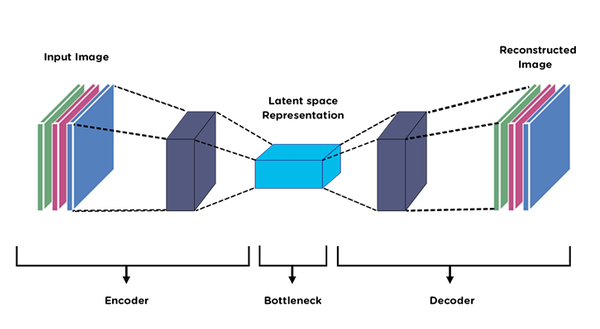
Autoencoderの構成
Anomaly Detection |
異常検知( anomaly detection)や外れ値検知( outlier detection)とは、収集したデータから、期待されるパターンとは異なった物体や出来事及び観測結果を識別することです。通常、ここで言う異常検知とは、銀行詐欺、クレジットカード不正利用、構造欠陥、医学的な問題、文書中の誤り検出、不審な行動検出、機械の故障検知などの問題です。なお、異常(anomaly)は、外れ値(outlier)、珍しい物(novelty)、雑音(noise)、変動(deviation)、例外(exception)などとも言われている。
異常検知の技術は、主に、Webサービスの不正アクセスや金融機関の不正利用などを防止する目的に利用されたり、工場の稼働データの中から異常値を検出して、不具合や故障を検知する目的で使用されています。大量データの収集・蓄積が可能である場合、機械学習やDeep Learningによる分析が実施しやすくなります。しかし、製造業には、異常検知技術を活用するポテンシャルが大きいですが、不良品が元々少ないので、アノテーション付き不良品データを大量に収集することが難しい現状にあります。
こうした状況では、画像識別のような教師ありのアルゴリズムは適用できません。一方で,工場などの製造現場では,大量に「正常」なデータが取得できます。この大量のラベルなしデータを用いて,「異常検知」を実現するためにDeep Learningの手法を活用することが有効になります。従来の統計学的な手法を用いた異常感知のモデルにとって代わり、Deep learning のモデルを用いた異常検知のアルゴリズムが急速に進歩しています。とりわけ、AutoencoderやGAN(Generative Adversarial Networks)といったコンピュータビジョンのDeep Learning モデルが積極的に応用されています。
このページでは、anomaly detection の Deep Learning モデルをPython 実装する手順について解説します。特に、画像イメージから異常形状を検出するケースに適用できるモデルを取り上げます。当然のことながら、モデルの学習(トレーニング)を実行するので、GPUの活用は必要不可欠です。以下で説明するコードは、Google ColabのGPUを利用しています。
Last updated:2021.4.18 (first uploaded: 2021.4.11)
Autoencoder を用いた anomaly detection |
autoencoder(自己符号化器)とは、2006年にジェフリー・ヒントンによる、ディープラーニングにおけるニューラルネットワークの仕組みの一つです。エンコーダとデコーダからなるニューラルネットワークであり、分類だけでなく生成も可能です。仕組みとしては、入力層と出力層のノード数が同じで、中間層の数がそれよりも少ない3層のニューラルネットワークのうち、特に出力を入力に近づけるための学習が行われます。オートエンコーダは、異常検知、クレンジング(ノイズ除去)、クラスタリングなどの次元削減に応用されます。
最近では、Covolutional Autoencoder の適用が多くなっています。畳み込みAutocoderとは、畳み込みニューラルネットワーク(CNN)を用いたAutoencoderです。CNNとは、入力層と出力層の間に、入力データの特徴量を捉える畳み込み層と、その特徴への偏りを減らすプーリング層を加えたニューラルネットワークのモデルです。畳み込み層により特徴を抽出できるため、特徴を検知することを目的とした画像の処理に利用されることが多いです。
Autoencoderの構成
この節では、autoencoder を利用した anomaly detection のアルゴリズムをPython API のPytorch を用いて実装したコード例を取り上げます。こちらの解説が分かりやすいです。以下のような説明があります。
「異常検知の目的は,入力データに対してモデルが「正常」か「異常」かを認識することにあります.この問題設定は,よく用いられる教師あり学習でのパターン認識の枠組みですが,残念ながら異常検知が実際に応用される工場など(外観検査)の多くは,異常データが集まらないのが普通です.
そのため,パターン認識のような教師ありのアプローチは適用できません.
しかし,一般に工場などの現場では,大量に「正常」なデータが取得できます.これを活用して,「異常検知」に落とし込むために,Autoencoderが登場します.
上記までで説明した通り,Autoencoderでは高次元のデータの分布から,特徴を抽出して低次元の潜在空間へと写像することができます.
つまり,大量の正常データを用いてモデルを学習することで,正常なデータの特徴を獲得できます.このことから,「正常」なデータをモデルに入力すれば,もちろんdecoderは元の入力を復号できるでしょう.しかし「異常」なデータが入力されたとき,これは異常なデータを表現できる特徴を獲得していないので,うまく復号することができません.
