|
自然言語処理(natural language processing:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能の一分野である。自然言語処理は工学的な視点からの言語処理、データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な(コンピュータが理解しやすい)表現に変換するといった処理が含まれる。
統計的自然言語処理は、確率論的あるいは統計学的手法を使って、上述の困難さに何らかの解決策を与えようとするものです。統計的自然言語処理の起源は、人工知能の中でもデータからの学習を研究する分野である機械学習やデータマイニングといった分野になります。
自然言語の処理技術の応用範囲は広く、日常の様々な生活分野で利用されています。GoogleやYahooの検索エンジンに組み込まれていることは当然です。Google翻訳やオンライン翻訳などの機械翻訳、Microsoft Office WordやSmartNewsなどの要約文の自動生成にも活用されています。最近では、AppleのSiriやGoogle Home、 Amazon Echo、NTTドコモの「しゃべってコンシェル」などの音声認識・応答などに自然言語処理の技術が使われています。
また、テキストマイニングと呼ばれる手法が各産業界での製品開発や営業活動においても広範に採用されるようになっています。テキストマイニングとは、大量の文章データ(テキストデータ)から、自然言語処理の手法を使って、文章を単語(名詞、動詞、形容詞等)に分割し、それらの出現頻度や相関関係を分析することで有益な情報を抽出することを言います。コールセンターでの質疑応答の記録や、WEBページでの質問文、アンケート調査の自由記述文などの企業内に蓄積されたデータの他、インターネット掲示板での書き込み、口コミサイトや、SNS(Facebook、Twitter etc.)の記事などのソーシャルメディア上にも有益なテキストデータが溢れています。これらのビッグデータを利用したテキストマイニングが企業活動にとっても重要になってきました。
このページでは、Pythonを用いて自然言語処理を行うときに必要となる主要なライブラリとそれらの基本的な使用方法を説明します。自然言語処理用のpythonライブラリでもっとも有名なものは、NLTK: Natural Language Toolkit)ですが、これは主に英語を対象とした自然言語処理を取り扱っています。内容や考え方の多くは言語に依存しませんが、日本語を取り扱う場合にはそれに相応しい処理方法が必要となります。日本語の自然言語処理について最初に説明したいので、NLTK を用いた自然言語処理については、続編に説明を譲ります。NLTKの使用法についての説明は、自然言語処理:続編を参照ください。
自然言語処理を実行するためには、前処理と呼ばれる工程が必要になります。トークン化と呼ばれる前処理が必須です。トークン化は原文テキスト(strクラス)を言語的な各単位(文字や句読点など)に分解することです。最も単純なトークン化の方法は空白を目印にしてテキストを分解するトークン化です。しかし、この手法は日本語では使えません。
日本語処理に必要な事前処理として用いられることが多い形態素解析を行う目的や,形態素解析の説明をします。日本語の処理でもっとも利用されている形態素解析器の1つであるMeCabを取り上げ,インストール方法や実行例を確認します。
その後、MeCabを用いて日本語平文コーパスをトークン化して、word2vec でコーパスのベクトル化を行い、トピックモデルを作成します。word2vec でコーパスのベクトル化をgensim を用います。つまり、MeCabとgensimを組み合わせたトピックモデルの実装について、説明します。
次に、word2vec を拡張したfastText のインストールを説明して、fastText の簡単な使用法について説明します。これを受けて、fastText とgensim を組み合わせて、日本語の文書を使って、類似単語の検出を試みましょう。
機械学習の多くのフレームワークはPython及びC++で記述されています。ニューラルネットワークの基本的構造とその実装を理解するための言語としてはPythonが理解できれば十分でしょう。そういう意味では、この領域において必須のプログラミング言語はPythonです。Anacondaのような一括インストーラーを用いてPython3がセットアップ済みであることを前提とします。LinuxやC言語の知識は想定していません。
このページに掲載されているコードの多くは私のGitHub のRepoにあります。Python環境がない方も、Google Colabで実行できるノートブックもありますので、ご利用ください。
Last updated: 2019.12.26(first uploaded 2018年9月30日)
MeCabのインストールと基本的使用方法 |
自然言語処理では、はじめに、処理したいテキストを単語に分割する前処理が必要となります。単語に分割するためには、文章を形態素に分割していきます。形態素とは意味を持つ最小の言語単位であり、形態素解析(Morphological Analysis)とは与えられた文を形態素単位に区切り、各形態素に品詞(part of spech)などの情報を付与する処理のことです。形態素の定義はもともと欧米語の言語学から来たものであるため、まちまちであり確立されていません。日本語形態素解析の立場から言えば、辞書に記載されている見出し語を形態素と見なし、その単位に分割すると同時に、見出し語にひもづく品詞や標準形などを形態素に付与する処理であると言えます。
文は、名詞や動詞、形容詞のような自立語と、助動詞、助詞のように異なる品詞の言葉と組み合わさって文節を作る付属語で構成されています。異なる品詞が組み合わさっている文節は、更に品詞単位に分割します。このようにして、自然言語処理の前処理が行われます。自然言語処理は、1. 形態素解析→2. 構文解析→3. 意味解析→4. 文脈解析の順で行われます。
現在主流の形態素解析ソフトの1つであるMeCabを取り上げ,インストール方法や実行例を確認します。Mecabは、京都大学情報学研究科と日本電信電話株式会社コミュニケーション科学基礎研究所の共同研究で開発された、オープンソースの形態素解析エンジンです。言語,辞書,コーパス(データベース化されている言語資料)に依存しない汎用的な設計方針を採用しており,C言語,C++,Java,python等,数多くの言語で使用することが可能になっています。日本語の形態素解析エンジンの中では最もよく使用されています。名称は、GoogleソフトウェアエンジニアでGoogle 日本語入力開発者の一人である工藤拓の好物「和布蕪(めかぶ)」から取られたと言われています。公式ホームページは、MeCab (和布蕪)にあります。
簡単にmacOSにMeCabをインストールするには「Homebrew」を使います。 HomebrewとはMacOS用のパッケージ管理システムの一つで、Homebrewがあれば比較的簡単にmacOSにソフトウェアを導入することが可能となります。(Windowsのケースでは、MeCab公式サイトのdownloadのリストバイナリパッケージのうち,『MeCab本体』のBinary package for MS-Windows mecab-0.996.exeをダウンロードする.)
Mac OS Catalina にHomebrewをインストールしましょう。Homebrewはターミナルから簡単にインストールすることができます。下記のコマンドをターミナルから実行します。
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Homebrewを使ってMacにMeCabをインストールします。インストールしたHomebrewを使ってMacにMeCabをインストールしましょう。こちらもターミナルから下記のコマンドを実行するだけです。
$ brew install mecab
これでMeCabはインストールされましたが、MeCabを利用するには特別な辞書データが必要となるのでそちらもインストールしましょう。サイズは約700MBです。
MeCabで使用する辞書もHomebrewを使って簡単にインストールできます。こちらもターミナルから下記のコマンドを実行するだけです。
$ brew install mecab-ipadic
これでMacでMeCabを実行できるようになりました。
では実際にMacでMeCabを実行してみましょう。では初めにターミナルから下記のコマンドを実行してみましょう。
$ mecab
すると空白の行が出てくるので、そこに解析させたい文章を入力してみましょう。今回はとりあえず「私の朝食はパンでした。」と入力してみます。以下のコードは、このGoogle Colabを開くと実行できます。
すると下記のように解析結果が表示されます。私の朝食はパンでした。 私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ の 助詞,連体化,*,*,*,*,の,ノ,ノ 朝食 名詞,サ変接続,*,*,*,*,朝食,チョウショク,チョーショク は 助詞,係助詞,*,*,*,*,は,ハ,ワ パン 名詞,一般,*,*,*,*,パン,パン,パン でし 助動詞,*,*,*,特殊・デス,連用形,です,デシ,デシ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 。 記号,句点,*,*,*,*,。,。,。 EOS
文章を構成している各単語(名詞)に分解されています。mecab の終了は「Ctrl+c」です。
PythonからMeCabを使用するためには,mecab-python3というパッケージをインストールします。インストールにはpipコマンドを用います。
$ pip install mecab-python3注意:Mac OS MojaveのCommand Line Tools for Xcode10では、 mecab-python3 のインストールでエラーが出ます。インストールが成功するためには、Command Line Tools for Xcode9.4 にダウングレードする必要があります。Command Line ToolsはAppleのWebsiteから無料でダウンロードできます。
Pythonから使用する場合は,以下のように記述します。最初に、Python を起動してから、
