|
Python 入門 |
Pythonはさまざまな分野のアプリケーションで使われている、極めてパワフルな動的プログラミング言語です。機械学習、ディープ・ラーニングやデータサイエンスなどの分野では必須の言語となっています。ロボティクスで使用されるシングルボード・コンピュータのRaspberry Piでは組み込み言語として必須の役割をします。Pythonはよく、C言語(C++)、Javascriptなどとよく比較されます。C言語と異なりPythonはコンパイルする必要がありません。 しかし、C++と比較して、コンパイルが必要ないことの反面で、処理速度はC++をコンパイルしたコードの実行に比較して遅くなります。超高速の処理が必要な場合には、C++と組み合わせて活用することが必要です。
Pythonは2種類のバージョン、3.xと2.xという2種類が共存していました。python 2.7が 2.x の最終バージョンです。現在、Python 2 シリーズは公式にはサポートされていません。バージョン3とバージョン2との間には互換性はありません。これからPythonを始める場合は、バージョン3から始めましょう。
Pythonはフリーソフトなので、多数のサイトから無料でダウンロードできます。日本でのPython情報サイトは、www.python.jpです。Pythonの公式ダウンロードページはhttps://www.python.org/です。MacOS および Ubuntu などでは、python は OS にプリインストールされていますが、バージョンが古いと思います。このページでの python 学習程度ならそれで十分ですが、機械学習などを実行するフレームワークを使用するためには、各フレームワークに対応した新しいバージョンの Python をインストールした方が望ましいでしょう。
Pythonでの研究・開発をサポートするツールに、Jupyter Notebook があります。Jupyter Notebook は文章や実行可能なプログラム、実行結果のグラフなどを、一つのノートブックにまとめて管理できる Web アプリケーションです。プログラムを対話的に修正・実行して結果を保存できるので、研究・開発に必要な試行錯誤に最適な環境となっています。Python をインストールすると合わせてインストールしましょう。
Python 環境がインストールしてあれば、Microsoft社のプログラミング用テキストエディタ Visual Studio Code (VS Code) を用いるのが便利です。VS Code に Python 拡張機能をインストールして、Pythonのプログラムを開発・実行することができます。Jupyter Notebook を使用する場合は、VS Code に Jupyter 拡張機能をインストールする必要があります。Visual Studio Code のWebサイト より Download for Mac or Windows をクリックして VS Code をダウンロードできます。
プログラミング経験がまったくなく、とりあえずプログラミングを体験してみたいという場合には、自身のPCにPythonをインストールする必要はありません。 Google Colaboratoryを使うと、PC のWebブラウザからPythonを使えます。ただし、Jupyter Notebook 形式になっていますので、 Jupyter Notebook 操作の基礎知識が必要です。
Python のバージョンアップが積極的に展開されている中で、応用ライブラリの開発は Python のバージョンアップに対応できていないという現状があります。従って、Python だけをバージョンアップすると、使用していたライブラリの利用でエラーが出たりします。こうした問題を回避するために、仮想環境を構築する方法が採用されます。つまり、1台のPC内に Python の各バージョンに対応した環境、Python 3.12 を使用できる世界、Python 3.13 を使用できる世界、というようにバージョンごとの世界を複数構築します。これを仮想環境と呼びます。仮想環境の構築についての説明は、Pythonの仮想環境構築のページを読んでください。
Last updated:2026.1.19
Python の基礎的文法 |
このページでは、Python 3.12 をインストールした環境で実行します。2025年12月現在で、最新版はpython 3.14 です。このページでは、Python 3.12 を使用しますが、基本的な処理の説明は、バージョン3.10 でも 3.12 でも共通します。ただ、主要な AI 関係の Python API の多くは 3.14 をまだサポートしていません。ここでは、Python3 のバージョンがインストールされていることを前提とします。
ターミナルで python または python3 コマンドを入力したら、以下のような入力待ちの画面になります。python 2.x がインストールされた状態で、python コマンドを入力すると、python 2 バージョンが起動してしまします。そのときは、 python3 と打ちます。以下の MacOS の例では、python3.12 とバージョンも指定しています。
~ $ python3.12 Python 3.12.5 (v3.12.5:ff3bc82f7c9, Aug 7 2024, 05:32:06) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>
プロンプト >>> の後に、Pythonのコマンドを入力して操作します。
Visual Studio Code を利用するときは、VS Code のメニューバーにある「ターミナル」→「新しいターミナル」をクリックして、ターミナルを表示します。そして、上と同じように、入力します。VS Code にリンクした Python のプロンプトがポップアップします。
Pythonの命令文や関数が処理できるデータは数値データと文字データです。これらの処理対象データを一括してオブジェクトと呼びます。オブジェクトを処理する方法を指示するのが命令文であり、関数です。数値データや文字データに操作を加えるためには、これらのオブジェクトを区別して保存する容器(引出し)が必要で、この容器(引出し)に名前(名称)をつける必要がある。名前をつけた入れ物(器)が変数と呼ばれる。
例えば、
>>> x='Hello World' >>> print(x)
と入力します。x=’Hello World’という命令文は、xという名称の容器(変数)にHello Worldという文字データを格納しなさいと指示します。引用符'...'("..." でもよい)はオブジェクトが文字データであることを指定しています。x=”Hello World”と書いても同じです。数値データの場合は、x=2.46 などと、そのまま書きます。print(x)は変数xの内容をシェルウインドウに印字することを指示しています。だから、print文が実行され、Hello Worldと表示されます。
加算、減算、乗算、徐算などの四則演算は、それぞれ、[+],[-],[*],[/]という記号を用いて実行できます。ただし、累乗計算、例えば、2.3の5.1乗という計算は
>>> z = 2.3**5.1
>>> print(z)
69.95390512773743
と記述します。終了するときのコマンドは
>>> quit()
と入力します。「Control + D」を入力しても、終了できます。
Pythonを用いて、科学技術計算、データの統計処理、グラフィックスの作成、ネットワークの分析などを実行するためには、それらに対応するPythonのモジュール・パッケージをインストールする必要があります。例えば、Numpy、Scipy、Pandas、Matplotlib、Networkxなどのsite-packagesをインストールする必要が出てきます。これらのパッケージをインストールする通常の方法はpipというコマンドを用います。例えば、以下のように pip コマンドを用いて打ちます。
$ python3.12 -m pip install numpy scipy matplotlib
Python 3.12 でパッケージをインストールするときの例です。インストールした Python のバージョンが複数存在する時には、上の例のように、 python3.12 のようなバージョン番号を付けたコマンドを使用します。バージョン番号なしの python3 を使用すると、異なるバージョンのディレクトリにインストールされる危険性があります。
Pythonの基礎文法をCommand Lineを用いて説明します。まず、ipython を用いてpyhton3を起動します。以下のような表示となります。
~ $ ipython Python 3.12.5 (v3.12.5:ff3bc82f7c9, Aug 7 2024, 05:32:06) [Clang 13.0.0 (clang-1300.0.29.30)] Type 'copyright', 'credits' or 'license' for more information IPython 8.26.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
