Welcome to Mashykom WebSite
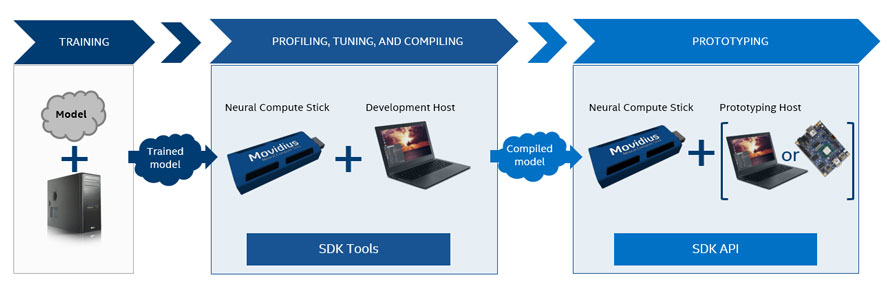
Intel® Movidius™ Neural Compute Stick(NCS)は、AIプログラミングを習得できるように設計された、ディープ・ラーニング(DNN)用のUSBスティックです。Movidius NCSは、より低い消費電力で作動する高い性能のMovidius™ビジュアル処理ユニット(VPU)を内蔵しています 。ビジュアル処理ユニット(VPU)は、すでに、膨大な個数のスマート・セキュリティ・カメラ、制御用ドローン、産業用視覚機器などに搭載されています。NCSは600 MHz Myriad-2 SoC (128ビットVLIW SHAVEベクトルプロセッサ x 12基搭載) • 転送速度400 Gbpsのオンチップメモリ2 MBを搭載しています。
こうして、Movidius™のNeural Network Compute Stickは、スーパーコンピュータなどを必要とせずに、ディープニューラルネットワーク(DNN)の開発を可能にします。単純にMovidiusスティックの100 Gflopsの演算力で、DNNのプロトタイピングとチューニングを行います。クラウド接続は要りません。USBスティック形状なのでホストコンピュータ(PCなど)に簡単に接続できます。単一のUSB Type-Aポートで提供される電源を用いて、同じプラットフォーム上で複数のNCSを接続して、実行することもできます。ラズパイに人工知能を組み入れる
にあります。
Last updated: 2018.7.15
Movidius NCS SDKのインストールと関連環境構築
こちらです。 スイッチサイエンスマガジン になります。NCSDKをインストールする前に環境設定をしておきます。
$ sudo apt-get update
$ sudo apt-get install python3-pip python3-dev
$ wget https://github.com/lhelontra/tensorflow-on-arm/releases/download/v1.3.1/tensorflow-1.3.1-cp35-none-linux_armv7l.whl
$ sudo pip3 install tensorflow-1.3.1-cp35-none-linux_armv7l.whl
TensorFlowの公式ホームページ によれば、Tensorflowのインストールは以下の通りです。pip3 version 8.1 or higher が必要です。
$ sudo apt-get install python3-pip python3-dev
$ sudo apt install libatlas-base-dev
$ pip3 install tensorflow
$ sudo shutdown -r now
$ free -m
total used free shared buffers cached
Mem: 862 818 43 15 19 643
-/+ buffers/cache: 156 705
Swap: 1023 0 1023
$ git clone http://github.com/Movidius/ncsdk && cd ncsdk && make install && make examples
$ wget https://github.com/mt08xx/files/raw/master/opencv-rpi/libopencv3_3.4.0-20180115.1_armhf.deb
$ sudo apt install -y ./libopencv3_3.4.0-20180115.1_armhf.deb
$ sudo ldconfig
$ cd ~/ncsdk/examples/tensorflow/inception_v3
(/ncsdk/examples/tensorflow/inception_v3) $ python3 run.py
Number of categories: 1001
Start download to NCS...
*******************************************************************************
inception-v3 on NCS
*******************************************************************************
547 electric guitar 0.98828
403 acoustic guitar 0.0077209
715 pick, plectrum, plectron 0.0015087
421 banjo 0.00092602
820 stage 0.00065947
*******************************************************************************
Finished
Movidius NCS を用いたリアルタイム物体検出:YoloNCS
$ git clone https://github.com/gudovskiy/yoloNCS.git
$ mkdir -p ~/yoloNCS/weights
$ cd yoloNCS
(yoloNCS)$ mvNCCompile prototxt/yolo_tiny_deploy.prototxt -w weights/yolo_tiny.caffemodel -s 12
(yoloNCS)$ python3 py_examples/object_detection_app.py
(yoloNCS/py_examples)$ python3 yolo_example.py ../images/dog.jpg
@pon_dat さん作成のスクリプト をダウンロードします。web cameraからの映像の上部に検出された物体の名称が表示されます。物体検出のカテゴリー数は1000種類となっています。物体の検出枠取りはされていません。Movidiusのおかげで、検出速度は相当早いです。
Movidius NCS を用いたリアルタイム物体検出:NC App Zoo
Neural Compute App Zoo GitHub repository と呼ばれるユーザーアプリケーションのリポジトリが利用できます。このリポジトリを以下のようにダウンロードします。
$ git clone https://github.com/movidius/ncappzoo.git
$ cd ncappzoo && make install
$ cd /home/pi/ncappzoo/apps/
(/home/pi/ncappzoo/apps)$make all
$ cd /home/pi/ncappzoo/caffe/
(/home/pi/ncappzoo/caffe)$make all
$ cd /home/pi/ncappzoo/tensorflow/
(/home/pi/ncappzoo/tensorflow)$make all
(ncappzoo/apps) $ cd ssd-object-detector
(ncappzoo/apps/ssd-object-detector) $ make run
(以下のような表示が出ます)
making MobileNet SSD
(cd ../../caffe/SSD_MobileNet; test -f graph || make compile;)
Running ssd-object-detector.py
python3 ssd-object-detector.py
==============================================================
I found these objects in pic_064.jpg
Execution time: 80.2747ms
--------------------------------------------------------------
99.0% 12: dog: Top Left: (51, 47) Bottom Right: (179, 182)
==============================================================
$ python3 ssd-object-detector.py --image ../../data/images/pic_053.jpg
$ cd ncappzoo/apps/video_objects
$ make all
$ python3 video_objects.py
$ cd /home/pi/ncappzoo/apps/live-object-detector
(/home/pi/ncappzoo/apps/live-object-detector)$ python3 live-object-detector.py
...
I found these objects in ( 80.56 ms ):
96.0% 5: bottle: Top Left: (106, 459) Bottom Right: (481, 598)
95.0% 15: person: Top Left: (4, 407) Bottom Right: (455, 631)
79.0% 20: tvmonitor: Top Left: (99, 246) Bottom Right: (186, 355)
....
ISVRC 1000 categories です。Tensorflowのモデルで使用可能な学習済みモデルは以下の通りとなっています。
$ cd /home/pi/ncappzoo/tensorflow/inception_v4
(home/pi/ncappzoo/tensorflow/inception_v4)$ make all
(home/pi/ncappzoo/tensorflow/inception_v4)$ python3 run.py
Number of categories: 1001
Start download to NCS...
*******************************************************************************
inception-v4 on NCS
*******************************************************************************
547 electric guitar 0.9873
403 acoustic guitar 0.0091705
421 banjo 0.0015497
715 pick, plectrum, plectron 0.00080442
820 stage 0.00027895
***********************************************
Finished
AgeNet
AlexNet
GenderNet
GoogLeNet
ResNet-18
SqueezeNet
SSD_MobileNet
TinyYolo
このページのトップに戻る
Raspberry Pi で 電子工作のページに行く
トップページに戻る