このトリックを用いて異常検知が行われます.具体的には,入出力間で差分をとり,それを異常度として計算することで異常が検知できます.」
最初に、最もシンプルなコードを紹介します。MNIST(手書き数字のデータセット)を用いて異常検知をします。MNISTの有する0~9のうち,「1」のラベルがついたものを正常データとして学習します。そして,「9」のラベルがついたものを異常データとして,これを検知できるかどうかを検証します。
autoencoder をMNISTで訓練した後に、MNISTの再構成精度を異常度として検知を試みます。Pytorch におけるautoencoder のコードは以下のような簡単なネットワークで構成できます。
class Autoencoder(nn.Module):
def __init__(self,z_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.ReLU(True),
nn.Linear(256, 128),
nn.ReLU(True),
nn.Linear(128, z_dim))
self.decoder = nn.Sequential(
nn.Linear(z_dim, 128),
nn.ReLU(True),
nn.Linear(128, 256),
nn.ReLU(True),
nn.Linear(256, 28 * 28),
nn.Tanh()
)
def forward(self, x):
z = self.encoder(x)
xhat = self.decoder(z)
return xhat
学習は入出力間のMSEをとり,これを最小化することで入力を再構成するように学習させます。プログラム全体はanomaly-detection-using-autoencoder-PyTorchにあります。以下にコード全体を示します。
MNISTデータセットを用いた、もう少し一般的な anomaly detection のPython 実装は以下のコードです。 この時 autoencoder のネットワークは以下になります。
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
self.enc = nn.Sequential(
nn.Linear(784, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU()
)
self.dec = nn.Sequential(
nn.Linear(16, 32),
nn.ReLU(),
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 784),
nn.ReLU()
)
def forward(self, x):
encode = self.enc(x)
decode = self.dec(encode)
return decode
このプログラムはこのGoogle Colabで実行できます。このプログラムは、MNISTデータをcsvファイルの形式で読み込む必要があるので、このMNIST in CSVからダウンロードしてください。
import random
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('mnist_test.csv')
anom = df[:1000]
clean = df[1000:]
for i in range(len(anom)):
# select row from anom
row = anom.iloc[i]
# iterate through each element in row
for i in range(len(row)-1):
# add noise to element
row[i+1] = min(255, row[i+1]+random.randint(100,200))
このコードを実行して、anomに配置されたて画像に雑音を上書きして、異常画像とします。異常画像は1000枚です。cleanに配置された画像はそのままなので、正常画像とします。以下のように、上記で定義したautoencoder AE を用いて、学習をします。
metrics = defaultdict(list)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = AE()
model.to(device)
criterion = nn.MSELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=w_d)
model.train()
start = time.time()
for epoch in range(epochs):
ep_start = time.time()
running_loss = 0.0
for bx, (data) in enumerate(train_):
sample = model(data.to(device))
loss = criterion(data.to(device), sample)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
epoch_loss = running_loss/len(train_set)
metrics['train_loss'].append(epoch_loss)
ep_end = time.time()
print('-----------------------------------------------')
print('[EPOCH] {}/{}\n[LOSS] {}'.format(epoch+1,epochs,epoch_loss))
print('Epoch Complete in {}'.format(timedelta(seconds=ep_end-ep_start)))
end = time.time()
print('-----------------------------------------------')
print('[System Complete: {}]'.format(timedelta(seconds=end-start)))
異常画像を用いて、loss distributionを計算します。
model.eval()
loss_dist = []
anom = pd.read_csv('anom.csv', index_col=[0])
#for bx, data in enumerate(test_):
for i in range(len(anom)):
data = torch.from_numpy(np.array(anom.iloc[i][1:])/255).float()
sample = model(data.to(device))
loss = criterion(data.to(device), sample)
loss_dist.append(loss.item())
正常画像と異常画像のloss distribution のグラフを描くと以下のようになります。
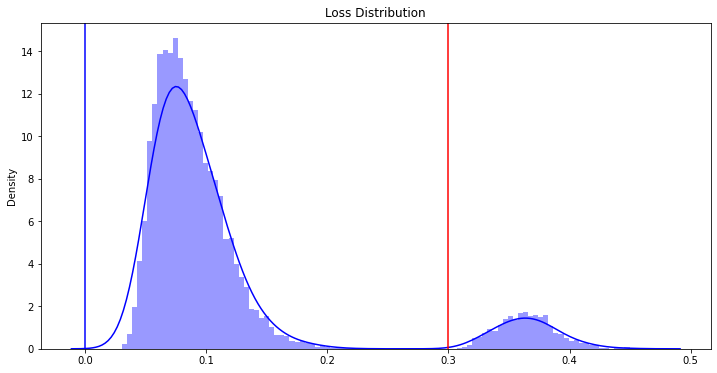