In [1] の後ろにコマンドを入力します。すべてのコマンドの入力では英文入力に切り替えてください。最初に、
In [1]: x=’Hello World’
と入力して下さい。次のコマンドライン(In [2])が出ます。そこで
In [2]: print(x)
と入力して下さい。xの内容であるHello Worldが表示されます。
Pythonの命令文や関数が処理できるデータは数値データと文字データです。これらの処理対象データを一括してオブジェクトと呼びます。オブジェクトを処理する方法を指示するのが命令文であり、関数である。数値データや文字データに操作を加えるためには、これらのオブジェクトを区別して保存する入れ物(器)が必要で、この入れ物(器)に名前(名称)をつける必要がある。名前をつけた入れ物(器)が変数と呼ばれる。
x=’Hello World’という命令文は、xという名称の入れ物(変数)にHello Worldという文字データを格納しなさいと指示している。x=”Hello World”と書いても同じです。引用符’…‘(”… “)はオブジェクトが文字データであることを指定している。数値データの場合は、x=2.46 などと直接に書きます。print(x)は変数xの内容をウインドウに印字することを指示しています。
変数を処理するに当たり、使用可能は四則演算の演算子は以下の通りです。加算をさせるときは、 + を使用、引き算をするときは – を、掛け算をするときは * を、割り算をするときは / を、累乗を計算するときは ** を使う。(なお、excelの表計算関数では累乗は ^ を使うので、注意し下さい)オブジェクトが数値データのときは、数値計算そのものです。
オブジェクトが文字データのとき、様相は相当異なります。例えば、
In [3]: x='Hello World.' In [4]: 'Good Day!' In [5]: z=x+y In [6]: print(z)
と入力すると、’ Hello World. Good Day!’とシェル・ウインドウに計算結果が表示される。確認してみて下さい。
pythonの終了は、上で触れた通り
In [7]: quit()
と入力します。「control + d」と入力しても終了します。
Pythonの基礎を知るために、オブジェクトの型の種類について若干説明します。変数に単一の数値列、文字列を格納することは単純で分かり易いが、一つの変数に複数のデータを格納できればより便利さが増す。数学でいう集合を考えると分かり易い。複数のデータを順番に配列して格納した変数をリスト型という。リスト型変数はデータを一列に並べたオブジェクトで、
a=[1.0,2.0,3.0,4.0]
の形式で、各データをコンマ ',' で区切って順番に並べて、鍵括弧 [ ] で括ります。文字データも同じように、
b=['spam', 'eggs', 100, 1234]
と定義します。リスト内の配列の番地(インデックス)は0から始まる(1からではないので、注意が必要)。番地0には’spam’、番地1には’eggs’、番地2には数値100となっている。だから、変数bのインデックス0に対応するデータは’spam’、インデックス2に対応するのは数値100です。インデックス0の内容をb[0]、インデックス1の内容をb[1]と書く。だから、
print (b[1])
と入力すると、’eggs’とコンソールに表示される筈です。以上をやってみて下さい。これができれば、インデックス番号を指定して、その内容を入れ替えることが簡単にできます。
a[2]=20.0
とデータを入れ替えて、変数aの内容を印字してみて下さい。
a[2]=a[2]+20.0
としたらどうなりますか?面白いですね。
リスト型変数の内容を配列番地(インデックス)を利用して、様々なデータの処理を行うことをスライシングという。
x = [1.0,2.0,3.0,4.0,5.0]
としたとき、この変数の中から幾つかの要素だけを取り出したい、例えば、配列インデックス1からインデックス2までのデータを取り出したいときには、
x[1:3]
とします。1:3の意味は、インデックス1から3未満までの要素を取り出すことを意味する。インデックスiからjまでの要素を取り出すときは、i:j+1 とおきます。要注意です。インデックスの指定を省略することができます。例えば、
x[:4]
とおくと、: の前の0が省略されていると見なされる。この結果、[1.0,2.0,3.0,4.0]が取り出され、印字される。反対に、
x[2:]
とおくと、インデックスの2から最後の配列要素まで取り出される。[3.0,4.0,5.0]と表示される。データ数を増加させることも容易にできる。
y=[0.1,0.2] z=x+y print (z)
とおくと、zの要素が[1.0,2.0,3.0,4.0,5.0,0.1,0.2]となっていることが確認できる。要素を削除するときには、del文を使う。例えば、
del z[2] print (z)
とおくと、変数zの中から3.0が削除されて、データの数が減っていることが確認できる。zの中で最大値を取り出す関数はmax(z)であり、最小値を取り出す関数はmin(z)である。ちなみに、
max(z)
とおくと、5.0と表示される。関数の前に余計な空白をおくと、エラーとなります。データの数、つまり変数に格納されている要素数を調べるには len(z) と入力します。
データ処理では、要素を並べ替える必要性が頻繁に起きます。Pythonでは、このような操作はオブジェクト変数の後ろに、メソードと呼ばれる命令文(関数)を付けて処理される。例えば、数値を小さい順から並べ替えるに z.sort() とおくと、zの内容が小さい順から配列される。zの内容は並べ替えられているので、print (z) とおいてみると確認できる。命令文sort()の括弧()は必ず付けて下さい。大きい順から並べ替える方法は、z.reverse()と入力すれば良い。試してみて下さい。
多次元配列及び辞書型変数も活用できますが、ここでは簡単なリスト型変数の処理についてまでにします。以下の例を見てください。以下のコードをコピーして、ipython のプロンプト In[1]: の後に貼り付けて実行してください。
name = ["cheese", "John"] print (name[1],name[0]) x=["spam","spam","spam","spam","spam","egg","and","spam"] print (x[5:7]) print (x[5],x[6],x[7])
下記のようになります。
In [1]: name = ["cheese", "John"] ...: print (name[1],name[0]) ...: ...: x=["spam","spam","spam","spam","spam","egg","and","spam"] ...: print (x[5:7]) ...: print (x[5],x[6],x[7]) John cheese ['egg', 'and'] egg and spam
次のような方法でも実行できます。上記のコードをpythonスクリプトとして、たとえば、example.py という拡張子「.py」を付けたテキストファイルで保存します。ターミナルを起動して、このファイルのあるディレクトリに移動して、
$ python example.py
と実行します。スクリプト example.py が実行されて、結果が表示されます。
ところで、変数の要素の番地は1からではなく、0から始まります。この例から変数の構造をよく理解できます。python インタープリーは、各行を上から順番に読み込んで実行します。文法上の誤りが見つかった行でエラーを出して、そこで実行を停止します。#のついた行はコメント文を表現します。python インタープリーは#の後から行末までをコメントと認識して、読み込みをパスします。見易のために、空白の行を使います。
再度、配列番地の理解を復習しましょう。オブジェクトのリスト型配列のスライスの働きかたをおぼえる良い方法は、番地が要素と要素のあいだ (between) を指しており、最初の要素の左端が 0 になっていると考えることです。そうすると、 n 個のデータからなる配列中の最後の要素の右端は番地が n となります。x=[a,b,c,d]のとき
| a | b | c | d | 0 1 2 3 4
とインデックスは割り振られる。iから j までのスライスは、それぞれ i と付いた境界から j と付いた境界までの全ての文字から成っています。
if 文, for 文、while 文、def 文について |
以下の例でのコードは Jupyter Notebook を用いた方が便利だと思いますので、Jupyter Notebook をインストールして下さい。以下のコードを入力すると、簡単に Jupyter Notebook をインストールできます。