>>> import MeCab >>> sent ="気温が上がるとどうしても比例するのが電力使用量だ。9日は、全国の電力会社のうち8社の管内で、いずれも最大電力使用量が今夏最高を記録した。" >>> tagger = MeCab.Tagger() >>> print(tagger.parse(sent))
と打ってください。以下の結果が表示されます。
気温 名詞,一般,*,*,*,*,気温,キオン,キオン が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 上がる 動詞,自立,*,*,五段・ラ行,基本形,上がる,アガル,アガル と 助詞,接続助詞,*,*,*,*,と,ト,ト どうしても 副詞,一般,*,*,*,*,どうしても,ドウシテモ,ドーシテモ 比例 名詞,サ変接続,*,*,*,*,比例,ヒレイ,ヒレイ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル の 名詞,非自立,一般,*,*,*,の,ノ,ノ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 電力 名詞,一般,*,*,*,*,電力,デンリョク,デンリョク 使用 名詞,サ変接続,*,*,*,*,使用,シヨウ,シヨー 量 名詞,接尾,一般,*,*,*,量,リョウ,リョウ だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ 。 記号,句点,*,*,*,*,。,。,。 9 名詞,数,*,*,*,*,9,キュウ,キュー 日 名詞,接尾,助数詞,*,*,*,日,ニチ,ニチ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 、 記号,読点,*,*,*,*,、,、,、 全国 名詞,一般,*,*,*,*,全国,ゼンコク,ゼンコク の 助詞,連体化,*,*,*,*,の,ノ,ノ 電力 名詞,一般,*,*,*,*,電力,デンリョク,デンリョク 会社 名詞,一般,*,*,*,*,会社,カイシャ,カイシャ の 助詞,連体化,*,*,*,*,の,ノ,ノ うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ 8 名詞,数,*,*,*,*,8,ハチ,ハチ 社 名詞,接尾,助数詞,*,*,*,社,シャ,シャ の 助詞,連体化,*,*,*,*,の,ノ,ノ 管内 名詞,一般,*,*,*,*,管内,カンナイ,カンナイ で 助詞,格助詞,一般,*,*,*,で,デ,デ 、 記号,読点,*,*,*,*,、,、,、 いずれ 名詞,代名詞,一般,*,*,*,いずれ,イズレ,イズレ も 助詞,係助詞,*,*,*,*,も,モ,モ 最大 名詞,一般,*,*,*,*,最大,サイダイ,サイダイ 電力 名詞,一般,*,*,*,*,電力,デンリョク,デンリョク 使用 名詞,サ変接続,*,*,*,*,使用,シヨウ,シヨー 量 名詞,接尾,一般,*,*,*,量,リョウ,リョウ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 今夏 名詞,副詞可能,*,*,*,*,今夏,コンカ,コンカ 最高 名詞,一般,*,*,*,*,最高,サイコウ,サイコー を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 記録 名詞,サ変接続,*,*,*,*,記録,キロク,キロク し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 。 記号,句点,*,*,*,*,。,。,。 EOS
この例で明確に理解できるように、日本語は、英語のようにスペースで単語が区切られていないため、まず文章から単語を切り出す必要があります。次に文章の構造をコンピュータで取り扱える形式にしますが、一般的には「係り受け構造」(構文解析)で表現します。日本語の文には、「私-は」「人参−が」「嫌い−です」というように、自立語(=名詞・動詞・形容詞)と付属語(=助詞・助動詞)からなる『文節』という単位があります。この文節が組み合わさって修飾→被修飾の関係(係り受け)ができます。小さな係り受けから、広い範囲の係り受けにまとめ上げていくと、どんなに長い文でも、最後の述語文節(例えば、「嫌い−です」)を根元とした一本の木のようになります。これを係り受け構造と言います。
そこからさらに、「意味解析」、「文脈解析」と進みます。英語圏で開発された優れたNLTKなどのソフトを日本語で利用しようとしても、単語区切りにスペースを設定しているため日本語では正常に動作しません。このような問題を解決するためにも、日本語の自然言語処理において、MeCabを用いた処理、単語を切り出す「形態素解析」は非常に重要な技術です。この形態素解析では、単語分割に加えて「品詞付与(pos tagging)」などの処理も同時に行っています。品詞付与とは、文章中の単語が名詞か動詞かといった品詞(part of speech, pos)に分類する処理です。この品詞情報を用いることで、単語分割処理の精度が高まり、文章中から名詞だけ取り出してキーワードにすることが出来ます。
parseToNode() メソッドを用いると、解析結果をノードの双方向連結リストとして受け取ることができます。また、 node.next と node.prev でノードを順方向または逆方向にたどることができます。ここで使用したmecab-python3はバージョンが0.7です。2018年11月13日にmecab-python3が0.996.1にバージョンアップしました。この時期以降のインストールでは、この最新のバージョンがインストールされます。mecab-python3=0.7をインストールするためには、
$ pip install mecab-python3=0.7
と打ってください。これがmecab-python向けのPyPiの公式サイトです。
Jupyter Notebookを開いて、以下のコードを実行してください。オプションの'-Ochasen' は出力の形式をChaSenと同じにするためです。ChaSen(茶筌)の説明については、この公式サイトを読んでください。
import MeCab
mecab = MeCab.Tagger('-Ochasen')
sentence ="気温が上がるとどうしても比例するのが電力使用量だ。9日は、全国の電力会社のうち8社の管内で、いずれも最大電力使用量が今夏最高を記録した。"
node = mecab.parseToNode(sentence)
node = node.next
while node:
print (node.surface, node.feature)
node = node.next
node.surface は単語そのもの、 node.feature は素性を文字列として表したものであり、この場合、素性は「品詞1, 品詞2, 品詞3, 品詞4, 活用型, 活用系, 活用形, 読み, 発音」という構造をしています。なお、このリストの先頭および末尾は、それぞれ BOS 、 EOS 、すなわち文頭、文末を示す特殊なノードになっています。この例では、先頭はスキップしているで、先頭のBOS, EOSは印字されていません。
気温 名詞,一般,*,*,*,*,気温,キオン,キオン が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 上がる 動詞,自立,*,*,五段・ラ行,基本形,上がる,アガル,アガル と 助詞,接続助詞,*,*,*,*,と,ト,ト どうしても 副詞,一般,*,*,*,*,どうしても,ドウシテモ,ドーシテモ 比例 名詞,サ変接続,*,*,*,*,比例,ヒレイ,ヒレイ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル の 名詞,非自立,一般,*,*,*,の,ノ,ノ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 電力 名詞,一般,*,*,*,*,電力,デンリョク,デンリョク 使用 名詞,サ変接続,*,*,*,*,使用,シヨウ,シヨー 量 名詞,接尾,一般,*,*,*,量,リョウ,リョウ だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ 。 記号,句点,*,*,*,*,。,。,。 9 名詞,数,*,*,*,*,9,キュウ,キュー 日 名詞,接尾,助数詞,*,*,*,日,ニチ,ニチ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 、 記号,読点,*,*,*,*,、,、,、 全国 名詞,一般,*,*,*,*,全国,ゼンコク,ゼンコク の 助詞,連体化,*,*,*,*,の,ノ,ノ 電力 名詞,一般,*,*,*,*,電力,デンリョク,デンリョク 会社 名詞,一般,*,*,*,*,会社,カイシャ,カイシャ の 助詞,連体化,*,*,*,*,の,ノ,ノ うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ 8 名詞,数,*,*,*,*,8,ハチ,ハチ 社 名詞,接尾,助数詞,*,*,*,社,シャ,シャ の 助詞,連体化,*,*,*,*,の,ノ,ノ 管内 名詞,一般,*,*,*,*,管内,カンナイ,カンナイ で 助詞,格助詞,一般,*,*,*,で,デ,デ 、 記号,読点,*,*,*,*,、,、,、 いずれ 名詞,代名詞,一般,*,*,*,いずれ,イズレ,イズレ も 助詞,係助詞,*,*,*,*,も,モ,モ 最大 名詞,一般,*,*,*,*,最大,サイダイ,サイダイ 電力 名詞,一般,*,*,*,*,電力,デンリョク,デンリョク 使用 名詞,サ変接続,*,*,*,*,使用,シヨウ,シヨー 量 名詞,接尾,一般,*,*,*,量,リョウ,リョウ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 今夏 名詞,副詞可能,*,*,*,*,今夏,コンカ,コンカ 最高 名詞,一般,*,*,*,*,最高,サイコウ,サイコー を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 記録 名詞,サ変接続,*,*,*,*,記録,キロク,キロク し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 。 記号,句点,*,*,*,*,。,。,。 BOS/EOS,*,*,*,*,*,*,*,*
上の例と類似の結果が表示されます。
