CLIPの構造
|
従来のニューラルネットワークによる画像の生成モデルは GAN (Generative Adversarial Nets) です。また、GAN の改良版の DCGAN、CycleGAN 、 Style Transfer などのモデルです。これらのモデルは、画像を入力して新しい画像を生成するというアーキテクチャを組み込んでいます。
近年には、言語による記述から画像を生成する技術が発達しています。 DALL・E 3は、OpenAI社が開発した画像生成のAIアーキテクチャーで、驚異的な能力により画像生成AIの流行を牽引しています。 OpenAIのDALL・E 3 を利用するためには ChatGPT PLUS サブスクリプションが必要でしたが、2024年8月9日、ChatGPTの無料ユーザーでもDALL·E3による画像生成が可能になることが発表されました。その結果、ChatGPT から無料で利用可能になりました(1日最大2枚まで)。また、Microsoft のアカウントがあれば、Bing Image Creator から無料で DALL・E 3 を利用できます。
このページでは、DALL・E シリーズの基本アーキテクチャーを解説し、それを構成するモジュールのCLIP modelとDiffusion modelについての説明を試みます。CLIPのPython 実装をGoogle Colab を利用して実行します。任意の画像を用いたZero Shot Classification を試みます。また、OpenAI のGLIDE アーキテクチャを説明して、画像の生成を実行してみます。
DALL·E3の利用を ChatGPT および Microsoft の Bing から行います。幾つかの例を実行してみます。
このDALL・E 3 のライバルは MidJourney 5.2 と、 Stable Diffusion XLでしょう。そのうち、Stable Diffusion XL の体験的入門を行いましょう。DALL・E 3 と Stable Diffusion は無料で利用する方法がありますが、Midjourney には無料版がありません。
DALLE や Stable Diffusion をはじめとする画像生成AIは、アーティストがWeb上に公開した作品をスクレイピングした教師データを利用しているので、作品を制作したアーティストの同意や許可を得ずに行われることが多い。このことから、画像生成AIが著作権法に違反しているのではないかという批判が起きています。
近年、日本語で使える画像生成 AI がいくつか登場しています。Sakana AI が開発したEvoSDXL-JPやFlux の日本語バージョンなどが代表的な画像生成 AI です。
Google DeepMind の Imagen 3 はテキストプロンプトから高品質な画像を生成する画像生成モデルです。この最新画像生成モデル「imagen 3」を使用し、プロンプトから画像を生成できるツール「ImageFX」もリリースされました。同時に既存の生成AI作成ツール「MusicFX」と「TextFX」もリニューアルされています。Googleアカウントがあれば試すことができます。Imagen3 の利用については、 このページを見て下さい。
Last updated: 2024.10.15
CLIPの仕組み |
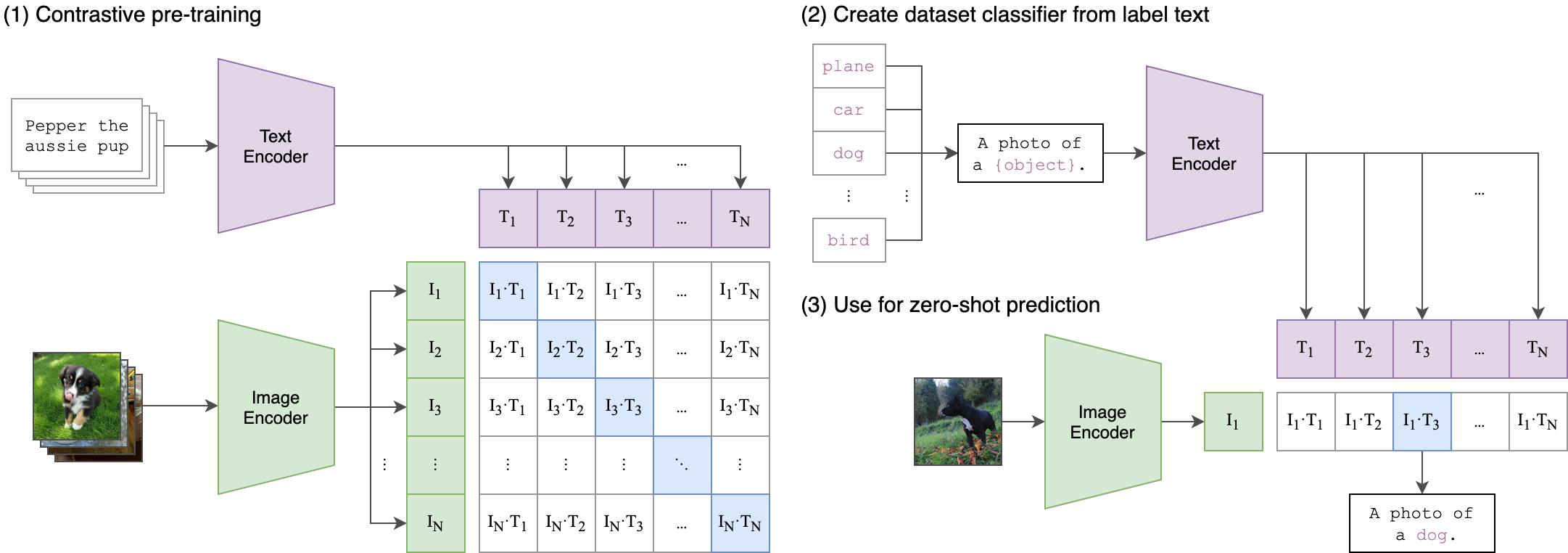
CLIP(Contrastive Language-Image Pre-Training)は2021年2月にOpenAIが公開した物体識別モデルです。通常の物体識別モデルでは、ImageNetなどにある1000カテゴリから物体を識別しますが、CLIPはWEB上の画像と対応するテキストからなる4億個以上のデータで学習されています。ImageNetで学習されたモデルと同等の検出率で物体識別を行うことが可能です。
CLIPは、Image EncoderとText Encoderを組み合わせて学習を行います。学習データは、(image, text)のペアから構成されています。画像をEncodeしたベクトルと、テキストをEncodeしたベクトルの内積が、正しCKIPわせでは1、間違った組み合わせでは0となるように学習を行います。推論では、学習されたText Encoderを使用して、ターゲットとなるデータセットのクラス名をEncodeし、Embeddingされたベクトルを取得、画像をEncodeしたベクトルと内積を計算、最も高い値を持つラベルを正解とします。このような手順で、Zero-shot linear classifierを生成します。
CLIPの構造
CLIPのコードはgithub.com/OpenAI/CLIPにあります。
CLIPを用いて、画像の識別を実行するためには、github.com/openai/CLIP.git をダウンロードして、インストールします。PyTorch 1.7.1 以降のバージョンが必要です。