$ python -m pip install --upgrade pip $ python -m pip install jupyter notebook
以下のコマンドを入力すると、Jupyter Notebook が起動します。
$ jupyter notebook
Jupyter Notebookのダッシュボードがデスクトップに表示されます。右上に位置する[new]をクリックして、[python3]とします。ノートブックが起動しますので、作成してある[file]を開くか、あるいは、セルに新しいコードを記述します。セルの実行は、実行したいセルを選択して、「Run」をクリックします。ターミナルで「control + c」と打って終了します。
ここで、場合に応じて処理を振り分ける複合文の書き方について説明します。Pythonでの振り分け処理には、while文、if文、for文があります。以下のフィボナッチ数列の例を見ましょう。
# Fibonacci series:
# the sum of two elements defines the next
a, b = 0, 1
while b < 10:
print(b)
a, b = b, a+b
これを実行すると、
1 1 2 3 5 8
と表示されます。この例では、コメントの後に、最初の行に複数同時の代入 (multiple assignment) が入っています:。変数 a と b は、それぞれ同時に新しい値 0 と 1 になっています。この代入は、最後の行でも使われています。代入文では、まず右辺の式がすべて評価され、次に代入が行われます。右辺の式は、左から右へと順番に評価されます。
while は、条件 (ここでは b < 10) が真である限り実行を繰り返します(ループと言います)。Python では、C 言語と同様に、ゼロでない整数値は真となり、ゼロは偽です。条件式(condition文)には、文字列値やリスト値なども使えます。例で使われている条件式はシンプルな比較です。標準的な比較演算子は C 言語と同様です。 すなわち、 < (より小さい)、 > (より大きい)、 == (等しい)、 <= (より小さいか等しい)、 >= (より大きいか等しい)、および != (等しくない)、です。
要約すると、while文は以下のような構造をしている。
while condition文 : (インデントの空白) while-bodyの記述
上記のwhile文は、condition文で記述されている条件が成立している間は、while-bodyで記述された文を実行することを指令している。ループの 本体 (while-body) は インデント (indent, 字下げ) されています。while-bodyの記述はすべて1字以上の空白でインデントされなければならない。インデントは Python において、実行文をグループにまとめる方法です。入力の完了を示すために最後に空行を続けなければなりません。while-bodyでは、全ての行は同じだけインデントされていなければならないので注意してください。通常は、4文字分空けます。半角でtabキーを使います。しかし、全角で空白を入力するとエラーが出ます。
次に、if文とfor文を使いましょう。以下のコードをコピペして、実行してください。
# "if" and "while" sentences
x=15
print(x)
if x < 5 or (x > 10 and x <20):
print ("the value is ok.")
while x >= 0:
print ("x is still not negative. x= ",x)
x = x -1
# the "for" sentence
for i in [1,2,3,4,5]:
print ("This is iteration number.",i)
#Print out the value from 0 to 49 inclusive.
for value in range(50):
print (value,)
この例から、振り分け処理の仕方が解ると思います。range(50) は0 から 50 未満、つまり、49までの数値列を意味します。なお、 range(5,50) とすると、5 から 50 未満までの数値列を表現できます。
ここで、if文の構文を詳しく見て見ましょう。 if文は以下のように使用されます。
if condition-1 :
if-bodyの文
elif condition-2:
elif-bodyの文
else:
els-bodyの文
もしcondition-1が真であるならば、if-bodyの文を実行する。condition-1が成立しないとき、condition-2が成立するならば、els-bodyの文を実行する。condition-1もcondition-2も両方とも不成立ならば、els-bodyの文を実行する。elifはelse ifの省略形である。elif文とelse文は省略可能である。以下のように、スクリプトファイルを作成して、実行して下さい。
# "if" sentences
x=int(input('整数を入力して下さい: '))
if x < 0:
x = 0
print('負の整数なので、ゼロとした')
elif x == 0:
print('ゼロ')
else :
print(x,'は正の整数です')
ここで、int(..) は数値を整数にする命令であり、input(.. ) は '整数を入力して下さい: ' とターミナルに表示して、キーボードからの入力を受け取るコマンドです。キーボードから整数を入力して見てください。
同一の処理を何度も繰り返すとき、この処理方法を関数として定義しておいて、使用するごとに、この関数を呼び出して使うことは便利である。関数を定義する方法について説明する。関数を定義する形式は以下の通りです。
def function_name(arg_list): (インデント) function_bodyの文
defで始まる第1行目 function_name: は function_name という名称の関数を定義する文である。function_name は、例えば、fibonachi というような英文の適当な名前をつけて良い。ただし、Pythonで組み込み関数で使用されている関数名(予約語、例えば、cos、logなど)は使用できない。引数(arg_list)は、後の例で説明されるように、関数で使用される変数のリストを入力する。
関数の定義の仕方について理解するためのスクリプトを下に示します。
# Fibonachi series
def fib(n):
a,b=0,1
while b < n:
print(b,)
a,b=b,a+b
return
fib(2000)
def fib(n): 文は関数名 fib で関数を定義し、引数の変数が n であることを記述します。function_bodyの文 はreturn文で終わります。最後の行にある fib(2000)は、上で定義した関数 fib を呼び出して、変数の値をn=2000とした時の関数値を求めていま
す。このスクリプトをコピーして、実行させて下さい。
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
という結果が返されれば、成功です。また、関数スクリプトを独立したスクリプトとして、つまり、モジュールとして作成することもできます。この場合、通常のスクリプトファイルと同様に、関数スクリプトを拡張子 .py を付けて保存します。詳しくは、Python公式ホムページのドキュメントを参照してください。日本語の解説は https://www.python.jp/にあります。
配列データ(リスト型、辞書型)の処理 |
集合や行列などのような配列形式で表現するオブジェクト変数は、タプル型、リスト型、辞書型と呼ばれる様式に従って記述します。最初にリスト型オブジェクトを取り上げます。
リスト型変数についてはすでに上で説明しましたが、復習しましょう。リスト型変数は角括弧 [] で囲んで、その中に、以下のように、数値や文字のデータをコンマで区切って入れます。
>>> a = [1, 20,50,150.0, 32.5] >>> stations = ["東京", "品川", "新横浜", "小田原", "熱海"] >>> a [1, 20, 50, 150.0, 32.5] >>> stations ['東京', '品川', '新横浜', '小田原', '熱海']
リストにも、文字列と同じく、インデックスが利用できます。
>>> stations[1] '品川' >>> a[-1] 32.5
インデックス番号2から4までの要素を取り出したいときは、以下のようにします。
>>> stations[2:5] ['新横浜', '小田原', '熱海']
リストは len 関数や type 関数が使用できます。
>>> len(stations) 5 >>> type(a) list
リストのメソッドには、append、 insert、 pop、 del、 remove などがあります。詳細は省略します。python 情報サイトの解説を参照ください。