loss distribution
赤色の直線の右側に存在する範囲のものは、異常画像と判定されるものに対応します。Colabでの実行から得られる結果によれば、最終的に、異常画像を正しく異常と判定した個数は1000個、正常画像を正常と認識した個数は9000個でした。100%正しく判定しました。素晴らしい結果です。ただし、データはMNISTなので、小さなサイズの白黒画像です。
GANsモデルを用いたanomaly detection:MNISTデータ |
GANsモデルを用いたanomaly detection は大きく分類すると3種類になります。AnoGAN、EfficentGAN、GANomalyです。
AnoGANは論文Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discoveryで提案されたアルゴリズムです。GAN(Generative Adversarial Networks)を用いた生成モデルの手法を異常検知の問題に適用した手法で、この分野では先駆け的なモデルです。一般にGANでは潜在変数という、生成される画像のもととなる変数があります。AnoGANでは、この潜在変数から学習に使う正常画像を生成できるようにモデル(Generator)を学習します。テスト時には、入力画像に対する潜在変数が分からないため、潜在空間の探索を行うことで対応する潜在変数を見つけて画像を生成します。
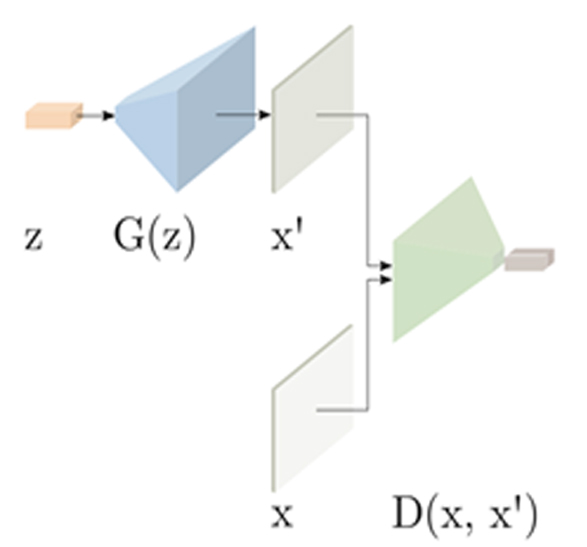
AnoGANの構成
EfficientGANは、Efficient GAN-Based Anomaly Detectionと言う論文で提案されました。前述のAnoGANでは潜在空間に仮定をおいていないため、テストの度に潜在空間内で探索を行うことが必要です。そのため非常にコストがかかるという問題がありました。EfficientGANでは画像を生成するモデル(Generator)に加えて画像に対応する潜在変数を出力するモデル(Encoder)を用意します。そして Encoder と Generator を同時に学習することで、画像と潜在変数の対応付けができるようになります。 テスト時には Encoder を用いることで入力画像に対する潜在変数を特定することができ、それを元に画像の生成を行うことでテストにかかる処理時間を大幅に短縮しています。
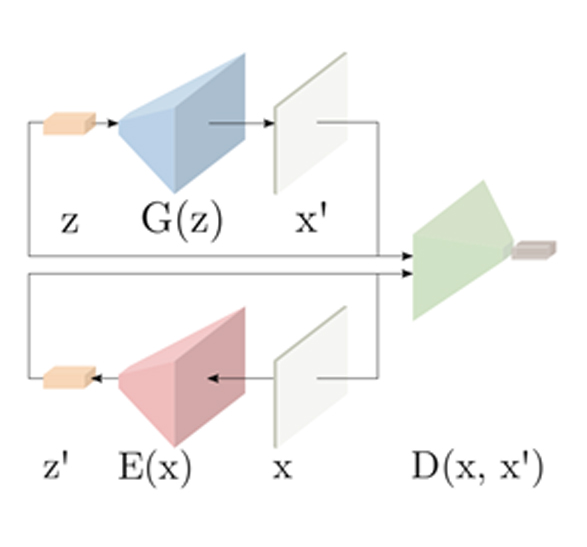
EfficientGANによる検知
GANomalyは論文Semi-Supervised Anomaly Detection via Adversarial Trainingで提案された。GANomaly ではGANの敵対的な構造に加えて AutoEncoder のネットワークを導入します。AutoEncoderは画像の圧縮と復元を行い、ノイズの除去や次元の圧縮などに利用されます。AutoEncoderとGANの構造を組み合わせ、潜在空間をAutoEncoderの圧縮された特徴表現によって構成しています。入力画像を圧縮したものを潜在変数とするため、比較的安定した画像の生成と潜在空間の構成が可能となると言われています。
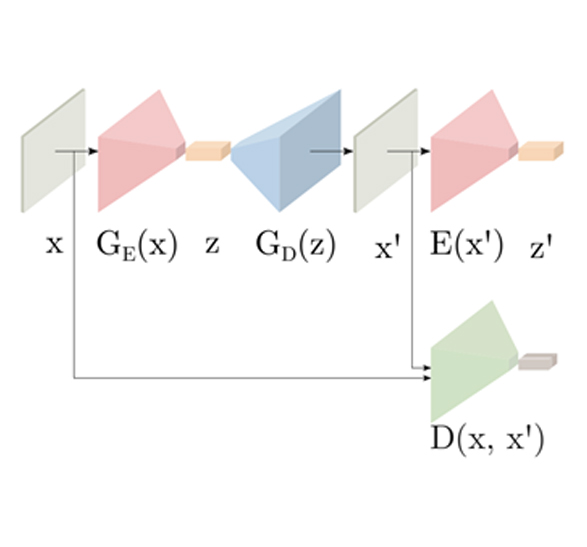
GANomalyによる検知
最初に、Efficient GANを用いたanomaly detectionのpython実装を取り上げます。使用するデータはMNISTデータセットです。以下で紹介するコードは、「つくりながら学ぶ! PyTorchによる発展ディープラーニング」(小川雄太郎、マイナビ出版 、19/07/29) の第6章で用いられているPytorch コードを改変したものです。コード全体はこのGoogle Colabにあります。
MNISTデータをダウンロードします。
import os
import urllib.request
import zipfile
import tarfile
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import Image
import numpy as np
import sklearn
data_dir = "./data/"
if not os.path.exists(data_dir):
os.mkdir(data_dir)
from sklearn.datasets import fetch_openml
X, y = fetch_openml('mnist_784', data_home="./data/") # data_homeは保存先を指定します
手書き数字のうち、ラベルが[7, 8]のデータを学習用データとして使用するので、フォルダ「data」の下にフォルダ「img_78」を作成して、それらをその下に保存します。フォルダ「data」の下にフォルダ「test」を作成して、その中に検出用のデータを保存します。詳細なコードはColabをみてください。画像のサイズは 28x28 です。
Generatorの実装は以下の通りです。
class Generator(nn.Module):
def __init__(self, z_dim=50):
super(Generator, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(z_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(inplace=True))
self.layer2 = nn.Sequential(
nn.Linear(1024, 7*7*128),
nn.BatchNorm1d(7*7*128),
nn.ReLU(inplace=True))
self.layer3 = nn.Sequential(
nn.ConvTranspose2d(in_channels=128, out_channels=64,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
self.last = nn.Sequential(
nn.ConvTranspose2d(in_channels=64, out_channels=1,
kernel_size=4, stride=2, padding=1),
nn.Tanh())
# 注意:白黒画像なので出力チャネルは1つだけ
def forward(self, z):
out = self.layer1(z)
out = self.layer2(out)
# 転置畳み込み層に入れるためにテンソルの形を整形
out = out.view(z.shape[0], 128, 7, 7)
out = self.layer3(out)
out = self.last(out)
return out
# 動作確認
import matplotlib.pyplot as plt
%matplotlib inline
G = Generator(z_dim=20)
G.train()
# 入力する乱数
# バッチノーマライゼーションがあるのでミニバッチ数は2以上
input_z = torch.randn(2, 50)