この節の最後に、MeCabによる形態素解析結果をどのように出力できるかを取り上げてみます。青空文庫 から夏目漱石の 『こころ』 をダウンロードして、 kokoro.txt というテキストファイルで保存します。保存するディレクトリは'./corpora/'にしてください。コーディングがshift-jis形式なので、utf-8形式に変換して、最初の註釈の部分を削除しておいてください。以下のコードが実行用のスクリプトです。
MECAB_MODE = 'mecabrc' はMeCab のデフォルトの出力オプションです。node.feature部分のデータは「品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音」の構造になっていて、”,”で区切られているテキストデータのため","でsplitし、pos に配列として代入します。node.feature[0]なので、第1要素の品詞の具体名がposに入ります。
path = "./corpora/kokoro.txt"
bindata = open(path, "rb").read()
text = bindata.decode("utf-8")
import MeCab
MECAB_MODE = 'mecabrc'
tagger = MeCab.Tagger(MECAB_MODE)
tagger.parse("")
node = tagger.parseToNode(text)
words = []
nouns = []
verbs = []
adjs = []
while node:
pos = node.feature.split(",")[0]
word = node.surface
if pos == "名詞":
nouns.append(word)
elif pos == "動詞":
verbs.append(word)
elif pos == "形容詞":
adjs.append(word)
words.append(word)
node = node.next
words_dict = {
"text": words[1:-1], # 最初と最後には空文字列が入るので除去
"nouns": nouns,
"verbs": verbs,
"adjs": adjs
}
print ("文: \n", words[:80])
print ("名詞: \n", nouns[:50])
print ("動詞: \n", verbs[:50])
print ("形容詞: \n", adjs[:50])
このコードを実行すると、名詞、動詞、形容詞として特定された単語が表示されます。
文: ['', 'こころ', '夏目', '漱石', '\u3000', '私', '《', 'わたくし', '》', 'は', 'その', '人', 'を', '常に', '先生', 'と', '呼ん', 'で', 'い', 'た', '。', 'だから', 'ここ', 'でも', 'ただ', '先生', 'と', '書く', 'だけ', 'で', '本名', 'は', ・・・省略・・・ 'に', '、', 'すぐ', '「', '先生', '」', 'と', 'いい'] 名詞: ['こころ', '夏目', '漱石', '私', 'わたくし', '人', '先生', 'ここ', '先生', '本名', 'これ', '世間', '憚', 'ば', '遠慮', '方', '私', '自然', '私', '人', '記憶', 'ごと', '先生', '筆', '心持', '事', '頭文字', 'かしら', '気', '私', '先生', '知り合い', 'の', '鎌倉', 'かまくら', '時', '私', '書生', '暑中', '休暇', '利用', '海水浴', '友達', '端書', 'はがき', '私', '金', '工面', '事', '私'] 動詞: ['呼ん', 'い', '書く', '打ち明け', 'いう', '呼び', '起す', 'いい', 'なる', '執', '使う', 'なら', 'なっ', 'し', '行っ', '来い', '受け取っ', 'くめ', 'し', '出掛ける', 'し', 'ち', '費やし', '着い', '呼び寄せ', '帰れ', '受け取っ', '断っ', 'あっ', '信じ', 'かね', 'いる', 'し', 'いら', 'れ', 'い', 'いう', 'する', '過ぎ', '気に入ら', '帰る', '避け', '遊ん', 'い', '見せ', 'しよ', 'し', '分ら', 'すれ', '帰る'] 形容詞: ['かる', 'よそよそしい', '若々しい', 'ない', 'ない', '若', 'いい', '固', 'よし', 'よい', 'ない', '長い', '近い', '古い', 'くす', '黒い', '黒い', 'ない', '白い', 'ぽ', 'く', '長い', '小高い', '珍しく', 'とお', '小さく', 'おも', 'ない', '騒がしい', '浅い', '深', 'く', '有難う', '広い', 'なかっ', '強い', '強い', '快く', '長く', 'ない', '悪く', '広い', 'くちく', '若い', '暗', '濃', '物足りない', 'よく', '若かっ', '若い']
と表示されます。単語の分割(トークン化)と品詞の付与(タグ付け)が完了しています。
ここで、辞書を追加しておきましょう。mecab-ipadic-NEologd (Neologism dictionary for MeCab mecab-ipadic-NEologd)をインストールします。必須ではありませんが便利なので入れておきます。これはWeb上の新語をデフォルトの辞書に追加したものです。サイズは約800MBです。公式サイトはこのGitHubのRepoです。 (Google Colabでこの辞書を使用する方法が不明なので、Colabでのコードでは使用しません)以下のコマンドでインストールできます。
$ brew install git curl xz $ git clone https://github.com/neologd/mecab-ipadic-neologd.git $ cd mecab-ipadic-neologd $ ./bin/install-mecab-ipadic-neologd -n
MeCab.Taggerで指定するパスは
$ echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
で調べられます。以下のように辞書へのパスを指定します。
>>> mecab = MeCab.Tagger ('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
この辞書は、MeCab の標準のシステム辞書では正しく分割できない固有表現などの語の表層(表記)とフリガナの組を約309万組(重複エントリを含む)採録しています。Web上の言語資源を活用しているので、更新時に新しい固有表現を採録できます、などの特徴があります。利用すると便利です。
MeCab の辞書の指定は、ディレクトリ /usr/local/etc/ にある mecabrc ファイルで指定します。デフォルトでは、
; ; Configuration file of MeCab ; ; $Id: mecabrc.in,v 1.3 2006/05/29 15:36:08 taku-ku Exp $; ; dicdir = /usr/local/lib/mecab/dic/ipadic ; userdic = /home/foo/bar/user.dic ; output-format-type = wakati ; input-buffer-size = 8192 ; node-format = %m\n ; bos-format = %S\n ; eos-format = EOS\n
となっていますので、dicdir = /usr/local/lib/mecab/dic/mecab-ipadic-neologd とします。
Mecabの出力オプションに 'wakati' があります。このオプションで出力する分かち書きとは,上の例のように、詳細に品詞などの情報は必要なく, 単に文が形態素で区切られた形だけ欲しいという時に使えます。形態素が半角スペースで区切られた文が出力されます。トークン化されたテキストファイルが得られます。具体的には,実行時に”-Owakati”という出力形式のオプションを渡せばOKです。分かち書きしたファイルを作成・保存するときは、例えば、bocchan.txt の分かち書きファイルの場合、ターミナルから以下のコマンドを入力します。
(corpora) $ mecab -Owakati bocchan.txt -o bocchan_wakati.txt
bocchan.txt を分かち書きしたファイル bocchan_wakati.txt が作成・保存できます。
pythonで分かち書きしたファイルを作成するときは、以下のようにします。
path = "./corpora/bocchan.txt"
bindata = open(path, "rb").read()
raw = bindata.decode("utf-8")
import MeCab
tagger = MeCab.Tagger('-Owakati')
tagger.parse("")
text = tagger.parse(raw)
with open('./corpora/bocchan_wakati.txt', mode='w') as f:
f.write(text)
分かち書きファイルを作成する場合、python を利用する時の方がコードが複雑になります。
MeCab に類似した日本語の形態素解析器にJanomeと呼ばれるPythonの形態素解析エンジンがあります。MeCabと同じく、日本語のテキストを形態素ごとに分割して品詞を判定したり分かち書き(単語に分割)したりすることができます。Janome (蛇の目) は,Pure Python で書かれた,辞書内包の形態素解析器です。なので、MeCabなどの外部エンジンは必要なくpipでインストール可能です。
辞書,言語モデルともに MeCab のデフォルトシステム辞書をそのまま使っているので,MeCabと同等の解析結果になります。他方で、mecab-python の10倍程度(長い文章だとそれ以上)遅いという欠点があります。サイズの大きなコーパスを処理するケースでは、MeCab を利用した方がベターです。Janome に興味がある人は、公式サイトにアクセスしてください。