次に、辞書型オブジェクトについて説明します。リスト型オブジェクトは、順番に並んだ値をひとまとめの情報として管理するためのオブジェクトでした。リストオブジェクトに登録された値を取り出すときには、a[2] のように、参照する値の順番を指定します。
stations = ["東京", "品川", "新横浜", "小田原", "熱海"]
このような単純なリストであれば、最初の駅は東京駅、2番目の駅は品川駅、 …… のように、知りたい要素の順番だけを指定すれば必要な情報を取り出せます。
しかし、商品の価格のリストを作成したり、クラスの名簿を作成するときは、リスト型では作成できません。たとえば、英語の単語帳を作るときには、apple を指定すると りんご を返し、orange を指定すると みかん を返すような仕組みが必要です。あるいは、都道府県の県庁所在地を情報を作成するとき、埼玉県 を指定すると さいたま市 を返し、北海道 を指定すれば 札幌市 と返す仕組みが必要です。
このような、あるデータに対応する関連データを登録できるような仕組みとして、Pythonでは 辞書型オブジェクトが利用できます。辞書型オブジェクトには、「apple と りんご 」のような、2つの値を組み合わせたデータを作成できます。「apple と りんご 」の組み合わせを作成した辞書オブジェクトで、「apple」を検索すると、「りんご」を返すような操作ができます。
辞書型オブジェクトを検索する時に指定するデータ(この例では apple) を、辞書の「 キー 」といいます。また、キーに対応して、検索の結果となるデータ(この例では りんご)を、辞書の「 値 」といいます。
辞書型オブジェクトは、波括弧 { と } で作成します。
{キー1:値1, キー2:値2, ...}
>>> words = {"apple": "りんご", "orange": "みかん", "peach": "もも"}
b={'x':10, 'y':20}
>>> words
{'apple': 'りんご', 'orange': 'みかん', 'peach': 'もも'}
>>> type(b)
dict
dic は dictionary の略なので、辞書型ということです。辞書型データから値を取り出すときは、キーを指定します。
>>> words['peach'] 'もも' >>> b['x'] 10
辞書オブジェクトに要素を追加するときは、次のように記述します。
辞書オブジェクト[キー] = 値
変数 の代入文とおなじ形式です。
以下の例は、辞書 words に、キーが "dog"、値が "犬" という要素を追加しています。
>>> words["dog"] = "犬"
>>> words
{'apple': 'りんご', 'orange': 'みかん', 'peach': 'もも', 'dog': '犬'}
>>> len(words)
4
リスト型変数と同じようなメソッドが利用できます。説明は省略します。
数学で言う集合と類似のものとして、タプル型オブジェクトがあります。タプルは括弧 ( )の中にコンマで区切って値を入れます。この括弧を省略することができます。リストと非常によく似ていますが、異なる点は要素の値に代入ができないことです。タプルの場合、リストのように要素を変更することはできないので、タプルの要素を変更する場合は、あたらしくタプルオブジェクト全体を作り直す必要があります。
>>> c=(1, 2, 3, 10, 11, 12)
>>> person ='平田', '登', 50, '男性'
>>> person
('平田', '登', 50, '男性')
>>> person[3]
'男性'
>>> color = (255, 255, 0) # 黄色
>>> color[1] = 0 # 緑色を 0 に変更
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
----> 1 color[1] = 0
TypeError: 'tuple' object does not support item assignment
>>> color1=(255, 0, 0)
>>> color1
(255, 0, 0)
以下の節の説明では、python コードが複雑になりますので、Jupyter Notebook を使用する方が便利だと思います。Jupyter Notebook のインストールや使用法についての説明は、このページを読んでください。XCode や Visual Studio Code などの統合開発用のエディターを使用してもいいと思います。
クラスとクラスの継承 |
Python はオブジェクト指向言語ですが、オブジェクトの内容を記述しておく仕組みにclassという概念があります。classとは「ひな型」です。ひな型の中に、データを入れる領域、処理の仕方を書く領域を設けます。classの中で、処理の仕方を書いてある部分を「メソッド」と呼びます。実際には、Pythonのclassの「メソッド」は関数です。classの「メソッド」の中では自身のデータを参照できます。
classとは「ひな型」なので、現実にデータを格納するときは「インスタンス化」という手続きを使用します。「インスタンス化」とは、ひな型から実際のデータを格納したオブジェクトを作り、そのデータを保存しておくための手続きです。
Person というクラスを定義するときは、クラスの記述は以下のように始めます。
class Person(object): または class Person():
クラス名の引数 object を省略することができます。省略されるときは、基底クラスはオブジェクト(object)とみなされます。この後に続いて、処理の部分、つまりメソッドを記述します。
class Person(objest):
def say_hello(self):
print('Hello')
メソッドは def を使います。メソッド名の後の第1引数は必ず self と書きます。この self は object 自身を指しています。Personというひな型をインスタンス化するには、以下のようにします。
class Person(object):
def say_hello(self):
print('Hello')
person_1=Person() # オブジェクトの作成
person_1.say_hello() # オブジェクトからメソッドを呼び出す
クラス Person を呼び出して、変数 person_1 に格納して、Person クラスのオブジェクトを作成しています。その後、person_1 からメソッド say_hello() を呼び出します。「 Hello 」と表示されます。
クラスの記述の一般的様式は以下の通りです。
class クラス名(object):
def __init__(self, 引数, ...): # 初期化コンストラクタ
...
def __メソッド名1__(self, 引数, ...): # クラスが持つ属性やメソッドを定義する)
...
def __メソッド名2__(self, 引数, ...):
...
これは、「クラス名」という名前を持つ「クラスオブジェクト」を作成するコードです。各メソッドの第一引数はかならず self を使用することになっています。
Pythonにおけるオブジェクトのインスタンス化は、__init__メソッドで行ないます。__init__は、クラスを「インスタンス化」する際に必要な特殊なメソッドです。「インスタンス化」は、抽象的なクラスという概念に属性を与えて具体化することです。self.name と self.age はインスタンス変数と呼ばれ、初期化されます。つまり格納スペースが作成されます。各メソッドにおいて、メソッドの処理で使用される変数の前には必ず self. を付けなければいけない。
class Person(object):#Person というクラス名
def __init__(self, name, age):#初期化メソッド
self.name = name #name を付ける
self.age = age # age を付ける
def hello(self):
print('こんにちは{}さん!'.format(self.name))
person_1 =Person('加藤', '40')
person_1.hello()
以下の結果が表示されます。
こんにちは加藤さん!
Personクラスがobjectクラスのメソッドを継承していることを示している。__init__メソッドではインスタンス変数nameにその人の名前を、もう1つのインスタンス変数ageにその人の年齢を代入しています。
既存のクラスを引き継いだ新たなクラスを作成することができます。新たなクラスを呼び出して、既存クラスのメソッドを使用することができます。これをクラスの継承と言います。この方法を使用すると、クラスの記述を単純化できます。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hello(self):
print(f"Hello, I'm {self.name}!")