! pip install -c pytorch torchvision cudatoolkit=11.0 ! pip install ftfy regex tqdm ! pip install git+https://github.com/openai/CLIP.git
以下のコードは、上に表示したCLIPの構造を示す画像を読み込んで、その画像を識別する例になります。"a diagram", "a dog", "a cat"のどれに最も近いかを判定します。
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
CLIP.pngの代わりに犬または猫の画像を使用してみてください。
Cifar100のクラス分類を用いて、Zero-Shot Prediction を行うときは、以下のようなコード使用します。cifar100[4536]は路面電車の画像です。
import os
import clip
import torch
from torchvision.datasets import CIFAR100
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
# Prepare the inputs
image, class_id = cifar100[4536]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
以下の結果が表示されます。
Top predictions: streetcar: 96.11% bus: 2.36% train: 1.13% bicycle: 0.04% orange: 0.04%
CLIPのモデルをダウンロードして実行するためのサンプルコードはこのColab(Interacting with CLIP.ipynb)に紹介されています。
DALL·E 2の仕組み |
2022年4月に公開されたDALL・E2では、CLIPの画像識別と拡散モデルの画像生成モデル(GLIDE)を組み合わせて画像生成を行ないます。テキストから画像を生成する上で用いられているのが拡散モデル(diffusion model)です。つまり、DALL・E2では、CLIPで得られたテキストのembeddingを画像生成の入力データとして用いて、拡散モデルからの出力がdecodeされます。
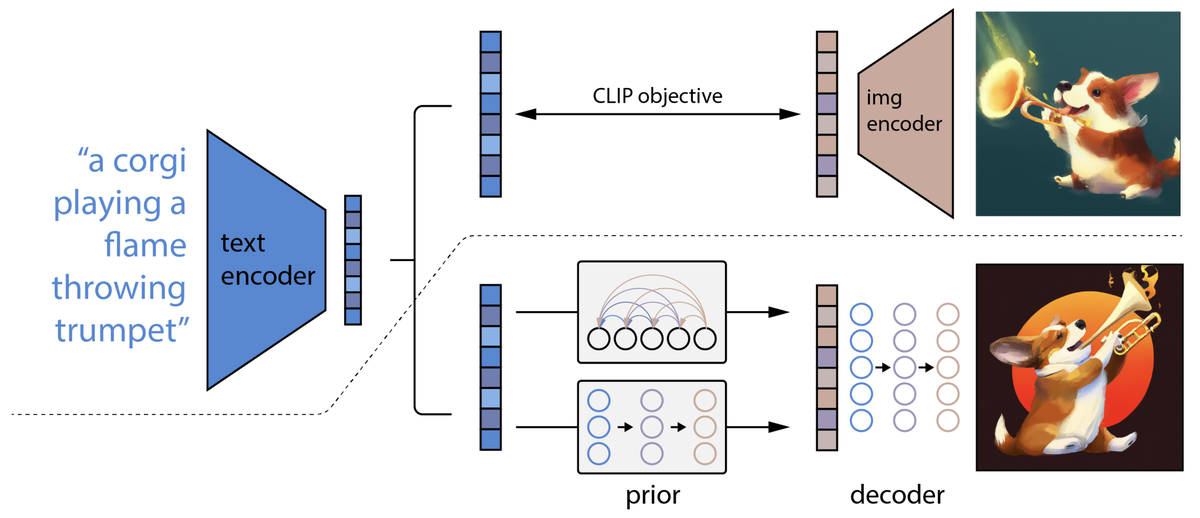
Dalle 2の構造
Diffusion Modelとは、元の画像に少しずつノイズを加えて、元の画像を壊して、その壊れた状態からノイズを取り除いて復元するという方法を採用します。具体的に、元のオリジナルデータに対して、各ステップに対して、少しずつGaussian Noiseを入れて、Tステップまで行います(Forward process)。Tが大きいければ、元の画像は最終的には完全にgausian 分布になります。そこから、少しずつノイズを取り除いて、もとの画像に復元するという学習を行います。
従って、Forward process(拡散過程)は基本的にgaussian分布からnoiseを加えて、そして、Reverse processs(生成過程)で、少しずつ加えたnoiseを取り除いて、各ステップで、元のデータに戻すためのパラメータを学習します。学習が完了すれば、完全なrandom noiseから、元の画像を生成することができます。
拡散モデルはGANやVAEモデルなどのように、潜在変数モデルに基づく生成モデルとみなすことができます。潜在変数モデルに基づく生成モデルは、はじめに潜在変数を生成し、次に潜在変数から観測データを生成します。拡散モデルでは、最初のノイズや途中のノイズを加えたデータが潜在変数であるとみなします。ただ、拡散モデルは従来の生成モデルと比べて優れた点が多くあります。1つは、学習が安定していること。テキストから画像を生成する能力は、拡散モデルもGANも同等に備えています。ただ、GANでは敵対的学習の構造そのものに、学習の不安定さと多様性の欠如があります。拡散モデルでは1つのモデルで安定した最尤(さいゆう)推定を使って学習すればよく、敵対的生成モデル(例えばGAN)のように学習が不安定ではなく、また変分自己符号化器(VAE)のように生成モデルと同時に認識モデルを学習する必要がない。2つ目は、難しい生成問題を簡単な部分生成問題に自動的に分解し、難しいデータ対象も生成できるように学習できることにあります。拡散モデルの生成過程は、多くの確率層を使った非常に深いネットワークとみなすことができる。
diffusion modelをPythonで実装するコードの説明は、//keras.io/examples/generative/ddim/にあります。
OpenAIが開発したGLIDEのコードはにあります。下の画像は、"an oil painting of a goldenredviever"と入力したとき、clip_guided.ipynbを利用して描いたゴールデンレッドリバーの生成画です。