また、Juman という形態素解析エンジンも使用できます。JUMAN++は、京都大学黒橋・河原研究室から発表されたRNNを使用した形態素解析器で、MeCab と同程度以上の性能を持つと言われています。しかし、実行時間はMeCab に比較して数倍かかります。インストールにより大きなメモリサイズが必要です。JUMAN++のインストールには、 OS: Linuxで、メモリ: 4GB以上、ディスク: 2GB以上の空き容量が必要です。Mac OS では、homebrewから以下のコマンドでインストールすることができる。/usr/local/Cellar/の下にインストールされます。サイズは約2GBです。
$ brew install jumanpp
以下のように使用します。
$ echo "魅力がたっぷりと詰まっている" | jumanpp
結果は、
魅力 みりょく 魅力 名詞 6 普通名詞 1 * 0 * 0 "代表表記:魅力/みりょく カテゴリ:抽象物" が が が 助詞 9 格助詞 1 * 0 * 0 NIL たっぷり たっぷり たっぷりだ 形容詞 3 * 0 ナノ形容詞 22 語幹 1 "代表表記:たっぷりだ/たっぷりだ" と と と 助詞 9 格助詞 1 * 0 * 0 NIL 詰まって つまって 詰まる 動詞 2 * 0 子音動詞ラ行 10 タ系連用テ形 14 "代表表記:詰まる/つまる ドメイン:料理・食事 自他動詞:他:詰める/つめる" いる いる いる 接尾辞 14 動詞性接尾辞 7 母音動詞 1 基本形 2 "代表表記:いる/いる" EOS
となります。MeCab に比較して処理スピードが遅いです。JUMAN++の公式サイトはhttp://nlp.ist.i.kyoto-u.ac.jp/です。pythonバインディングのpyknp を利用するためには、さらに、KNPと呼ばれる追加パッケージをインストールする必要があります。KNPは日本語文の構文・格・照応解析を行うシステムです。形態素解析システムJUMANの解析結果(形態素列)を入力とし、文節および基本句間の係り受け関係、格関係、照応関係を出力します。公式サイトのrepository は、github.com/ku-nlp/pyknp です。Juman++ の使用法については、BERT を用いた日本語処理のページでも説明があります。
単語の分散表現とword2vecの仕組み |
自然言語をディープラーニングで扱う場合、何らかの方法で単語をベクトルデータに変換する必要があります。単語数が\( n \)の時、各単語を\( n \)次元実数空間の1点で表現することができます。単語を\( n \)個の実数の組に対応させることができないと、計算処理の話は始まらない。自然言語のベクトル化手法の中で一番単純なのが、one-hotベクトルへの変換です。単語の語彙数が\( n \)であるとき、各単語に\( 0 \)から\( n-1 \)までの番号を付けます。\( n \)次元ベクトルにおいて、番号\( i \)の単語には、次元\( i \)の値が1で、それ以外の次元の値が0のベクトルを作成します。1つの次元だけが1で他が0のため、one-hotベクトルと呼ばれます。こうすると、語彙の\( n \)次元空間への埋め込みが実現できます。これを実例を用いてみてみましょう。以下の例のコードは、このGoogle Colabで実行できます。
日本語のコーパスを準備しましょう。MeCab を用いて形態素解析を行い、トークン化されたテキストを作ります。
import MeCab
sentence = '私はワインを飲みますが、彼女はワインを飲みません。'
#分かち書き
tagger = MeCab.Tagger("-Owakati")
text = tagger.parse(sentence)
print(text, "\n")
以下のようにtext が作成されています。
text = '私 は ワイン を 飲み ます が 、 彼女 は ワイン を 飲み ませ ん 。 'ここで分かち書きされた text を単語ごとに分割します。句読点は無視するので、改行マークに置き換えます。
text = text.replace('。','\n')
text = text.replace('、','\n')
words =text.split(' ')
print (words)
このコードを実行すると、トークン化されたtext が作成されて、その内容は以下のように表示されます。
['私', 'は', 'ワイン', 'を', '飲み', 'ます', 'が', '\n', '彼女', 'は', 'ワイン', 'を', '飲み', 'ませ', 'ん', '\n', '\n']
各単語にインデックスを振って、単語とインデックスの対応表を作成します。このコードは、斉藤 康毅著『ゼロから作るDeep Learning 2(自然言語編)』に収録されたコードを修正したものです。
import numpy as np
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
print ('id_to_word \n', id_to_word)
print ('word_to_id \n', word_to_id)
print ('corpus \n',corpus)
単語とインデックスの対応とcorpus の中身は以下のようになっています。
id_to_word
{0: '私', 1: 'は', 2: 'ワイン', 3: 'を', 4: '飲み', 5: 'ます', 6: 'が', 7: '\n', 8: '彼女', 9: 'ませ', 10: 'ん'}
word_to_id
{'私': 0, 'は': 1, 'ワイン': 2, 'を': 3, '飲み': 4, 'ます': 5, 'が': 6, '\n': 7, '彼女': 8, 'ませ': 9, 'ん': 10}
corpus
[ 0 1 2 3 4 5 6 7 8 1 2 3 4 9 10 7 7]
この corpus をone-hot 表現するために、以下のコードを実行します。
vocab_size = len(word_to_id)
N = corpus.shape[0]
one_hot = np.zeros((N, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
one_hot[idx, word_id] = 1
print ('one-hot 表現 \n',one_hot)
以下の通りに表示されます。
one-hot 表現 [[1 0 0 0 0 0 0 0 0 0 0] [0 1 0 0 0 0 0 0 0 0 0] [0 0 1 0 0 0 0 0 0 0 0] [0 0 0 1 0 0 0 0 0 0 0] [0 0 0 0 1 0 0 0 0 0 0] [0 0 0 0 0 1 0 0 0 0 0] [0 0 0 0 0 0 1 0 0 0 0] [0 0 0 0 0 0 0 1 0 0 0] [0 0 0 0 0 0 0 0 1 0 0] [0 1 0 0 0 0 0 0 0 0 0] [0 0 1 0 0 0 0 0 0 0 0] [0 0 0 1 0 0 0 0 0 0 0] [0 0 0 0 1 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 1 0] [0 0 0 0 0 0 0 0 0 0 1] [0 0 0 0 0 0 0 1 0 0 0] [0 0 0 0 0 0 0 1 0 0 0]]
このようにして、各単語をone-hot ベクトルとするBOW(Bag-Of-Words)が作成されます。この例の場合、単語数は11個あるので、単語のベクトルは11次元のone-hot ベクトルとなります。11個の要素のうち一つの要素だけが1 で、それ以外の要素はすべてゼロとなるベクトルです。'\n' は句読点ですが、削除しなかったので残ってしまいました。
最近の単語のベクトル化に関する手法は、単語の意味は周囲の単語によって形成されるという分布仮説を基礎としています。単語の意味は隣接する単語群の文脈(コンテキスト)に依存するという原則です。各単語の類似度などを考慮するためには、各単語がどの単語と隣接して使用されているのかのデータ(共起行列と言います)を作成する必要が出てきます。このデータは語彙数x語彙数の行列で表現されることになります。語彙数は単語数のことなので、上の単純なケースでも11x11行列の計算が必要となります。語彙数が10万となれば、10万次元のベクトルの計算が生じてきます。
この手法ではコーパスの語彙数が巨大になると、必然的に行列の要素数も巨大なものになります。ネットワークモデルでの訓練や予測が複雑になり、必要とされる計算時間も長くなるので、入力次元を減らしたいという要請がおきます。例え、語彙数が10000であっても、100次元空間に単語を埋め込めれば、ネットワークモデルへの入力次元数も削減され、学習が短時間で可能になります。この場合、ベクトルの要素の値は各単語の関係を考慮しながら決められることになり、当然ながらone-hotベクトルでは無くなります。
このような「単語の埋め込み」は文脈から形成される意味を幾何学的空間にマップすることを意図した自然言語処理技術の一つで、任意の 2 つのベクトルの間の距離 (コサイン類似度と言います) が 2 つの関連単語の間の意味関係を部分的に捕捉するように、数値ベクトルを辞書の総ての単語に関連付けることにより遂行されます。これらのベクトルで形成される幾何学的空間は 埋め込み空間と呼ばれます。
喩えで説明するならば、”りんご” と “ネコ” は、通常、文脈で隣接する単語ではないので、意味的に非常に異なる単語ですから合理的な埋め込み空間であればそれらを非常に遠く離れたベクトルとして表現するでしょう。けれども “ベッド” と “寝室” は隣接して使用される頻度が高い関連単語なので、それらは互いに近く埋め込まれるはずです。
word2vec は、コーパスの単語間の共起統計情報のデータセットをもとに次元削減技術を適用することで「単語の埋め込み(embedding)」を実現します。このような自然言語のベクトル化手法を用いたword2vecは、単語間の関連性を、対応するベクトル間演算(足し引き)で表現できるようにします。例えば、
king - man + woman = queenが成り立つように単語の埋め込みベクトルを決定するものです。
word2vecはこのように、語彙数より少ない次元embedding数のベクトル化手法を採用しています。その特徴は、単語間の関連性をベクトル表現に反映しているところですが、その手法には、CBOW(Continuous Bag-of-Words Model)とContinuous Skip-gram Model(以下、skip-gramと表記)の2種類があります。この両者ともに、埋め込みベクトルの作成するための学習に3層(一つの隠れ層を持つ)ニューラルネットワークを使います。