この Person クラスを継承した Employee という派生クラスを作ります。Employee クラスでは Person クラスが持つ name、age に加えて、department という変数を追加します。Employee クラスの __init__() の引数には self, name, age, department を指定し、 super().__init__() には name と age のみを渡します。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hello(self):
print(f"Hello, I'm {self.name}!")
class Employee(Person):
def __init__(self, name, age, department):
super().__init__(name, age)
self.department = department
emp1 = Employee("John", 30, "Sales")
print(emp1.name)
print(emp1.age)
print(emp1.department)
emp1.say_hello()
---- 結果
John
30
Sales
Hello, I'm John!
継承元のクラス Person のメソッドを呼び出すときは、super() を使用します。 super().__init__() は親クラス Person の初期化メソッド を呼び出します。属性(name, age)の値の設定処理を共通化させています。少々難しいです。
NumPy、SciPy、および、Matplotlibの使い方 |
数値計算のためには、NumPy および SciPy というモジュールが必須になります。また、画像の表示やグラフ表示のためには、Matplotlib パッケージが必要になります。この節では、NumPy、SciPy、Matplotlib の使い方を説明します。以下のようにインストールします。
$ python -m pip install numpy scipy matplotlib
これらのモジュールはすべてインストールされていることを前提にします。ここでは、数値計算やデータ処理の方法とグラフィックの使用法について説明します。NumPy、SciPyのドキュメントのページはこの英文公式ホームページにあります
Numpy などのライブラリに格納されている各種のモジュールを利用するためには、プログラムの始めに、以下のような文を記述しなければならない。
import numpy as np import scipy as sp import matplotlib.pyplot as plt
'import numpy as np' は numpy 内にあるすべての関数を np のメソッドとして使用できる状態にする。'scipy' の 'import' についても同様です。NumPy に内蔵されている基本的なモジュールは、線形代数(linalg)、確率分布(random)、離散型フーリエ変換(fft)、マトリックス変換などである。NumPyには、通常の数学的関数、例えば、三角関数、指数・対数関数、簡単な統計計算などが組み込まれていて、簡単に利用できる。組込み関数として、三角関数関係では、sin(), cos(), tan(), arcsin(), arccos(), arctan(), sinh(), cosh(), tanh()など、対数、指数関数関係では、exp(), log(), log10(),等が使用できる。例えば、\( \sin(\pi/2) \)の計算は
np.sin(np.pi/2)
とすれば、答えは1.0と返されます。指数関数はexp(..)、自然対数はlog(..)という組込み関数を使用できる。
np.exp(2.0) np.log(12.5) ---- 結果 7.38905609893065 2.5257286443082556
numpyの組込み関数 'array' を使って、4つの数値が要素となっている配列データ(1,2,3,4)を内容とする変数(オブジェクト)を定義してみましょう。さらに、(10, 20, 30, 40)という1次元ベクトル(横ベクトル)をAとして定義しましょう。
a = np.array([1,2,3,4]) A = np.array([10,20,30,40])
と入力すれば良い。
行列計算に必要な組込み関数および操作方法について説明します。行列の積などの計算をするためには、数値をマトリックスの形式で表現する必要があります。Scipy/Numpyでは、n次元配列表現(ndarray)と呼ばれる、一般的な配列表現(リスト型変数)を採用しています。マトリックス配列(2次元配列)はそのスペシャル・ケースになる。行列を定義したいときには、例えば、
B = np.array([[1.0, 1.0],[0.0, 1.0]]) C = np.array([[2.,0.],[3.,4.]])
とすればよい。ちなみに、行列B、Cは \[ B = \begin{bmatrix} 1.0 & 1.0 \\ 0.0 & 1.0 \end{bmatrix} , C =\begin{bmatrix} 2.0 & 0.0 \\ 3.0 & 4.0 \end{bmatrix} \] となっている。配列を作成する組込み関数は、array、range、arange、linspaceに限定されません。以下のような組込み関数が用意されています。
D = np.zeros((3,4)) E = np.ones((3,4)) F = np.eye(4) G = np.diag((3,4)) H = np.empty((3,4)) D.ndim E.shape F.size ---- 結果 2 (3,4) 16
zeros((n,m)) はすべての要素をゼロとするn行m列の行列を作成し、ones((n,m)) はすべての要素と1とするn行m列の行列を作成、eye(n) はn行n列の単位行列を作成する。これらはすべて浮動小数点の数値で与えられる。さらに、各変数 ndarray に対して、ndarray.ndim、 ndarray.shape、 ndarray.size、 ndarray.dtype などのような操作をすることができる。
n次元配列表現では、加算、引き算、乗除の操作は必ず配列の要素ごとの計算になる。だから、行列の和と差の計算は、数値の加算、減算と同じように問題なく計算できる。例えば、
B + C B * C np.dot(B,C) ---- 結果 array([[3., 1.], [3., 5.]]) array([[2., 0.], [0., 4.]]) array([[5., 4.], [3., 4.]])