# 偽画像を出力
fake_images = G(input_z) # torch.Size([2, 1, 28, 28])
Discriminatorの実装は以下の通りです。
class Discriminator(nn.Module):
def __init__(self, z_dim=50):
super(Discriminator, self).__init__()
# 画像側の入力処理
self.x_layer1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=4,
stride=2, padding=1),
nn.LeakyReLU(0.1, inplace=True))
# 注意:白黒画像なので入力チャネルは1つだけ
self.x_layer2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=4,
stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.1, inplace=True))
# 乱数側の入力処理
self.z_layer1 = nn.Linear(z_dim, 512)
# 最後の判定
self.last1 = nn.Sequential(
nn.Linear(3648, 1024),
nn.LeakyReLU(0.1, inplace=True))
self.last2 = nn.Linear(1024, 1)
def forward(self, x, z):
# 画像側の入力処理
x_out = self.x_layer1(x)
x_out = self.x_layer2(x_out)
# 乱数側の入力処理
z = z.view(z.shape[0], -1)
z_out = self.z_layer1(z)
# x_outとz_outを結合し、全結合層で判定
x_out = x_out.view(-1, 64 * 7 * 7)
out = torch.cat([x_out, z_out], dim=1)
out = self.last1(out)
feature = out # 最後にチャネルを1つに集約する手前の情報
feature = feature.view(feature.size()[0], -1) # 2次元に変換
out = self.last2(out)
return out, feature
# 動作確認
D = Discriminator(z_dim=50)
# 偽画像を生成
input_z = torch.randn(2, 50)
fake_images = G(input_z)
# 偽画像をDに入力
d_out, _ = D(fake_images, input_z)
Encoderの実装は以下の通りです。
class Encoder(nn.Module):
def __init__(self, z_dim=50):
super(Encoder, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3,
stride=1),
nn.LeakyReLU(0.1, inplace=True))
# 注意:白黒画像なので入力チャネルは1つだけ
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3,
stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.1, inplace=True))
self.layer3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3,
stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.1, inplace=True))
# ここまでで画像のサイズは7×7になっている
self.last = nn.Linear(128 * 7 * 7, z_dim)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
# FCに入れるためにテンソルの形を整形
out = out.view(-1, 128 * 7 * 7)
out = self.last(out)
return out
# 動作確認
E = Encoder(z_dim=50)
# 入力する画像データ
x = fake_images # fake_imagesは上のGで作成したもの
# 画像からzをEncode
z = E(x)
フォルダ data/img_78/ にある学習用のデータセットをPytorch形式の dataloaderに変換する必要があります。この変換のためのコードの説明は省略しますが、dataloaderはtorch.Size([64, 1, 28, 28])になっています。これを学習させます。
# モデルを学習させる関数を作成
def train_model(G, D, E, dataloader, num_epochs):
# GPUが使えるかを確認
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用デバイス:", device)
# 最適化手法の設定
lr_ge = 0.0001
lr_d = 0.0001/4
beta1, beta2 = 0.5, 0.999
g_optimizer = torch.optim.Adam(G.parameters(), lr_ge, [beta1, beta2])
e_optimizer = torch.optim.Adam(E.parameters(), lr_ge, [beta1, beta2])
d_optimizer = torch.optim.Adam(D.parameters(), lr_d, [beta1, beta2])
# 誤差関数を定義
# BCEWithLogitsLossは入力にシグモイド(logit)をかけてから、
# バイナリークロスエントロピーを計算
criterion = nn.BCEWithLogitsLoss(reduction='mean')
# パラメータをハードコーディング
z_dim = 50
mini_batch_size = 64
# ネットワークをGPUへ
G.to(device)
E.to(device)
D.to(device)
G.train() # モデルを訓練モードに
E.train() # モデルを訓練モードに
D.train() # モデルを訓練モードに
# ネットワークがある程度固定であれば、高速化させる
torch.backends.cudnn.benchmark = True
# 画像の枚数
num_train_imgs = len(dataloader.dataset)
batch_size = dataloader.batch_size
# イテレーションカウンタをセット
iteration = 1
logs = []
# epochのループ
for epoch in range(num_epochs):
