単です。検出速度は非常に速いです。コマンドの実行時に、「AttributeError: 'NoneType' object has no attribute 'shape'」というエラーが時々出ますが、再度実行すれば正常に作動します。
PyTorch Hub を利用したYOLOv5 の実装については、Load YOLOv5 from PyTorch Hubを参照ください。その説明にそって、以下のスクリプトを作成して、detailed_example.pyとして保存して下さい。
# Detailed Example
import cv2
import torch
from PIL import Image
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True) # for file/URI/PIL/cv2/np inputs and NMS
# Images
for f in ['zidane.jpg', 'bus.jpg']: # download 2 images
print(f'Downloading {f}...')
torch.hub.download_url_to_file('https://github.com/ultralytics/yolov5/releases/download/v1.0/' + f, f)
img1 = Image.open('zidane.jpg') # PIL image
img2 = cv2.imread('bus.jpg')[:, :, ::-1] # OpenCV image (BGR to RGB)
imgs = [img1, img2] # batched list of images
# Inference
results = model(imgs, size=640) # includes NMS
# Results
results.print() # print results to screen
results.show() # display results
results.save() # save as results1.jpg, results2.jpg... etc.
ターミナルから以下のコマンドを打って下さい。
$ python detailed_example.py
二枚の画像(bus.jpg, zidane.jpg)を使った結果が、ディスプレイ上にポップアップ表示され、ディレクトリ result に保存されます。作成するコードが非常に簡単です。

bus.jpg
最近では(2021年3月)、YOLOv5は pip コマンド用いてインストールできるようになっています。例えば、
$ pip install "numpy>=1.18.5,<1.20" "matplotlib>=3.2.2,<4" $ pip install yolov5
と入力すると、使用できます。
PyPIのサイトには、具体的な例として以下のコードが掲載されています。
from PIL import Image
from yolov5 import YOLOv5
# set model params
model_path = "yolov5/weights/yolov5s.pt" # it automatically downloads yolov5s model to given path
device = "cuda" # or "cpu"
# init yolov5 model
yolov5 = YOLOv5(model_path, device)
# load images
image1 = Image.open("yolov5/data/images/bus.jpg")
image2 = Image.open("yolov5/data/images/zidane.jpg")
# perform inference
results = yolov5.predict(image1)
# perform inference with higher input size
results = yolov5.predict(image1, size=1280)
# perform inference with test time augmentation
results = yolov5.predict(image1, augment=True)
# perform inference on multiple images
results = yolov5.predict([image1, image2], size=1280, augment=True)