"an oil painting of a goldenredriever"
Diffusion modelが採用されている代表的なAIサービスとして、DALL・E 2 のほかに Stable Diffusion があります。Stable Diffusionを試しに使ってみたい方は、Webアプリケーション上に公開されているHugging Face や Dream StudioなどのWebサービスを利用すると効率的です。 Hugging Face を利用するときは、このwebサイトにアクセスしてください。
DALL·E 3 の利用 |
DALL・E 3 は2023年9月21日にOpenAI社が公開した最新の画像生成AIで、テキストプロンプトから画像を生成するDALL·E シリーズの最新版です。ChatGPT Plus から利用可能になっていましたが、ChatGPT から無料で OpenAI の DALL·E 3 を利用することができるようになりました(制限がついてます)。なお、Microsoft の Bing/Image Creator を利用すれば、無料で DALL·E 3 を使用して AI 画像を生成することができます。Microsoft Bing はMicrosoft のアカウントを作成すれば、利用可能です。テキスト プロンプトを入力すると、そのプロンプトに一致する一連の画像が AI によって生成されます。
利用規約によれば、DALLEで作成した画像の所有権はユーザにあります。これには、無料または有料のクレジットを通じて生成された画像に関係なく、再印刷、販売、商品化の権利も含まれます。 ただし、Microsoft Bing Image Creatorは個人の非商業目的のみ利用可能で、商用利用不可となっていますのでご注意ください。また、Microsoft のcopilot の websiteからも無料で利用できます。
ChatGPT から「コートダジュールのニース海岸の風景画を描いて下さい。」とプロンプトを入力しました。下の画像がその答えです。