# 開始時刻を保存
t_epoch_start = time.time()
epoch_g_loss = 0.0 # epochの損失和
epoch_e_loss = 0.0 # epochの損失和
epoch_d_loss = 0.0 # epochの損失和
print('-------------')
print('Epoch {}/{}'.format(epoch, num_epochs))
print('-------------')
print('(train)')
# データローダーからminibatchずつ取り出すループ
for imges in dataloader:
# ミニバッチがサイズが1だと、バッチノーマライゼーションでエラーになるのでさける
if imges.size()[0] == 1:
continue
# ミニバッチサイズの1もしくは0のラベル役のテンソルを作成
# 正解ラベルと偽ラベルを作成
# epochの最後のイテレーションはミニバッチの数が少なくなる
mini_batch_size = imges.size()[0]
label_real = torch.full((mini_batch_size,), 1).to(device)
label_fake = torch.full((mini_batch_size,), 0).to(device)
# GPUが使えるならGPUにデータを送る
imges = imges.to(device)
# --------------------
# 1. Discriminatorの学習
# --------------------
# 真の画像を判定
z_out_real = E(imges)
d_out_real, _ = D(imges, z_out_real)
# 偽の画像を生成して判定
input_z = torch.randn(mini_batch_size, z_dim).to(device)
fake_images = G(input_z)
d_out_fake, _ = D(fake_images, input_z)
# 誤差を計算
#d_loss_real = criterion(d_out_real.view(-1), label_real)
#d_loss_fake = criterion(d_out_fake.view(-1), label_fake)
#d_loss = d_loss_real + d_loss_fake
label_real = label_real.type_as(d_out_real.view(-1))
d_loss_real = criterion(d_out_real.view(-1), label_real)
label_fake = label_fake.type_as(d_out_fake.view(-1))
d_loss_fake = criterion(d_out_fake.view(-1), label_fake)
d_loss = d_loss_real + d_loss_fake
# バックプロパゲーション
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# --------------------
# 2. Generatorの学習
# --------------------
# 偽の画像を生成して判定
input_z = torch.randn(mini_batch_size, z_dim).to(device)
fake_images = G(input_z)
d_out_fake, _ = D(fake_images, input_z)
# 誤差を計算
g_loss = criterion(d_out_fake.view(-1), label_real)
# バックプロパゲーション
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# --------------------
# 3. Encoderの学習
# --------------------
# 真の画像のzを推定
z_out_real = E(imges)
d_out_real, _ = D(imges, z_out_real)
# 誤差を計算
e_loss = criterion(d_out_real.view(-1), label_fake)
# バックプロパゲーション
e_optimizer.zero_grad()
e_loss.backward()
e_optimizer.step()
# --------------------
# 4. 記録
# --------------------
epoch_d_loss += d_loss.item()
epoch_g_loss += g_loss.item()
epoch_e_loss += e_loss.item()
iteration += 1
# epochのphaseごとのlossと正解率
t_epoch_finish = time.time()
print('-------------')
print('epoch {} || Epoch_D_Loss:{:.4f} ||Epoch_G_Loss:{:.4f} ||Epoch_E_Loss:{:.4f}'.format(
epoch, epoch_d_loss/batch_size, epoch_g_loss/batch_size, epoch_e_loss/batch_size))
print('timer: {:.4f} sec.'.format(t_epoch_finish - t_epoch_start))
t_epoch_start = time.time()
print("総イテレーション回数:", iteration)
return G, D, E
ネットワークを初期化して、学習を実行させます。
# ネットワークの初期化
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
# conv2dとConvTranspose2dの初期化
nn.init.normal_(m.weight.data, 0.0, 0.02)
nn.init.constant_(m.bias.data, 0)
elif classname.find('BatchNorm') != -1:
# BatchNorm2dの初期化
nn.init.normal_(m.weight.data, 0.0, 0.02)
nn.init.constant_(m.bias.data, 0)
elif classname.find('Linear') != -1:
# 全結合層Linearの初期化
m.bias.data.fill_(0)
# 初期化の実施
G.apply(weights_init)
E.apply(weights_init)
D.apply(weights_init)
# 学習・検証を実行する
num_epochs = 1500
G_update, D_update, E_update = train_model(
G, D, E, dataloader=train_dataloader, num_epochs=num_epochs)