この後、train.py, detect.py and test.py などのpython スクリプトを pip を用いてダウンロードすることができます。
Pytorch-YOLOv7 |
次に、Yolo(You Only Look Once)v7 バージョンの実装を取り上げます。Official YOLOv7 Implementation of paper - YOLOv7にコードがあります。Jupyter Notebook に以下のサンプルコードをコピペしてください。
以下のように git clone します。
#: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors # Install Dependencies # Download YOLOv7 repository and install requirements !git clone https://github.com/WongKinYiu/yolov7 %cd yolov7 !pip install -r requirements.txt
学習済みモデルを使用した予測の実行は以下の様式で行います。
#Inference On video: python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source yourvideo.mp4 On image: python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
ここで使用する学習済みモデルは、例えば、以下のモデルが使用できます。使用するモデルを --weights の引数に記述します。自動的にダウンロードされます。
https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7x.pt
使用する画像データは inference/images/ にありますが、自身の画像を利用することもできます。以下では、bus.jpg と zidane.jpg を使用しています。
!python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/bus.jpg
!python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/zidane.jpg
結果は以下のように、 runs/detect/exp 内に保存されます。
from IPython.display import Image, clear_output # to display images Image(filename='runs/detect/exp/bus.jpg') Image(filename='runs/detect/exp2/zidane.jpg')
以上のサンプルコードはこのGoogle Colab にアップしてあります。
segmentation のためのコードの紹介はしませんでした。興味のある人は、この Colaboratory の Notebook を参照してください。Detectron2 を用いた segmenation については、このページを参照ください。
YOLOv8の利用 |
Ultralytics によって開発された YOLOv8 は、以前の YOLOv5 などのバージョンの成功を基盤として構築され、パフォーマンスと柔軟性をさらに高めるための新機能と改善が導入された最先端 (SOTA) モデルです。 YOLOv8 は、高速、正確、そして使いやすいように設計されており、幅広いオブジェクト検出、画像セグメンテーション、画像分類タスクに便利です。YOLOv8 は、コマンドラインからの入力またはPython 環境下で使用できるようになっています。
実行例のコードは、このUltralyticsのGithubに紹介されています。C++およびPythonを用いた実行例が紹介されています。
例えば、Jupyter Notebookを利用するときは、Ultralyticsと必要パッケージをインストールするために、以下のコマンドを入力します。
%pip install ultralytics
物体検出を行うときは、例えば、以下のようにします。学習済みモデルとして yolov8n.pt を利用します。
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