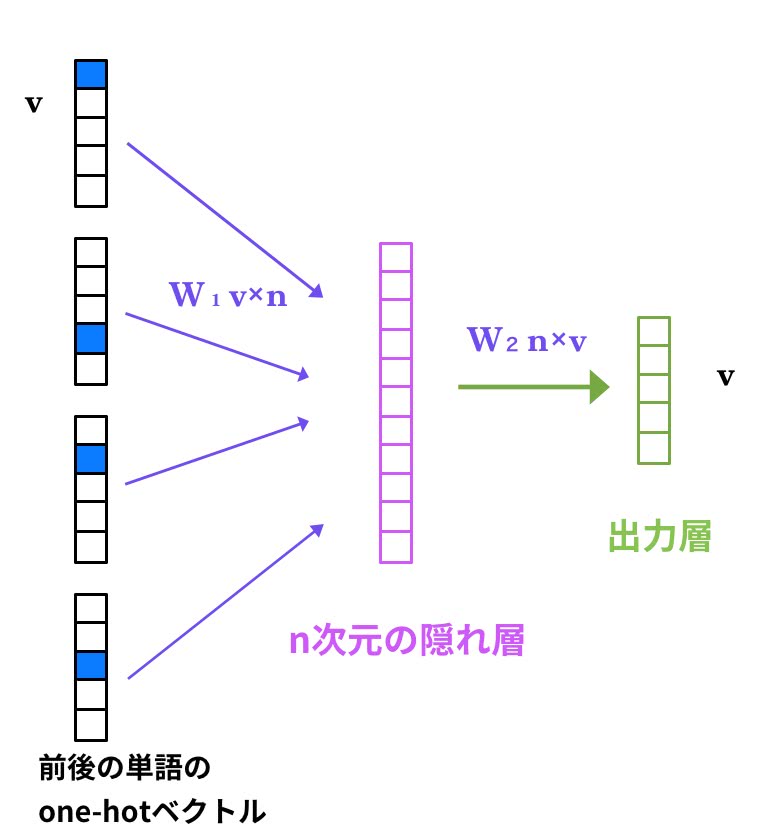
最初に、CBOW モデルについて説明します。入力層のニューロン数はone-hot 形式の単語ベクトル(周辺単語群、コンテキストとも言われます)の次元数となり、隠れ層のニューロン数は任意です。出力層のニューロン数はone-hot 形式の単語ベクトルの次元数となります。下の図はターゲット単語の隣接単語数(コンテキスト数) が 2 のケースです。予測したい単語(ターゲット)の前後の2つの単語(合計4個の単語)を入力して、その単語間に生起する単語を予測します。コンテキスト数が3のケースでは、ターゲットに隣接する前後各3個の単語を入力して、その単語間に入る単語を予測します。
各単語は\( v \)次元のone-hot ベクトルで、隠れ層のニューロン数は\( n \)です。したがって、入力層の重み行列\( W_1 \)は\( v \times n \)マトリックスです。隠れ層からの出力は入力信号の単語ベクトルと重み行列\( W_1 \)の積となっています。バイアス項はありません。入力単語数が複数あるので、その値は平均値を採用します。4つの単語ベクトルが
\[ w_1, w_2, w_3, w_4 \]であるとき、
\[ h = \frac{w_1\cdot W_1 + w_2 \cdot W_1 + w_3 \cdot W_1 + w_4 \cdot W_1}{4} \]と計算されます。この隠れ層のニューロンに対応するベクトル\( h \)の次元は\( n \)となっています。実は、入力単語がone-hot 表現になっているので、重み行列\( W_1 \)の各行が各単語の埋め込みベクトルとなります。
出力層への重み行列\( W_2 \)は\( n \times v \) です。出力層からの出力信号\( s \)は、\( s = h \cdot W_2 \)と計算されるので、\( v \)次元のベクトルとなります。文章中の単語(教師ラベル)と予測した単語\( s \)が一致するように重み行列を学習します。出力層にはSigmoid 関数を用い、損失関数には交差エントロピー誤差が用いられます。sklearn や Tensorflowなどのpython ライブラリを使用しないCBOWのpure python での実装コードについての説明は、斉藤 康毅著『ゼロから作るDeep Learning 2(自然言語編)』に詳しく書かれています。
終わりに、skip-gram モデルについて説明します。skip-gram は、CBOW のコンテクストとターゲット(教師ラベル)を逆転させたものと言えます。以下のグラフはskip-gramモデルを簡潔に説明するものです。
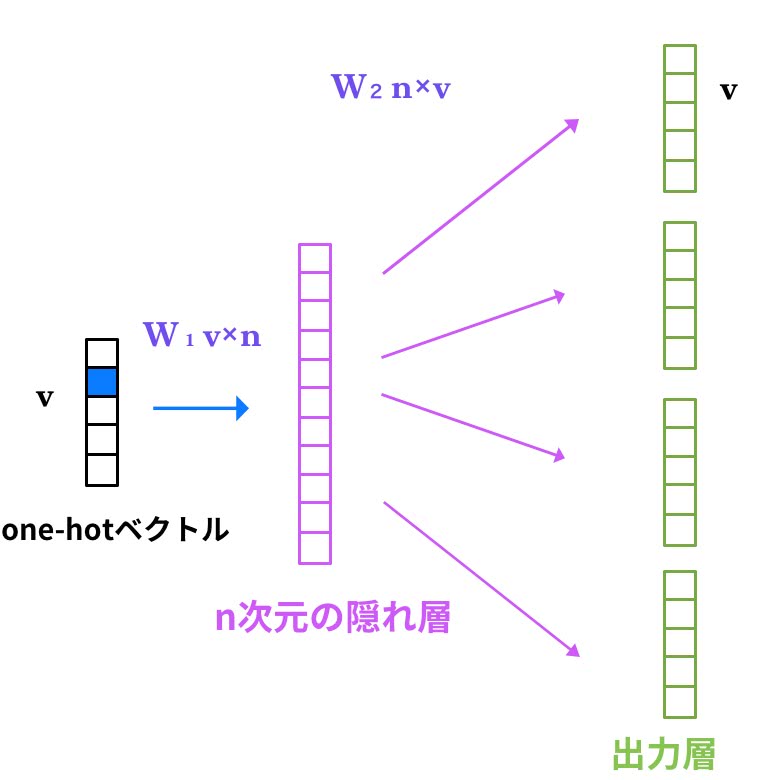
単語をone-hot ベクトルとして入力層に入ると、隠れ層を介して、この単語を挟んで共起する単語群の予測が出力層に出力されます。この出力値と文章中にこの単語の前後に並んでいる複数単語を教師ラベルとして用いて、損失を最小にするように重み行列の学習を行います。出力層にはsoftmax関数を用い、損失関数には交差エントロピー誤差が用いられます。この学習の結果、学習された重み行列を用いて各単語の埋め込みができるようになります。skip-gram の易しい解説は、このサイトに(英文です)あります。
ここで説明した仕組みをpython コードに実装すれば単語ベクトルの分散表現を作成することができますが、このままでは、上で指摘した計算量や計算速度に関わる問題点を抱えたままになります。word2vec の実装においては、Embedding層の導入やnegative sampling と呼ばれる手法が導入されるなどの改良が行われています。詳しい説明については、 解説論文 'word2vec Parameter Learning Explained' を参照ください。
MeCabとGensimを用いた自然言語分析 |
Gensimは、2008年にCzech Digital Mathematics Libraryで開発が始められた、様々なトピックモデルを実装したPythonライブラリです。公式サイトで「topic modelling for humans」とあるように、実装が大変なトピックモデルを簡単に使うことができます。NLTK に比較して簡単にトピック分析ができることから、最近では(2010年以降)活用が急速に拡大しています。
LSI(Latent Semantic Indexing、LDA(Latent Dirichlet Allocation)、DTM(Dynamic Topic Modeling)などのトピックモデルのみならず、 tf-idf, random projections, word2vecのようなアルゴリズムも実装して、使うことができます。
gensimをインストールするために、以下のコマンドを使いましょう。
$ conda install gensim
インストールを確認するために、python を起動して、
>>> from gensim.models import word2vec
と入力して、エラーがなければOKです。
とりあえず、gensim の基本的使用法についてのみ説明します。以下の説明されるコードは、Google Colabで実行できます。jupyter notebook を開いてください。gensim を使用するときは、初めに必ず以下のように打ちます。
import logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
これは処理のログ情報を表示させるためです。以下のコードは作成した辞書を臨時に保存するためのものです。
import os
import tempfile
TEMP_FOLDER = tempfile.gettempdir()
print('Folder "{}" will be used to save temporary dictionary and corpus.'.format(TEMP_FOLDER))
次に、ドキュメントを定義し、トークン化します。
from gensim import corpora
documents = ["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey"]
# remove common words and tokenize
stoplist = set('for a of the and to in'.split())
texts = [[word for word in document.lower().split() if word not in stoplist]
for document in documents]
# remove words that appear only once
from collections import defaultdict
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
texts = [[token for token in text if frequency[token] > 1] for text in texts]
from pprint import pprint # pretty-printer
pprint(texts)
stoplist = set('for a of the and to in'.split()) はテキストから削除するべき冠詞や前置詞などのリストを作成しています。texts = [[word for word in document.lower().split() if word not in stoplist] for document in documents] は for 文の内包表記で、メソッドsplit() で単語の分割を行なっています。メソッド lower() は単語を小文字にしています。
上のコードで、見たことのないdefaultdict が使用されています。このdefaultdict の引数には、「初期化時に実行する関数」を記述します。ここでは、「int」と記述しています。これは「lambda: int()」と同じ意味で、「int()」 は 「0」を返しますので、「lambda: 0」と同じ動作になります。つまり「0を返す関数」になります。初期値が 0 になります。frequency = defaultdict(int) は、dict の初期化をするために使用します。そのため存在チェックが不要です。dict は「key: value」の組を保持する型です。
texts = [[token for token in text ] for text in texts] も、for 文の内包表記です。このコードを実行するとトークン化されたテキストが以下のように表示されます。
[['human', 'interface', 'computer'], ['survey', 'user', 'computer', 'system', 'response', 'time'], ['eps', 'user', 'interface', 'system'], ['system', 'human', 'system', 'eps'], ['user', 'response', 'time'], ['trees'], ['graph', 'trees'], ['graph', 'minors', 'trees'], ['graph', 'minors', 'survey']]
次に、corpora.Dictionary(texts) を用いて、トークン化された texts の辞書を「key: value」の組で作成し、この辞書を臨時に保存します。
dictionary = corpora.Dictionary(texts) dictionary.save(os.path.join(TEMP_FOLDER, 'deerwester.dict')) # store the dictionary, for future reference print(dictionary) print(dictionary.token2id)
辞書の内容が以下のように表示されます。
Dictionary(12 unique tokens: ['computer', 'human', 'interface', 'response', 'survey']...)