次に、テスト用のDataLoaderを作成するために、学習、検証の画像データとアノテーションデータへのファイルパスリストを作成する。テスト用の画像には、異常値検知の画像として手書き数字の 2 を加えます。つまり、テスト画像データは、手書き数字の[2, 7, 8] の画像からなります。そこから、テストのためのdatasetとdataloaderをPytorch形式で作成します。このdataloaderを使用して、テストをします。テスト用データを用いて、異常値の程度示す損失値 total lossを計算します。
def Anomaly_score(x, fake_img, z_out_real, D, Lambda=0.1):
# テスト画像xと生成画像fake_imgのピクセルレベルの差の絶対値を求めて、ミニバッチごとに和を求める
residual_loss = torch.abs(x-fake_img)
residual_loss = residual_loss.view(residual_loss.size()[0], -1)
residual_loss = torch.sum(residual_loss, dim=1)
# テスト画像xと生成画像fake_imgを識別器Dに入力し、特徴量マップを取り出す
_, x_feature = D(x, z_out_real)
_, G_feature = D(fake_img, z_out_real)
# テスト画像xと生成画像fake_imgの特徴量の差の絶対値を求めて、ミニバッチごとに和を求める
discrimination_loss = torch.abs(x_feature-G_feature)
discrimination_loss = discrimination_loss.view(
discrimination_loss.size()[0], -1)
discrimination_loss = torch.sum(discrimination_loss, dim=1)
# ミニバッチごとに2種類の損失を足し算する
loss_each = (1-Lambda)*residual_loss + Lambda*discrimination_loss
# ミニバッチ全部の損失を求める
total_loss = torch.sum(loss_each)
return total_loss, loss_each, residual_loss
# 異常検知したい画像
x = imges[0:5]
x = x.to(device)
# 教師データの画像をエンコードしてzにしてから、Gで生成
z_out_real = E_update(imges.to(device))
imges_reconstract = G_update(z_out_real)
# 損失を求める
loss, loss_each, residual_loss_each = Anomaly_score(
x, imges_reconstract, z_out_real, D_update, Lambda=0.1)
# 損失の計算。トータルの損失
loss_each = loss_each.cpu().detach().numpy()
print("total loss:", np.round(loss_each, 0))
# 画像を可視化
fig = plt.figure(figsize=(15, 6))
for i in range(0, 5):
# 上段に訓練データを
plt.subplot(2, 5, i+1)
plt.imshow(imges[i][0].cpu().detach().numpy(), 'gray')
# 下段に生成データを表示する
plt.subplot(2, 5, 5+i+1)
plt.imshow(imges_reconstract[i][0].cpu().detach().numpy(), 'gray')
以下の結果が表示されます。
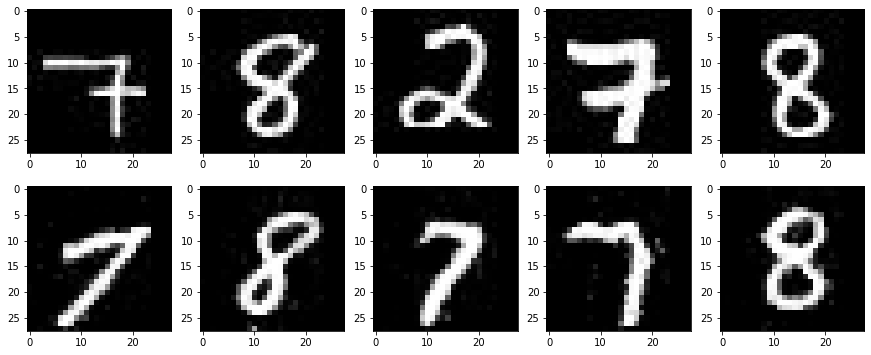
EfficientGANの構成
total loss の値を見ると、total loss: [208. 215. 256. 168. 173.]となっています。手書き数字2から生成される画像は元の画像を復元できないので、その間の損失が256となっています。それ以外の画像はほぼ復元がされていて、損失の値はそれほど小さくありませんが、215以下です。異常値を検出する閾値を230程度にすれば、手書き数字2の画像は異常として検知できます。
GANomalyをpytorch上でpython実装したコードは https://github.com/samet-akcay/ganomalyです。
git clone https://github.com/samet-akcay/ganomaly cd ganomaly pip install visdom
とパッケージをvisdomをインストールします。requirements.txtファイルをチェックして、インストールされていないモジュールだけをインストールします。これ以外の必要なモジュールは、通常、既にインストールされています。pip install -r requirements.txt とすると、古いバージョンにダウングレードされる危険があります。特に、Colabでは注意です。
MNIST及びCifar10のデータセットはすぐに使用可能な状態になっています。MNISTを用いて、異常検知を実験してみましょう。学習のためのコマンドは以下のような様式です。
python train.py \
--dataset mnist \
--niter \
--abnormal_class <0,1,2,3,4,5,6,7,8,9> \
--display # optional if you want to visualize
検出する異常値を 9 とします。以下のコマンドを入力します。
!python train.py --dataset mnist --isize 32 --nc 1 --niter 15 --abnormal_class 9
10分程度で結果が出ます。
================ Training Loss (Thu Apr 15 08:50:08 2021) ================ Avg Run Time (ms/batch): 7.403 roc: 0.562 max roc: 0.562 Avg Run Time (ms/batch): 7.784 roc: 0.529 max roc: 0.562 Avg Run Time (ms/batch): 7.768 roc: 0.555 max roc: 0.562 Avg Run Time (ms/batch): 8.046 roc: 0.569 max roc: 0.569 Avg Run Time (ms/batch): 7.054 roc: 0.604 max roc: 0.604 Avg Run Time (ms/batch): 7.039 roc: 0.565 max roc: 0.604 Avg Run Time (ms/batch): 7.881 roc: 0.587 max roc: 0.604 Avg Run Time (ms/batch): 7.512 roc: 0.624 max roc: 0.624 Avg Run Time (ms/batch): 7.975 roc: 0.619 max roc: 0.624 Avg Run Time (ms/batch): 7.513 roc: 0.563 max roc: 0.624 Avg Run Time (ms/batch): 7.363 roc: 0.594 max roc: 0.624 Avg Run Time (ms/batch): 7.217 roc: 0.573 max roc: 0.624 Avg Run Time (ms/batch): 6.508 roc: 0.561 max roc: 0.624 Avg Run Time (ms/batch): 7.004 roc: 0.517 max roc: 0.624 Avg Run Time (ms/batch): 8.101 roc: 0.579 max roc: 0.624