model = YOLO('yolov8n.pt')
# Define path to the image file
source='https://ultralytics.com/images/bus.jpg'
# Run inference on the source
results = model.predict(source, save=True, imgsz=320, conf=0.5) # list of Results objects
以下の結果が表示されます。
Found https://ultralytics.com/images/bus.jpg locally at bus.jpg image 1/1 /Users/koichi/Yolo/bus.jpg: 320x256 3 persons, 1 bus, 175.9ms Speed: 6.1ms preprocess, 175.9ms inference, 15.4ms postprocess per image at shape (1, 3, 320, 256) Results saved to /Users/koichi/runs/detect/predict
検出の結果は、各ユーザーのフォルダーにrunsというフォルダーが新規作成され、/runs/detect/predict/に保存されます。結果を表示してみましょう。
# View results for r in results: print(r.boxes) # print the Boxes object containing the detection bounding boxes # Display the results from IPython.display import Image, clear_output # to display images Image(filename='/Users/koichi/runs/detect/predict/bus.jpg')
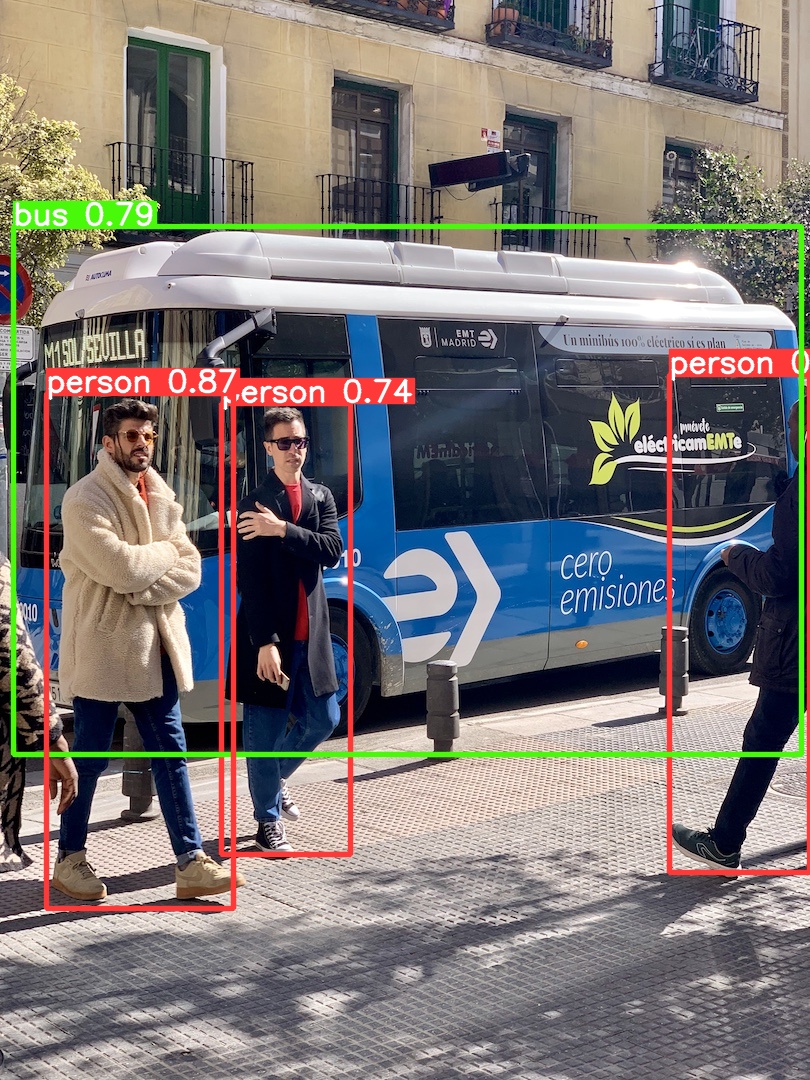
yolov8n.ptを用いた物体検出
webcameraからのライブ映像で物体検出を実行するときは、例えば、以下のコードを用います。
import cv2
#from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Open the video file
cap = cv2.VideoCapture(0)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
セグメンテーションを行うときは、yolo8x-seg.pt モデルの中から選択して、以下のようなコードで実行します。
# load the pretrained yolov8n-seg.pt model
model = YOLO('yolov8n-seg.pt')
# Predict with segmentation
results = model.predict(source, save=True, imgsz=320, conf=0.5)
セグメンテーションの結果は、各ユーザーの/runs/segment/predict/に保存されます。

yolov8n_seg.ptによるセグメンテーション
COCO128のデータを用いたモデルの学習は以下のように行います。学習をさせるモデルとして yolov8n.pt を用います。
# Train YOLOv8n on COCO128 for 3 epochs
model = YOLO('yolov8n.pt') # load a pretrained YOLOv8n detection model
model.train(data='coco128.yaml', epochs=3) # train the model
model('https://ultralytics.com/images/bus.jpg', save=True) # predict on an image
GPUが必要なので、Google Colabを利用しました。結果は runs/detect/train/ に保存されます。
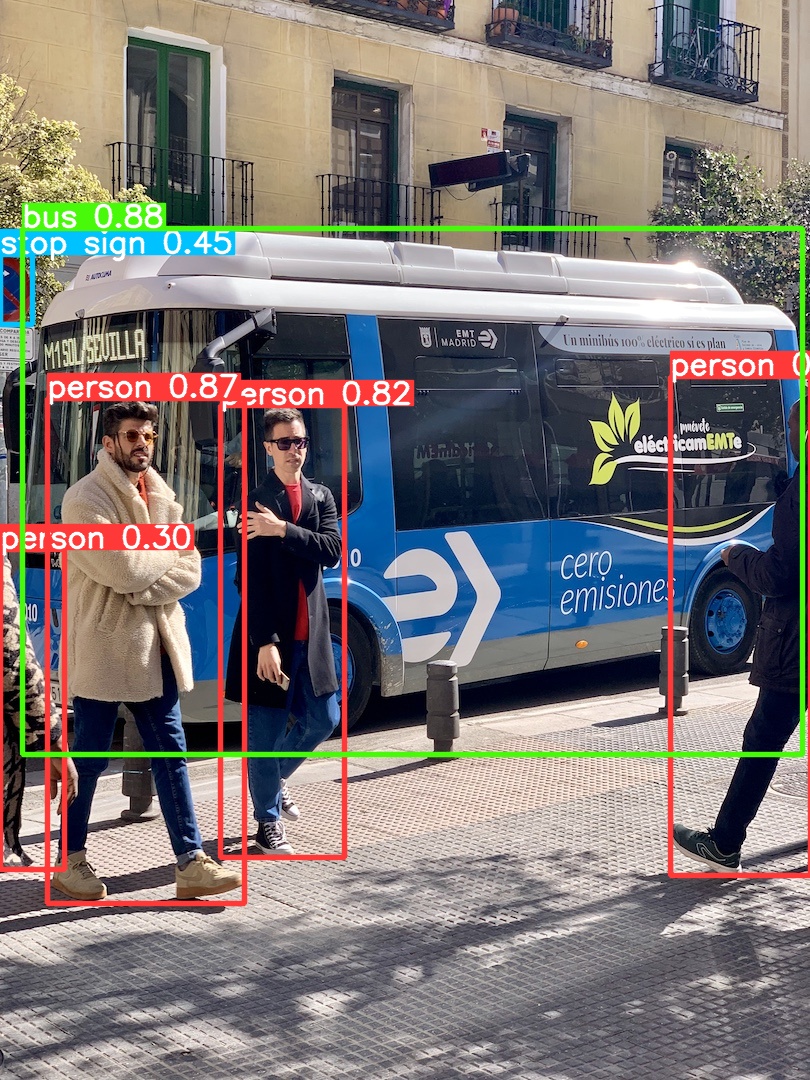
Coco128を用いた学習
モデルを再学習させると、画像中の「stop sign」が新たに検出されました。
私が使用したPython コードでの物体検出の例はColabのサイトにアップしてあります。
ご質問、コメントなどは こちらからメール送信して下さい。