{'computer': 0, 'human': 1, 'interface': 2, 'response': 3, 'survey': 4, 'system': 5, 'time': 6, 'user': 7, 'eps': 8, 'trees': 9, 'graph': 10, 'minors': 11}
各単語が整数のインデックスに対応しています。ドキュメントに対応するMmcorpus のインデックスを作成し、保存するために、以下のコードを打ちます。
corpus = [dictionary.doc2bow(text) for text in texts]
corpora.MmCorpus.serialize(os.path.join(TEMP_FOLDER, 'deerwester.mm'), corpus) # store to disk, for later use
for c in corpus:
print(c)
corpus の中身を表示させると、
[(0, 1), (1, 1), (2, 1)] [(0, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1)] [(2, 1), (5, 1), (7, 1), (8, 1)] [(1, 1), (5, 2), (8, 1)] [(3, 1), (6, 1), (7, 1)] [(9, 1)] [(9, 1), (10, 1)] [(9, 1), (10, 1), (11, 1)] [(4, 1), (10, 1), (11, 1)]
となっていることが確認できます。これは BOW(Bag Of Words) と呼ばれています。各単語(インデックス)が各センテンスで何回使用されているかを表示しています。例えば、最初のセンテンスでは、'computer': 0が1回、'human': 1が1回、'interface': 2が1回使用されていることを意味します。
この後、word2vec モジュールを用いて、単語の分散表現をする手続きに入ります。単語の分散表現の仕組みについては、前の項目で詳細に説明しました。ここでは、python に実装されたモジュールを援用します。以下のword2vec モジュール、
class gensim.models.word2vec.LineSentence(source, max_sentence_length=10000, limit=None) class gensim.models.word2vec.Text8Corpus(fname, max_sentence_length=10000) class gensim.models.word2vec.Word2Vec(sentences, window=5, min_count=5, sample=0.001, seed=1, workers=3, sg=0, hs=0, negative=5, iter=5)を使用しましょう。この詳しい説明は、Gensimの公式ホームページを参照ください。
日本語処理の最初の例として、「livedoorニュース」を使用します。日本語コーパスとして「livedoor ニュースコーパス」を この(https://www.rondhuit.com/download.html#ldcc)サイトからダウンロードします。サイズは約65MBです。ダウンロードしたファイルを展開し、文字コーディングがutf-8 であることを確認します。以下で使用するスクリプトと同じディレクトリに移動・保存してください。
WikipediaのデータもWikipediaのデータベースダウンロードからダウンロードすることができます。見出し語のリストや本文も含めた全データもダウンロードできます。ただし、全体で2.7GBあります。このデータベースでは、データはXMLのデータ形式で提供されます。文字エンコーディングはUTF-8です。
「livedoorニュース」をMeCab を用いてトークン化をします。jupyter notebook を開いて、以下のコードをコピペしてください。livedoor-news-dataのtopic-news.xml を読み込みます。ここで使用するコードは、このGoogle Colabで実行できます。このColab のコードでは、mecab-ipadic-neologd は使用しません。 mecab-ipadic-neologd を利用したコードはこちらのGoogle Colabです。
import MeCab
tagger = MeCab.Tagger('-F\s%f[6] -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
raw = open('livedoor-news-data/topic-news.xml', 'r')
text = open('livedoor-news-data/topic-news_text.xml', 'w')
line = raw.readline()
while line:
result = tagger.parse(line)
text.write(result[1:]) # skip first \s
line = raw.readline()
raw.close()
text.close()
tagger = MeCab.Tagger('-F\s%f[6] -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
で、 'F\..' は Node の出力モードを指定するオプションです。
'-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd'
は辞書を 'mecab-ipadic-neologd' にするというオプションです。この指定を外すとき、辞書のデフォルトは、'mecab-ipadic' です。
'topic-news.xml' を読み込んで、このファイルをMeCab.Tagger を用いてトークン化したtextを 'topic-news_text.xml' として保存しています。このコードを実行します。
次に、gensim の word2vec を用いてtextをベクトル化します。以下のコードをコピペしてください。
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.LineSentence('livedoor-news-data/topic-news_text.xml')
model = word2vec.Word2Vec(sentences,
sg=1,
size=100,
min_count=1,
window=10,
hs=1,
negative=0)
model.save('livedoor-news-data/topic-news.model')
トークン化されたファイル 'livedoor-news-data/topic-news_text.xml'を読み込んで処理するプロセスが表示されます。
2018-10-21 10:08:23,753 : INFO : collecting all words and their counts 2018-10-21 10:08:23,757 : INFO : PROGRESS: at sentence #0, processed 0 words, keeping 0 word types 2018-10-21 10:08:23,932 : INFO : PROGRESS: at sentence #10000, processed 288617 words, keeping 13192 word types 2018-10-21 10:08:24,047 : INFO : collected 17719 word types from a corpus of 499898 raw words and 16734 sentences 2018-10-21 10:08:24,050 : INFO : Loading a fresh vocabulary . . . 2018-10-21 10:08:39,575 : INFO : training on a 2499490 raw words (1451254 effective words) took 14.0s, 103868 effective words/s 2018-10-21 10:08:39,590 : INFO : saving Word2Vec object under livedoor-news-data/topic-news.model, separately None 2018-10-21 10:08:39,592 : INFO : not storing attribute vectors_norm 2018-10-21 10:08:39,595 : INFO : not storing attribute cum_table 2018-10-21 10:08:40,142 : INFO : saved livedoor-news-data/topic-news.model
最後の処理はベクトル化したファイル'topic-news.model'を作成して、保存することです。 「livedoorニュース」の中から、アイドルグループの「AKB」に関する関係単語を探しましょう。
model = word2vec.Word2Vec.load('livedoor-news-data/topic-news.model')
model.wv.most_similar(positive=['AKB'],topn=20)
これを実行すると、
[('高橋', 0.69325190782547),
('口パク', 0.6708778142929077),
('口移し', 0.6658689975738525),
('AKB48', 0.6646750569343567),
('AKBメンバー', 0.6625093817710876),
('前田敦子', 0.6575405597686768),
('篠田', 0.6357671022415161),
('前田', 0.6243596076965332),
('プレッシャー', 0.6131542921066284),
('集中砲火', 0.6129703521728516),
('板野友美', 0.6034805178642273),
('高橋みなみ', 0.5957424640655518),
('総選挙', 0.5937471389770508),
('気まずい', 0.5899049639701843),
('指原', 0.5874552726745605),
('未定', 0.5818403959274292),
('悪寒', 0.5814628601074219),
('秋元康', 0.5806461572647095),
('大量購入', 0.5775288343429565),
('ドン引き', 0.5770188570022583)]
となります。右側の数値はコサイン類似度です。どうでしょうか、心当たりがあるでしょうか?