平均ROC値が0.579、最大ROCは0.624です。異常検知の精度は優れているとは言えないかもしれません。ちなみに、異常値を数字 0 に指定して、上記のコマンドを実行すると、平均的ROCは0.73、最大ROCは0.88となります。手書き数字9は異常値として判定し難いが、0は異常値としては判定しやすいと言うことになります。
Cifar10を用いて、異常検知を実験してみましょう。異常検知の画像を'dog'に分類される画像とします。このケースでは、以下のようなコマンドを入力します。
!python train.py --dataset cifar10 --isize 32 --niter 15 --abnormal_class 'dog'
10分程度で結果が出ます。平均ROC値が0.70程度、最大ROC値は0.72です。
================ Training Loss (Thu Apr 15 06:29:19 2021) ================ Avg Run Time (ms/batch): 10.657 roc: 0.637 max roc: 0.637 Avg Run Time (ms/batch): 10.588 roc: 0.685 max roc: 0.685 Avg Run Time (ms/batch): 10.915 roc: 0.677 max roc: 0.685 Avg Run Time (ms/batch): 10.415 roc: 0.693 max roc: 0.693 Avg Run Time (ms/batch): 11.267 roc: 0.653 max roc: 0.693 Avg Run Time (ms/batch): 11.097 roc: 0.725 max roc: 0.725 Avg Run Time (ms/batch): 10.202 roc: 0.690 max roc: 0.725 Avg Run Time (ms/batch): 10.981 roc: 0.681 max roc: 0.725 Avg Run Time (ms/batch): 11.562 roc: 0.560 max roc: 0.725 Avg Run Time (ms/batch): 9.686 roc: 0.692 max roc: 0.725 Avg Run Time (ms/batch): 10.923 roc: 0.711 max roc: 0.725 Avg Run Time (ms/batch): 9.951 roc: 0.641 max roc: 0.725 Avg Run Time (ms/batch): 11.124 roc: 0.638 max roc: 0.725 Avg Run Time (ms/batch): 11.013 roc: 0.669 max roc: 0.725 Avg Run Time (ms/batch): 10.746 roc: 0.701 max roc: 0.725
ROC(receiver operating characteristic)曲線とは、 the false positive rate (FPR)の値に対するthe true positive rate (TPR)値をプロットしたものです。当然、横軸と縦軸の範囲は[0,1]です。FPRとは異常の出来事を「異常である」と判定した比率、TPRは異常でない正常の出来事を「正常」と判定した比率のことです。45度線よりも左上に位置するROC曲線ほど優れた予測をすることになります。つまり、ROC曲線の形状が座標[0,1]に最も接近した曲線ほど、予測が優れているということになります。この尺度を採用した時、GANomalyモデルは優れているかどうか判定するとどうなるでしょうか。ROC曲線を描いていないので、なんとも言えません。ただ、過学習が起きているので、このことに注意が必要です。
また、ROC曲線の下側の面積の大きさをAUC(Area under the ROC Curve)と言います。最も優れた推測システムのAUC値は1.0です。
MVTec データを用いたanomaly detection |
MVtec データを使用してanomaly detectionを行うアルゴリズムは数種類のモデルが提案されています。代表的なモデルのPython実装は以下の通りです。
Semi-supervised Anomaly Detection and Segmentation in images based on Deep Learning
Sub-Image Anomaly Detection with Deep Pyramid Correspondences
Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection
この中から、最初に、semi-supervised CAEを利用したアルゴリズム「Semi-supervised Anomaly Detection and Segmentation in images based on Deep Learning」を取り上げます。
すでに触れたように、CAEはEncoderとDecoderを畳み込み(Convolution)によって構築します。畳み込みの利用を明示的にせずにそのままAutoEncoderとして呼ばれることもあります。CAEによって正常な画像学習を行うことで、Encoderには「正常画像がどのようなものか」に関する特徴量の抽出が期待できます。こうして学習したCAEは、正常画像を入力とした時は適切に画像の再構成を行えます。対して異常画像を入力とした場合には、異常箇所に関してはうまく再構成できないと予測するため、再構成誤差に基づいた異常検知が可能になります。また、再構成誤差はピクセルごとに計算されるため、画像のどこが異常なのかを見た目で確認しやすいというメリットもあります。
今までは、MNISTやCifar10のような画像サイズが小さいデータセットを用いてきました。現実の製造現場などで直面する画像はもっと大きいサイズでないと、異常か否かを判定することは困難です。最近、現実的な異常検知に使用できるデータセットが提供されています。MVTecデータセットと呼ばれるものです。