という計算ができます。注意が必要なのは、行列の積を計算するときである。B * C と入力すると、答えは要素ごとの積になります。通常の行列の積を計算するためには、np.dot(A,B) とNumpyの組込み関数を用いて入力する必要があります。Numpyで使用可能な組込み関数の一覧表は https://numpy.org/doc/にあります。
次に、Matplotlibの使用法について説明します。英文公式ホームページは https://matplotlib.org/にあります。
スクリプトの始めに 'matplotlib.pyplot as plt' と記述すると、pltという略称名の下でmatplotlibに組み込まれている様々なグラフィック機能の命令が利用できます。言い換えると、matplotlib.pyplot というモジュール名の代わりに plt というモジュール名を用いることを宣言している。ここで、三角関数のグラフを描くソース・コードを書いたテキスト・ファイルを作成する方法を説明します。以下のようなテキスト・ファイルを作ります。plt.plot(...) は、モジュール matplotlib.pyplot に組み込まれたプロット関数 plot を表現します。モジュールmatplotlib.pyplot に組み込まれた関数 f_n を用いるときは、plt.f_n という形式で命令文を記述します。
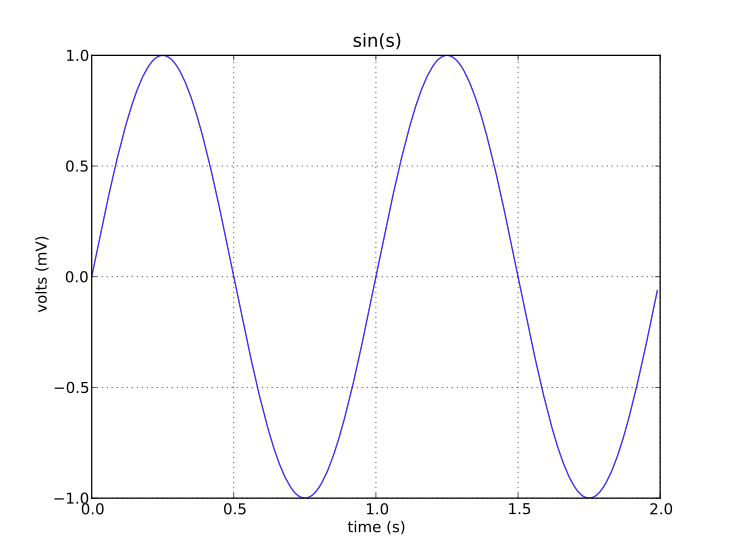
#an example of matplotlib usage
import numpy as np
import matplotlib.pyplot as plt
t = np.arange(0.0, 2.0, 0.01)
s = np.sin(2*np.pi*t)
plt.plot(t, s)
plt.title('sin(s)')
plt.xlabel('time (s)')
plt.ylabel('volts (mV)')
plt.grid(True)
plt.show()
このファイルを拡張子.pyを付けて保存する。または、Jupyter Notebookにコピペします。このプログラムを実行すると、sin関数のグラフが描かれます。import numpy as np は、numpy 内のすべての組み込み関数を np という略称で使用するという宣言です。np.arange(0.0, 2.0, 0.01) は0.0 から 2.0のまでの数値を刻み幅 0.01 で数列化する numpy の組み込み関数です。最後の命令 plt.show() はグラフをデスクトップに表示させるために必要で、これを書かないとグラフは表示されません。
plt.grid(True) はグラフのグリッド線を表示させるための命令です。グリッド線を表示させないときは、この命令を削除すればよい。plt.plot(t,s) は横軸にt、縦軸にsを描いたグラフを出力させる命令です。変数tは数直線[0,2]上に、間隔距離が0.01で並んだ数値からなる配列で、変数sはそれらの200個の数値に対応する1次元配列となっている。タイトル、横軸ラベルまたは縦軸ラベルの表示の仕方は説明を必要とするまでもないでしょう。以下のグラフは、実際にこのソース・コードを実行した場合の結果です。
ファイルを保存して、[File]-[Close and Halt]とクリックして、NoteBookを終了してください。最後に、ターミナルで[Ctrl+c]を入力して、Notebookのカーネルも閉じます。
matplotlibの出力グラフをJupyterのセル上に表示させる為には、スクリプトの第1行目に
%matplotlib inline
と記述します。上の例で見た通り、この記述がなくても表示されるようです。
以下にあるスクリプトファイルをコピペして、実行してみて下さい。
"""
Demo of a basic pie chart plus a few additional features.
In addition to the basic pie chart, this demo shows a few optional features:
* slice labels
* auto-labeling the percentage
* offsetting a slice with "explode"
* drop-shadow
* custom start angle
Note about the custom start angle:
The default ``startangle`` is 0, which would start the "Frogs" slice on the
positive x-axis. This example sets ``startangle = 90`` such that everything is
rotated counter-clockwise by 90 degrees, and the frog slice starts on the
positive y-axis.
"""
import matplotlib.pyplot as plt
# The slices will be ordered and plotted counter-clockwise.
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs'
sizes = [15, 30, 45, 10]
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral']
explode = (0, 0.1, 0, 0) # only "explode" the 2nd slice (i.e. 'Hogs')
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=90)
# Set aspect ratio to be equal so that pie is drawn as a circle.
plt.axis('equal')
plt.show()
結果はこうなります。
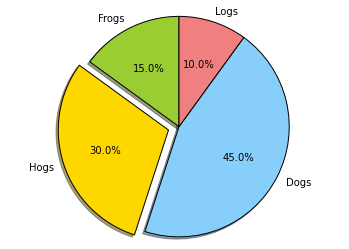
Matplot_Pie__demo
次のスクリプトをNotebookにコピペして実行してください。
"""
Demo of a PathPatch object.
"""
import matplotlib.path as mpath
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
Path = mpath.Path
path_data = [
(Path.MOVETO, (1.58, -2.57)),
(Path.CURVE4, (0.35, -1.1)),
(Path.CURVE4, (-1.75, 2.0)),
(Path.CURVE4, (0.375, 2.0)),
(Path.LINETO, (0.85, 1.15)),
(Path.CURVE4, (2.2, 3.2)),
(Path.CURVE4, (3, 0.05)),
(Path.CURVE4, (2.0, -0.5)),
(Path.CLOSEPOLY, (1.58, -2.57)),
]
codes, verts = zip(*path_data)
path = mpath.Path(verts, codes)
patch = mpatches.PathPatch(path, facecolor='r', alpha=0.5)
ax.add_patch(patch)
# plot control points and connecting lines
x, y = zip(*path.vertices)
line, = ax.plot(x, y, 'go-')
ax.grid()
ax.axis('equal')
plt.show()
以下のような面白いアニメーション・グラフが描けます。
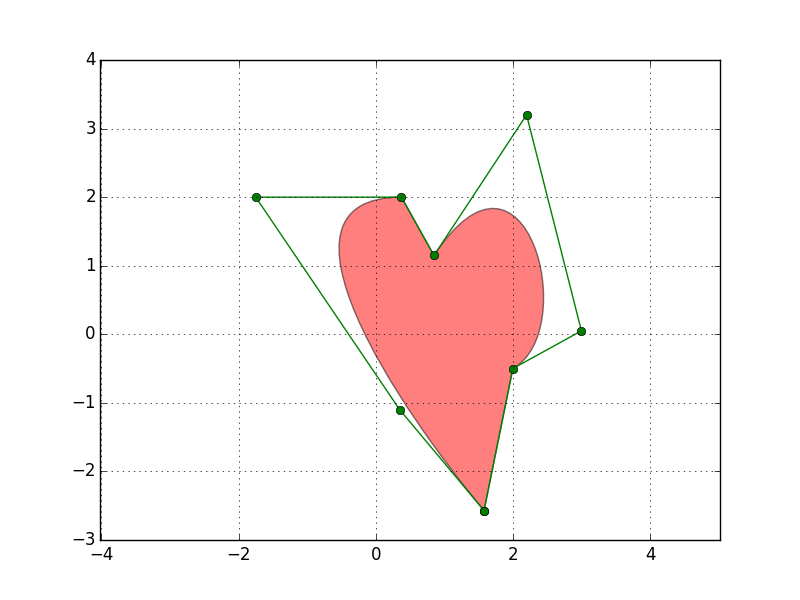
Matplot_Path_patch_demo
次の例はグラフに数式を書き込むことです。数式の書き込みは当然のことながらLaTexの書式を使用します。以下のスクリプトをコピペして実行してください。
#coding:utf-8
# Tex_demo.py
import numpy as np
import matplotlib.pyplot as plt
t = np.arange(0.0, 2.0, 0.01)
s = np.sin(2*np.pi*t)
plt.plot(t, s)
plt.title(r'$\alpha_i >\beta_i$', fontsize=20)
plt.text(1, -0.6, r'$\sum_{i=0}^\infty x_i$', fontsize=20)
plt.text(0.6, 0.6, r'$\mathcal{A} \cdot\mathrm{sin}(2 \omega t)$', fontsize=20)
plt.xlabel('time (s)')
plt.ylabel('volts (mV)')
plt.grid(True)
plt.show()
結果はこうなります。
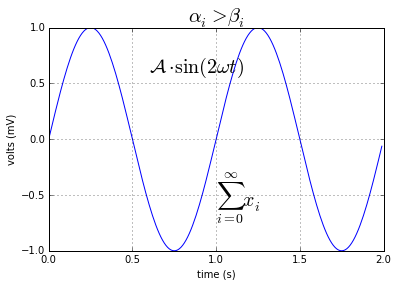
Matplot_Tex__demo
以下の例は一つのグラフに2つのsubplotを描いたグラフを描いた例です。ソースコードが以下になります。それをコピペして実行して見てください。
"""
Simple demo with multiple subplots.