次に、青空文庫からダウンロードした夏目漱石の『こころ』を使って、トピック分析をしてみましょう。以下のコードを準備してください。ここでの分析と同じ結果を表示させるスクリプトが このサイトにありますが、ここで使用するコードに比較して複雑です。jupyter notebook を開き、以下をコピペして、実行してください。ディレクトリ corpora にトークン化された新しいファイル 'kokoro_txt.txt' が作成されていることが確認できます。さらに、ベクトル化されたファイル kokoro_txt.model も保存されていることもわかります。
import MeCab
tagger = MeCab.Tagger('-F\s%f[6] -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
raw = open('corpora/kokoro.txt', 'r')
text = open('corpora/kokoro_txt.txt', 'w')
line = raw.readline()
while line:
result = tagger.parse(line)
text.write(result[1:]) # skip first \s
line = raw.readline()
raw.close()
text.close()
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.LineSentence('corpora/kokoro_txt.txt')
model = word2vec.Word2Vec(sentences,
sg=1,
size=100,
min_count=1,
window=10,
hs=1,
negative=0)
model.save('corpora/kokoro_txt.model')
model.wv.most_similar(positive=['人間'],topn=20)
小説『こころ』の文章の中で、「人間」という単語と最も近い単語は以下のようになりました。
[('若い', 0.8065819144248962),
('それほど', 0.7739325761795044),
('変化', 0.7653369307518005),
('不自然', 0.7633599042892456),
('すでに', 0.7619006633758545),
('馬鹿', 0.7609981298446655),
('憎む', 0.7591098546981812),
('信用', 0.7570350170135498),
('世間', 0.7522665858268738),
('最後の一句', 0.7497682571411133),
('幸福', 0.7493448853492737),
('淋しい', 0.7475141286849976),
('鋳型', 0.7450391054153442),
('それだけ', 0.7416242361068726),
('違い', 0.7404665946960449),
('生きる', 0.7300416231155396),
('好く', 0.7284690141677856),
('どんなに', 0.7284088134765625),
('事実', 0.7272292375564575),
('生れる', 0.7247858047485352)]
「人間」という単語が、この小説の中でどのような単語と密接に関係づけられて、描かれているかがわかります。青空文庫から様々な小説をダウンロードして、ダウンロードした書籍に対応して'kokoro.txt' の部分を修正すれば、このスクリプトを使って同様な検索ができます
少し異なったスクリプトを使ったトピック分析を取り上げておきます。青空文庫からダウンロードして、コーディングをutf-8 に変換した宮沢賢治の『銀河鉄道の夜』(gingatetsudono_yoru.txt)を使用しました。以下のスクリプトをコピペしてください。
# tokenizing the documents
import MeCab
file_dir="../corpora/gingatetsudono_yoru.txt"
dic_dir="/usr/local/lib/mecab/dic/mecab-ipadic-neologd"
hinshis=["動詞", "形容詞", "形容動詞", "助動詞"]
tagger = MeCab.Tagger("mecabrc -d {}".format(dic_dir))
f = open(file_dir, "r")
line = f.readline()
splited_text = []
while line:
node = tagger.parseToNode(line).next
splited_line = []
while node.surface:
word = node.surface
feature = node.feature.split(',')
hinshi = feature[0]
kata = feature[5]
genkei = feature[6]
if hinshi in hinshis:
if kata != "基本形":
word = genkei
splited_line.append(word)
node = node.next
splited_text.append(splited_line)
line = f.readline()
assert splited_text is not None
fout = open('out.txt', 'w')
for line in splited_text:
fout.write(" ".join(line) + " ")
fout.close()
#vectorizing the text
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('out.txt')
model = word2vec.Word2Vec(sentences, sg=1, size=300, min_count=10, window=5, hs=0, negative=15, iter=15)
#model.save('ginga.model')
model.wv.most_similar(positive="川", topn=20)
この小説の中で、'川'と最も近い距離で使用された単語は以下の通りです。
[('天の川', 0.8907685279846191),
('汽車', 0.8846088647842407),
('音', 0.875632643699646),
('かたち', 0.8752759099006653),
('青い', 0.8708826899528503),
('水', 0.8689214587211609),
('野原', 0.8675404787063599),
('しずか', 0.8642644882202148),
('小さい', 0.8602733612060547),
('星', 0.8529857397079468),
('なか', 0.8515026569366455),
('流る', 0.845703125),
('遠く', 0.8454068899154663),
('青じろい', 0.8423873782157898),
('あかり', 0.8423855304718018),
('いく', 0.8410260677337646),
('ば', 0.8409186601638794),
('間', 0.8370413780212402),
('火', 0.8357046842575073),
('ぶん', 0.8324414491653442)]
宮沢賢治の川のイメージが掴めたでしょうか。
テキストマイニングの課題の一つに文書のクラス分け、文書の類似度の推測問題があります。文書のクラス分けを行うためには、文書の中にある文章をベクトル化する必要があります。Gensimでは、文章のベクトル化の手法は doc2vec と呼ばれるアルゴリズムで実現されます。doc2vec アルゴリズムを用いた例を見てみましょう。
livedoor-newsの記事を今回の実験用に成形します。このlivedoor ニュースコーパスから 'ldcc-20140209.tar.gz'の方をダウンロードします。これを解凍して、 /livedoor-text/ ディレクトリ配下に移動します。txtファイルになっています。なお、 LICENSE.txt など利用しないテキストファイルはあらかじめ削除しておきます。ここでの課題にはクラス分けは必要ないのですが、このサイトでの説明を参考にしてコードを活用するので、以下のようなスクリプトを作成します。jupyter notebookのセルにコピペしてください。このコードは、このGoogle Colabで実行できます。
import pandas as pd
import glob
import os
classes = ["dokujo-tsushin","it-life-hack","kaden-channel","livedoor-homme",
"movie-enter","peachy","smax","sports-watch","topic-news"]
df_texts = pd.DataFrame(columns=['class','body'])
if __name__ == '__main__':
# テキストの抽出
for c in classes:
filepath = './livedoor-text/' + c + '/*.txt'
files = glob.glob(filepath)
for i in files:
f = open(i)
text = f.read()
text = text.replace("\u3000","")
f.close()
row = pd.Series([c, "".join(text.split("\n")[3:])], index=df_texts.columns)
df_texts = df_texts.append(row, ignore_index=True)
# テキストの保存
df_texts.to_csv('datasets/dataset_train.csv')
このコードはlivedoor_text 文書をクラス分けして df_texts (DataFrame 形式で)の中に納めています。このファイルは'class' と’body'という名前の列を持っています。'class' には classes の名前が入ります。'body' に、文章が入ります。csv 形式で保存します。このファイルの内容を知りたいときは、例えば、200行から210行前の内容を表示させたいときは 'print (df_texts[200:211])'と入力します。
文章を単語に分かち書きするにはMeCabを使います。特徴を拾いやすくするために名詞だけ抽出してみることにしました。係り受けなどは考慮しないので、形容詞、副詞、動詞などは含めていません。辞書は neologd を使っています。
import sys
import MeCab
import unicodedata
class mecab_split():
""" mecabで分かち書きなどを行う処理まとめ """
def __init__(self):
pass
@staticmethod
def split(text):
#文字コード変換処理。変換しないと濁点と半濁点が分離する。
text = unicodedata.normalize('NFC', text)
result = []
tagger = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
tagger.parse('') #parseToNode前に一度parseしておくとsurfaceの読み取りエラーを回避できる
nodes = tagger.parseToNode(text)
while nodes:
if nodes.feature.split(',')[0] in ['名詞']:
word = nodes.surface
result.append(word)
nodes = nodes.next
return ' '.join(result)
このスクリプトでは、@staticmethod を使用していますので、これを削除しないでください。
次に、Doc2Vec でモデルの作成を行います。gensim ライブラリに Doc2Vec が実装されているので、それを使います。 オプションで、dmpv を用います。 この手法で学習させる際には文書idをタグとして持つので、以下のように書きます。
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
sys.path.append(os.pardir)
ms = mecab_split()
trainings = [TaggedDocument(words = ms.split(body), tags = [i])
for i, body in enumerate(df_texts['body'])]
モデルの学習を行うために、以下のコードを作成します。
# モデルの学習, dmpvで学習させる
model = Doc2Vec(documents=trainings, dm=1, size=300, window=5, min_count=5)
# モデルの保存
model.save('datasets/doc2vec.model')
このモデルを用いて、df_textsの500番目の文書ともっとも類似した内容の文書番号を探します。
m=model m.docvecs.most_similar(500)
以下のように表示されます。
[(241, 0.6817468404769897), (626, 0.6597436666488647), (1587, 0.6563264727592468), (2243, 0.65325927734375), (3436, 0.6528447270393372), (2740, 0.6480965614318848), (4061, 0.6463764309883118), (1958, 0.6454359889030457), (2442, 0.6441898941993713), (1527, 0.6411210298538208)]
もっとも類似していると判断された文書の内容をみてみましょう。
print (df_texts[500:501]) print (df_texts[626:627]) print (df_texts[241:242])
どうでしょうか?納得できるでしょうか。下に別な例を示します。
#例えば、以下の4つの新規文書の、いくつかの組み合わせの類似度を計算してみる
doc_words1 = ["ラスト", "展開" ,"早い" ,"他" ,"作品", "衝撃", "受ける" ,"裏の裏" ,"つく", "トリック" ,"毎度" ,"こと", "脱帽", "する", "読む", "やすい" ,"め" ,"ミステリー"]
doc_words2 = [ "イニシエーション・ラブ", "同様" ,"最後", "数行", "どんでん返し", "いく", "時", "時", "様々", "シーン", "する" ,"れる", "伏線" ,"散りばめる", "られる" ,"いる", "こと", "気づく"]