ChatGPT による画像生成:コートダジュールのニース海岸の風景画
下に表示されている絵は Microsoftの Bing Image-creator を用いて生成した画像の例です。"a big dog seeing Enoshima on automobile"というメッセージを入力しました。

DALL·E 3による画像生成
「樅木の下でフルートを吹く女性」というテキストを入力すると、以下の画像が作成されました。

DALL·E 3による画像生成:樅木の下でフルートを吹く女性
次に、例えば、「the light house and beach of Collioure,France」と具体的な風景画の対象を指示します。以下のような画像が作成されます。

DALL·E 3 による生成画像: the light house and beach of Collioure,France

Collioure の灯台の実際の写真
感想は、如何でしょうか?
水彩画風に描くようにしてみると、以下の画像が生成されました。

DALL·E 3 による生成画像:水彩画風
Stable Diffusion の利用 |
Stable Diffusionは、任意のテキスト入力から写真のような逼真な画像を生成できる拡散モデルです。 Stable Diffusionは無料でオンラインで使用して画像を作成できます。Stable Diffusion XLを使用して画像を生成するためためには、このオンラインページ公式サイトにアクセスします。無料で作成できる枚数には制限があります。
簡単に画像を作成してみましょう。例えば、「the light house and beach of Collioure, France」と具体的な風景画の対象を指示します。スタイルはデフォルトで作成ボタンをクリックします。以下のような画像が作成されます。

stable-diffusionによる生成画像
南フランスのコリウールの灯台とは相当雰囲気が違います。灯台は二つありません。
「Enoshima island in the city of Fujisawa, Japan」と入力して江ノ島を描いてもらいます。

stable-diffusionによる生成画像
どうでしょうか?江ノ島とは到底見えません。湖に浮かぶ小さな島みたいです。学習に使用された画像データには、日本各地の写真などは少ないと思われます。再学習が必要です。
日本語での画像生成 AI |
EvoSDXL-JPはSakana AIが教育目的で開発した日本特化の高速な画像生成モデルです。 入力した日本語プロンプトに沿った画像を生成することができます。以下のように説明されています。
多くの画像生成モデルは、拡散モデルを基盤としており、高性能な画像生成が可能になっています。特に、SDXL、DALLE-3をはじめとしたtext-to-imageモデルは、テキストプロンプトに沿った高性能な画像が生成され、多くの反響を呼んでいます。しかし、拡散モデルを基盤とした画像生成モデルは、推論速度が遅いという課題があります。これは、拡散モデルがノイズ画像から徐々にノイズを除去するステップを繰り返すことで画像を生成するという仕組みに起因します。この課題に対して昨今多くの研究が行われ、最近では一般的な拡散モデルに比べ、およそ1/10程度のステップ数で画像を生成できるようにする手法が提案されています。画像生成の処理時間はステップ数に比例するため、これらの手法は一般的な拡散モデルに対しおよそ10倍の速度で画像が生成できます。
公開されている画像生成モデルの多くは、主に英語プロンプトに対応しています。そのため、非英語話者のユーザーは「呪文」としてテキストプロンプトを調整し、画像生成を試みているのが現状です。また、機械翻訳を用いて日本語から英語に直す場合、コストが高く、翻訳機の性能に依存し、日本特有の表現の使用が限定されます。現在、公開されている日本特化の画像生成モデルは、日本語プロンプトに対応し日本スタイルの画像生成が可能ですが、従来の拡散モデルと同様に推論速度に課題があります。そこで私たちは、進化的モデルマージにより日本特化の高速な画像生成が可能なモデルを構築しました。
無料で利用可能なwebdemo が提供されているので、EvoSDXL-JP を使ってみましょう。HuggingFace のEvoSDXL-JPにアクセスしましょう。日本語でプロンプトを入力してください。「江ノ島と富士山が見える風景を描いてください。」書きました。以下の画像が生成されました。