"""
import numpy as np
import matplotlib.pyplot as plt
x1 = np.linspace(0.0, 5.0)
x2 = np.linspace(0.0, 2.0)
y1 = np.cos(2 * np.pi * x1) * np.exp(-x1)
y2 = np.cos(2 * np.pi * x2)
plt.subplot(2, 1, 1)
plt.plot(x1, y1, 'yo-')
plt.title('A tale of 2 subplots')
plt.ylabel('Damped oscillation')
plt.subplot(2, 1, 2)
plt.plot(x2, y2, 'r.-')
plt.xlabel('time (s)')
plt.ylabel('Undamped')
plt.show()
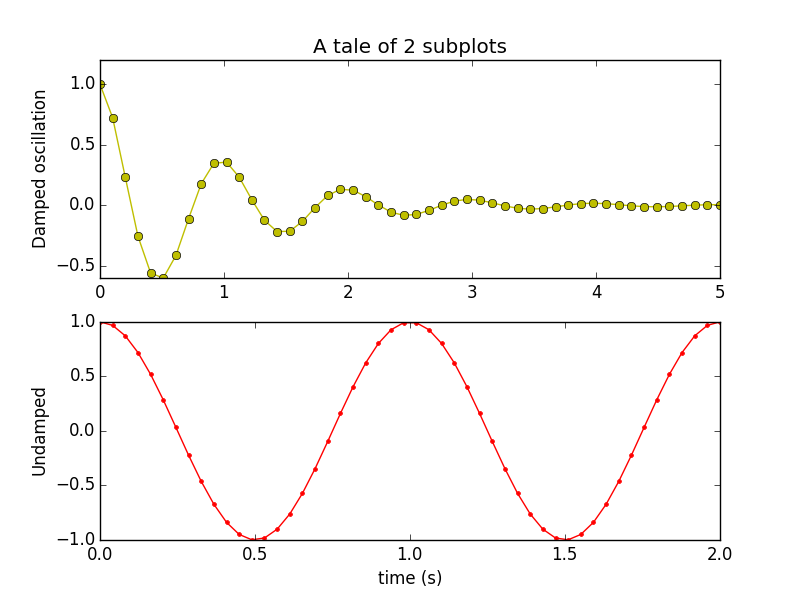
Subplot_demo
以下の例は3次元のグラフを描いた例です。ダウンロード用のsource code は以下のファイルです。
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
from matplotlib.ticker import LinearLocator
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure()
ax = fig.gca(projection='3d')
X = np.arange(-5, 5, 0.25)
xlen = len(X)
Y = np.arange(-5, 5, 0.25)
ylen = len(Y)
X, Y = np.meshgrid(X, Y)
R = np.sqrt(X**2 + Y**2)
Z = np.sin(R)
colortuple = ('y', 'b')
colors = np.empty(X.shape, dtype=str)
for y in range(ylen):
for x in range(xlen):
colors[x, y] = colortuple[(x + y) % len(colortuple)]
surf = ax.plot_surface(X, Y, Z, rstride=1, cstride=1, facecolors=colors,
linewidth=0, antialiased=False)
ax.set_zlim3d(-1, 1)
ax.w_zaxis.set_major_locator(LinearLocator(6))
plt.show()
このコードを実行すると、以下のような表示が得られれます。
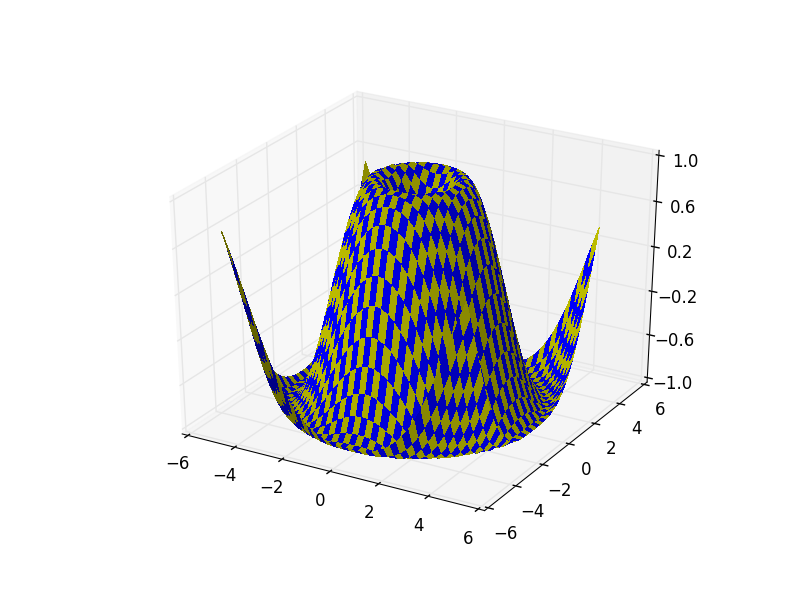
Matplot_Surface3d3_demo
機械学習で必須の記述様式 |
機械学習の Python 実装において頻繁に登場するスクリプト記述の代表的なモジュールを取り上げます。最初に、コマンドライン引数について説明します。機械学習のスクリプトでは、よくコマンドライン引数を扱う必要があります。コマンドライン引数は sys モジュールの args 属性にリストとして保存されます。argparse は、Python 標準ライブラリの一部であり、おすすめのコマンドライン引数の解析モジュールです。次のスクリプトを見て下さい。ArgumentParser.add_argument() メソッドは各引数の仕様をパーサーに付属させます。このメソッドは位置引数、値を受け取るオプション、機能のオン/オフを切り替えるフラグをサポートします。ArgumentParser.parse_args() メソッドはパーサーを実行し、抽出したデータを argparse.Namespace オブジェクト内に配置します。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--images", dest = 'images', help = "Image / Directory containing images to perform detection upon", default = "imgs", type = str)
parser.add_argument("--det", dest = 'det', help = "Image / Directory to store detections to", default = "det", type = str)
parser.add_argument("--reso", dest = 'reso', help = "Input resolution of the network.", default = "416", type = str)
args = parser.parse_args()
上記の argparse が記述されたスクリプトが物体検出のためのプログラムである detect.py だとすると、以下のようにコマンドライン引数を指定して実行します。
$python detect.py --images imgs --det det --reso 320
--images flag は検出対象の画像ファイルの指定をします。ここでは、 'imgs' に画像が入っています。--det は検出済みの画像ファイルを保存するフォルダーを指定します。'det' というフォルダーになっています。320 は入力画像の解像度です。
次に、 os モジュールについて説明します。階層構造の頂点 (ルートディレクトリ) を起点に目的のファイルやディレクトリまでの経路情報をすべて記述したパスを 絶対パスまたは フルパス とよびます。現在位置を起点とした位置を示したのが相対パスです。現在位置(カレントディレクトリ)とは、プログラムを実行しているのであれば、そのプログラムを実行中のフォルダとなります。os.path.abspath() に文字列を渡すと、作業フォルダの絶対パスに文字列を連結したパスを生成します。例として、作業中のディレクトリに「hello.txt」というファイル作成し、その内容を読み込んで表示します。ファイルのパスは 、絶対パスで指定しています。
import os
# 絶対パスを取得
file = os.path.abspath("hello.txt")
print(file)
# 絶対パスにあるファイルに書き込
f = open(file, "w")
f.write("こんにちは")
f.close()
# 絶対パスにあるファイルの内容を表示
f = open(file)
text = f.read()
f.close()
print(text)
これを実行すると、print(file) で hello.txt のあるディレクトリまでの絶対パスが表示され、print(text) でこのファイルの内容が表示されます。実行中のカレントディレクトリを得るには、os.getcwd()を使います。以下に例を示します。
os.getcwd()
ディレクトリを移動するには、os.chdir()を使います。os.chdir(path)は path で表されるディレクトリをカレントディレクトリにします。この関数の記述子は、オープンしているファイルではなく、オープンしているディレクトリを参照していなければなりません。
# カレントディレクトリを object_detection に変更
os.chdir('object_detection')
# 確認
print(os.getcwd())
os.path.join() に複数の文字列を渡すと、区切り文字を使ってパスを組み立てます。
path = os.path.join("..", "pytorch")