doc_words3 = ["ラスト", "展開" ,"早い" ,"他" ,"作品", "衝撃", "受ける" ,"裏の裏" ,"つく","ミステリー"]
doc_words4 = ["独特", "世界観", "日常" ,"離れる","落ち着く","時","読む","本"]
print ("1-2 similarity")
sim_value = m.docvecs.similarity_unseen_docs(m, doc_words1, doc_words2, alpha=1, min_alpha=0.0001, steps=5)
print (sim_value)
print ("1-3 sim")
print (m.docvecs.similarity_unseen_docs(m, doc_words1, doc_words3, alpha=1, min_alpha=0.0001, steps=5))
print ("1-4 sim")
print (m.docvecs.similarity_unseen_docs(m, doc_words1, doc_words4, alpha=1, min_alpha=0.0001, steps=5))
print ("2-3 sim")
print (m.docvecs.similarity_unseen_docs(m, doc_words2, doc_words3, alpha=1, min_alpha=0.0001, steps=5))
この結果はどうなりますか?皆さんで検討してください。
fastText を活用したテキスト分類 |
チャットボットは「対話(chat)」する「ロボット(bot)」という2つの言葉を組み合わせたもので、 ユーザーと企業をつなぐコミュニケーション・ツールとして、開発が続いています。チャットボットは人間が入力する テキストや音声に対して、自動的に回答を行うことで、これまで人間が対応していた「お問い合わせ対応」「注文対応」などの作業を代行することができます。チャットボットやスマホの応答システムに「今日の夜8時頃ピザを1枚持ってきてくれる?」と聞くだけで、質問に答えてくれます。質疑応答システムやLINEやFacebookで盛んに開発が進むチャットボットにもWord2Vecは利用可能です。実際に、Googleで開発されたword2vec を拡張したfastText というライブラリがFacebookから公開されています。
fastText のインストールは以下の通りです。git cloneして、makeしてインストールする
$ git clone https://github.com/facebookresearch/fastText.git $ cd fastText/ $ make
エラーが出たりしなければ、以下のようにpipでインストールします。
$ pip install cython $ pip install fasttext
>>> import fasttext as ft
(fastText)$ ./fasttext
usage: fasttextThe commands supported by fasttext are: supervised train a supervised classifier quantize quantize a model to reduce the memory usage test evaluate a supervised classifier test-label print labels with precision and recall scores predict predict most likely labels predict-prob predict most likely labels with probabilities skipgram train a skipgram model cbow train a cbow model print-word-vectors print word vectors given a trained model print-sentence-vectors print sentence vectors given a trained model print-ngrams print ngrams given a trained model and word nn query for nearest neighbors analogies query for analogies dump dump arguments,dictionary,input/output vectors
よく使用されるコマンドは、supervised, test, predict, skipgram などです。これらのコマンドは、例えば、ファイル data.txt のテキストをベクトル化し、そのファイルを modelという名前で作成するとき、
(fastText) $ ./fasttext skipgram -input data.txt -output model
と入力します。wikipediaのデータを使用して実際に処理しましょう。
fastText $ mkdir data fastText $ wget -c http://mattmahoney.net/dc/enwik9.zip -P data --2020-01-02 13:11:12-- http://mattmahoney.net/dc/enwik9.zip mattmahoney.net (mattmahoney.net) をDNSに問いあわせています... 67.195.197.75 mattmahoney.net (mattmahoney.net)|67.195.197.75|:80 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 322592222 (308M) [application/zip] `data/enwik9.zip' に保存中 enwik9.zip 5%[> ] 16.63M 335KB/s 残り14m 39s ^C
15分程度かかりますが、これでenwiki9のデータがダウンロードされました。解凍・展開して、fastTextフォルダーのdataに保存して下さい。サイズは1G程度あります。これをfasttextで読み込めるように処理をします。
fastText $ perl wikifil.pl data/enwik9 > data/fil9
skipgram形式のモデルと単語辞書を作成します。
fastText $ mkdir result fastText $ ./fasttext skipgram -input data/fil9 -output result/fil9 Read 124M words Number of words: 218316 Number of labels: 0 Progress: 0.0% words/sec/thread: 17386 lr: 0.049995 avg.loss: 4.117098 ETAProgress: 0.0% words/sec/thread: 17799 lr: 0.049993 avg. ....
45分程度かかります。気長に待ちましょう。resultフォルダーに、fil9.bin、fil9.vec が作成されています。以下のようなっています。
$ ls -l result total 2328520 -rw-r--r-- 1 koichi staff 978480868 1 2 14:08 fil9.bin -rw-r--r-- 1 koichi staff 190674238 1 2 14:08 fil9.vec
fil9.vecが単語の辞書です。中身を見てみましょう。
$ head -n 4 result/fil9.vec 218316 100 the -0.10363 -0.063669 0.032436 -0.040798 0.53749 0.00097867 0.10083 0.24829 ... of -0.0083724 0.0059414 -0.046618 -0.072735 0.83007 0.038895 -0.13634 0.60063 ... one 0.32731 0.044409 -0.46484 0.14716 0.7431 0.24684 -0.11301 0.51721 0.73262 ...
218316は単語の数で、100はベクトルの次数です。単語のベクトル表示を見てみましょう。
$ echo "asparagus pidgey yellow" | ./fasttext print-word-vectors result/fil9.bin asparagus 0.46826 -0.20187 -0.29122 -0.17918 0.31289 -0.31679 0.17828 -0.04418 ... pidgey -0.16065 -0.45867 0.10565 0.036952 -0.11482 0.030053 0.12115 0.39725 ... yellow -0.39965 -0.41068 0.067086 -0.034611 0.15246 -0.12208 -0.040719 -0.30155 ...類似の単語(nearest neighbor)を探すために、以下のコマンドを入力します。
$ ./fasttext nn result/fil9.bin Query word?
と聞いてくるので、好きな単語(例えば、asparagus)を入力します。類似の単語が表示されます。単語間のアナロジーを見るためには、以下のコマンドを打ちます。
$ ./fasttext analogies result/fil9.bin Query triplet (A - B + C)? berlin germany france
と入力すると、paris 0.898863 ... が返されるはずです。
ここで処理の対象となるファイル(上ではdata.txt)に関して注意が必要です。トークン化された複数のテキストファイルは1つのテキストファイルにまとめる必要があります。例えば、前のページでダウンロードした「livedoor-news」をそのままの形では利用できません。一つのテキストファイルに結合する必要があります。
日本語は英語のようにスペースで単語が区切れていないため、分かち書きという処理をして単語ごとに切り出して行く必要があります。この作業に、MeCabを利用します。今回は単純に分かち書きをするだけで形態素の情報は必要ないので、以下のコマンドで処理します。
$ mecab -Owakati (対象テキストファイル) -o (出力先ファイル)
例えば、bocchan.txt の分かち書きファイルの場合、(単語が半角スペースでトークン化した)分かち書きしたファイルを作成・保存するときは、以下のコマンドを入力します。青空文庫からダウンロードしたbocchan.txt が保存されているディレクトリに移動して、
(corpora) $ mecab -Owakati bocchan.txt -o bocchan_wakati.txt
とします。bocchan.txt を分かち書きしたファイル bocchan_wakati.txt が作成できます。mecab-neologdを利用するとより現代的な単語も認識して分かち書きすることできるので、必要に応じて活用してください。ここでは、デフォルトの辞書を使っています。
次に、fastText を用いてテキストの分類をするために、テキストをベクトル化します。この作業をターミナルから実行する場合には、fastTextフォルダーに移動して、
(fasTtext)$ ./fasttext skipgram -input ~/NLP/corpora/bocchan_wakati.txt -output ~/NLP/corpora/bocchan_model
と入力すると、bocchan_model.binと bocchan_model.vec が作成されます。binファイルは「subword」などの学習に使ったデータを含んだ大きなバイナリデータで、vecファイルは単語ベクトルのデータを含むテキストファイルです。
この単語ベクトルの値を使って、類似の単語について出力してみます。
fastText $ ./fasttext nn ~/NLP/corpora/bocchan_model.bin Query word? 先生
と入力すると、以下の結果が表示されます。
気の毒 0.998252 とも 0.998075 延岡 0.998068 はず 0.998013 代り 0.997956 住ん 0.99785 けれども 0.997844 今日 0.997815 残念 0.997802 ここ 0.997637
日本語Wikipediaのコーパスを用いた例を取り上げます。日本語のdumpsサイトから 'jawiki-latest-pages-articles-multistream.xml.bz2' のようなwikipedia全体の分かち書きしたファイルを作成すると、 3GB以上のサイズとなります。単語の分散表現を学習させる際、Wikipedia 全体のサイズが必要ないときに使われるコーパスとして text8 があります。 text8 は、Wikipedia に対してクリーニング等の処理をした後、100MB分切り出して作成されています。 text8 は前処理済みで簡単に使えるので、チュートリアル等でよく利用されています。日本語バージョンのtext8コーパスをダウンロードします。
$ wget https://s3-ap-northeast-1.amazonaws.com/dev.tech-sketch.jp/chakki/public/ja.text8.zip
(fastText) $ ./fasttext skipgram -input ~/NLP/corpora/ja.text8 -output ~/NLP/corpora/ja.text8_model
この単語ベクトルの値を使って、類似の単語について出力してみます。
$ ./fasttext nn ~/NLP/corpora/ja.text8_model.bin $ Query word? 利根川
元荒川 0.844393 鳴瀬川 0.832339 綾瀬川 0.830789 常盤川 0.807554 永野川 0.807308 狩野川 0.807213 用水路 0.80265 吉野川 0.798709 品井沼 0.795811 大野川 0.792659
利根川にもっとも近い単語はやはり「元荒川」でした。
Skipgramのpython コードを使うと処理時間が長いので、エラーが出ることがあります。これは、元のコードがC++で構築されていたため、Python APIに適用する過程で幾つかの齟齬が見られ、それらを修正するための大きな変更が加えられたことによります。ファイルの読み込みにエラーが出ます。fasttextに関する解説がweb で多数見られますが、pythonを用いたskipgramの使用は避けたほうが無難です。できれば、commandlineを用いて下さい。python APIが問題なく使用できる段階になったら、修正します。
自然言語処理の続編:NLTK の利用と感情分析のページに進む