EvoSDXL-JP による生成画像 1
富士山はよく分かりますが、江ノ島の景色は分かりません。 次に、「子猫を抱いた、帽子をかぶった女性、髪の毛はブラウンで、長く、カーリーです。」と入力しました。以下の画像が生成されました。

EvoSDXL-JP による生成画像 2
かなりリアルに描いてくれました。
次に、日本で開発されたソフトではありませんが、日本語でのプロンプト入力ができる画像生成 AI 、Flux の日本語バージョンを取り上げます。
Flux.1 は、Stable Diffusionの開発者たちが設立したBlack Forest Labsが発表した最新の画像生成AIモデルです。FLUX.1 は、120億ものパラメータを持ち、プロンプトに忠実に従う能力が高く評価されているそうです。特に、画像内に文字を正確に表示する能力が他のAIモデルと比べて優れており、デザインやマーケティングなどの分野で高品質なビジュアルコンテンツを作成するためのツールとして注目を集めています。Fluxはサービス名、FLUX.1はモデルのバージョン名を示します。
Fluxはオープンソースモデルとして公開されており、開発者や企業は自由にFluxのコードを閲覧し、改変できます。 Fluxを利用する前に、以下のステップでアカウントを作成しましょう。
まずは、Flux の日本語のサイトにアクセスします。Google のアカウントでログインします。新規アカウント作成時には無料クレジットが提供されます。日本語サイトでは5回分の画像を生成できるクレジット数です。
「江ノ島と富士山が見える風景を描いてください。」とプロンプトに入力します。

Flux による生成画像 1
次に、上と同じく、「子猫を抱いた、帽子をかぶった女性、髪の毛はブラウンで、長く、カーリーです。」と入力します。

Flux による生成画像 2
EvoSDXL-JP による生成画像と比較して、どのような感想を持ちますか?
最後に、MyEdit と、CommonArt β で同じプロンプトを入力して画像を生成してみました。
MyEdit とは、AI技術が搭載された画像編集・写真加工ツールです。もちろん、画像生成AIにも対応しています。 運営元のCyberLink(サイバーリンク)社は、1996年に設立した台湾に本社を置く企業です。日本にも支社が存在し、MyEditだけでなく「PowerDirector 365」「PhotoDirector 365」など、さまざまな商品・サービスを展開しています。
公式サイトにログインし「サインイン」をクリックします。メールアドレス、Googleアカウント、Facebookアカウント、Appleアカウントのいずれかでアカウントを作成できます。無料版では1回ログインすることで1日3クレジット貰えるので、「無料クレジットの獲得」をクリックします。AIを活用した画像生成は1日3回までしか使えません。
以下が生成された画像です。

Myedit による生成画像 1

Myedit による生成画像 2
江ノ島の風景画よく分かりません。子猫を抱いているのに、女性の雰囲気が怖そうです。
CommonArt β を利用した画像生成を行いましょう。「CommonArt β」は、安全で透明性の高い、日本語画像生成AIで、商用利用可能です。著作権やライセンスに配慮した学習素材を使用しており、日本人の感覚に近い日本語で自然な画像を生成することが可能と言われます。Apache-2.0 Licenseを採用し、クリエイターに無償で提供されています。
無料で利用できるURL CommonArt β - a Hugging Face Space by aipicassoに行きます。上までの画像生成と同じプロンプトを入力しました。以下が結果です。

CommonArt β による生成画像 1

CommonArt β による生成画像 2
EvoSDXL-JP 、 Flux.1 、 および、MyEdit などとは相当異質な画像が生成されます。普通のリアルな感じの画像は生成されません。デフォルメされた画像の生成が得意なようです。