img_path = os.path.join("..", "pytorch", "object_detection")
img_path は "../pytorch/object_detection" になります。
物体検出の Google Colab コードでよく見られる例は以下のようなものです。
!git clone https://github.com/mashyko/pytorch_ssd
import os
import sys
os.chdir('pytorch_ssd') # /content/pytorch_ssd に移動します
!ls # pytorch_ssd の内容を表示
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
少し変わった例をあげます。
os.path.join(os.path.abspath(os.path.dirname(__file__))
このコードでは、"__file__"で実行中のファイルを示し、 "os.path.dirname"で実行ファイルの相対パスを示し "os.path.abspath"でこのパスを絶対パスに変換しています。なお、Jupyter Notebook では__file__は使えないので注意が必要です。
特定のディレクトリにどんなファイルやディレクトリが含まれているかを調べるには、os.listdir関数あるいはos.scandir関数を使用します。
os.listdir(path='.') os.scandir(path='.')
os.listdir関数はpathで表されるディレクトリに含まれるファイルやディレクトリの名前を要素とするリストを返します。pathを省略すると、カレントディレクトリに含まれるファイルやディレクトリの名前を含んだリストが返されます。
CNN への入力データの前処理において、辞書内包表記が頻繁に使用されます。辞書内包表記の基本的な記述方法は以下のようにします。
{key:value for 配列内要素 in 配列}
最終的に辞書を生成しますので { } で挟み、新に格納する要素の key:value を最初に記述し、その後は通常のfor文と同じです。リスト内包表記の時とはカッコの形状と key:value 形式が変わります。以下のコードがその例です。
keys = ['a', 'b', 'c']
values = [10, 20, 30]
dicts = {key:value for key, value in zip(keys, values)}
print(dicts)
----- # 以下のような辞書が生成される
{'a': 10, 'b': 20, 'c': 30}
物体検出の PyTorch コードでよく見られる辞書内包表記の例は以下のようなものです。
data_dir = 'hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
複雑に見えますが、上記の例に対応させると、x -> key 、 datsets.ImageFolder() -> value になっています。
C++ と同様に、Python はオブジェクト指向言語なので、クラスという概念を使います。上の節でクラスについて簡単に説明しました。クラスとは、何らかのデータ(インスタンス変数)と、それらを処理するためのコード(メソッド)をひとまとめにして名前を付けることで、後からそれらを再利用するための仕組みです。なお、モジュールやパッケージでクラスを定義すれば、それらももちろんインポートして利用できるようになります。
親クラスのメソッドを子クラスでも使いつつ、新たにパラメーターやメソッドを追加する場合は、スーパークラス super() が便利です。super() は親クラスのメソッドを継承します。
class Animals(object):
def __init__(self, name):
self.name = name
class Dog(Animals):
def __init__(self, name, function):
super(Dog, self).__init__(name)
self.function = function
dog1 = Animals('犬')
dog2 = Dog('Ken', '泳ぐ')
dog3 = Dog('John','飛ぶ')
print('動物の種類は{}です。'.format(dog1.name))
print('{}の名前は{}です。特技は{}ことです。'.format(dog1.name, dog2.name, dog2.function))
print('{}の名前は{}です。特技は{}ことです。'.format(dog1.name, dog3.name, dog3.function))
--- # result
動物の種類は犬です。
犬の名前はKenです。特技は泳ぐことです。
犬の名前はJohnです。特技は飛ぶことです。
親クラス Animals のメソッド self.name が子クラス Dog に継承されています。__call__ メソッドを用いた例をあげます。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hello(self, name):
print("こんにちは"+ name + "さん、私は" + self.name + " です。(say_helloメソッド)")
def __call__(self, name):
print("こんにちは"+ name + "さん、私は" + self.name + " です。(callメソッド)")
tanaka = Person("田中",100)
tanaka.say_hello("佐藤")
tanaka("佐藤")
------ # result
こんにちは佐藤さん、私は田中 です。(say_helloメソッド)
こんにちは佐藤さん、私は田中 です。(callメソッド)
__call__ メソッドは特殊なメソッドで、上の例に見られるように、インスタンスを関数として使用できるようになります。インスタンス tanaka() が関数となっています。
画像分類のモデルを作成するコードでは、以下のような利用法が見られます。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 64, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
model = Model()
model
このコードは PyTorch で簡単な2層ネットワークの構造を定義する例です。こうした記述はディープラーニングにおける CNN の作成では必須の技法です。Python の公式マニュアルでは、クラスの定義に関する詳細な説明がありますが、言葉が難解でよく理解できません。具体的なコードを読んで理解する方が近道でしょう。
最後に、画像を読み込んで表示する方法について説明します。PIL モジュールを使用する例を示します。
# パッケージのimport from PIL import Image import matplotlib.pyplot as plt # 画像読み込み image_file_path = 'images/cat.jpg' img = Image.open(image_file_path) # 画像の形状:[高さ][幅][色RGB] # 画像の表示 plt.imshow(img) plt.show()
以下のような画像が表示されます。OpenCV を用いて画像を読み込む方法もあります。この場合、色のチャネルの順序がBGR で読み込まれますので、 RGB に変換する必要があります。