このMVTecデータセットは、2019年6月に公開されたばかりのデータセットで、15カテゴリーから工業製品や農作物、各種類ごとの欠陥、画像内のさまざまな配置、さらに欠陥領域のセグメンテーションデータもアノテーションに含まれていて、素晴らしいデータセットです。URLは https://www.mvtec.com/company/research/datasets/mvtec-ad/です。15種類のクラス名は
['bottle', 'cable', 'capsule', 'carpet', 'grid','hazelnut', 'leather',
'metal_nut', 'pill', 'screw','tile', 'toothbrush', 'transistor', 'wood', 'zipper']
です。各クラスごとにダウンロードできます。各クラスのサイズは300~500MB前後ですが、データセット全体のサイズは約5GBです。
ちなみに、hazelnutのテスト用画像は

hazelnut/test/crackの画像
です。この画像はcracked(割れ目のある)hazelnutの異常です。詳しい説明は、このPDFを参照ください。
ここで、MVTecADデータセットに対してCAEを用いた異常検知のTensorFlow実装を取り上げます。”semi-supervised Anomaly Detection and Segmentation in images based on Deep Learning”と名付けられたモデルです。
ここで提案された方法は、再構成された画像と入力画像の間の閾値処理された(ピクセル単位の)違いを使用して、異常を特定します。 閾値は、最初に異常のないトレーニング画像のサブセット、つまり検証画像を使用して決定され、次に異常のないテスト画像と異常なテスト画像の両方のサブセットを使用して(面積と閾値の)最適なペアが決定されます。これが"semi supervised"と言う意味です。pythonプログラムは、3種類のスクリプト、training, finetuning および testing を順次実行することから構成されます。
このパッケージは、Convolutional Auto-Encoder (CAE)を用いた5つのモデル、mvtecCAE 、 baselineCAE 、inceptionCAE 、resnetCAE 、skipCAE が用意されています。必要な主要モジュールは tensorflow 2、ktrain 、scikit-image 、scikit-learn などです。これらのモジュールがインストールされていることを確認したら、パッケージをインストールします。
git clone https://github.com/AdneneBoumessouer/MVTec-Anomaly-Detection cd MVTec-Anomaly-Detection mkdir data
作成したディレクトリ data の下に、MVTecデータセットを保存します。'hazelnut'が保存されているとします。以下のようなディレクトリ構成になっています。
├── data │ ├──mvtec <- folder containing all mvtec classes. │ ├──hazelnut <- subfolder of a class (contains additional subfolders /train and /test). │ ├── ... ├── autoencoder <- directory containing modules for training: autoencoder class and methods as well as custom losses and metrics. ├── processing <- directory containing modules for preprocessing images and before training and processing images after training. ├── results <- directory containing finetuning and test results. ├── readme.md <- readme file. ├── requirements.txt <- requirement text file containing used libraries. ├── saved_models <- directory containing saved models, training history, loss and learning plots and inspection images. ├── train.py <- training script to train the auto-encoder. ├── finetune.py <- approximates a good value for minimum area and threshold for classification. └── test.py <- test script to classify images of the test set using finetuned parameters.
正常な画像のみを用いて、CAEモデルを訓練します。
python train.py -d data/mvtec/hazelnut -a mvtecCAE -b 8 -l ssim -c grayscale
ここで、オプションは以下の通りです。
-d , --input-dir directory containing training images
-a , --architecture architecture of the model to use for training: 'mvtecCAE', 'baselineCAE', 'inceptionCAE' or 'resnetCAE'
-b , --batch batch size to use for training
-l , --loss loss function to use for training: 'mssim', 'ssim' or 'l2'
-c , --color color mode for preprocessing images before training: 'rgb' or 'grayscale'
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 256, 256, 1)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 128, 128, 32) 544 _________________________________________________________________ conv2d_1 (Conv2D) (None, 64, 64, 32) 16416 _________________________________________________________________ conv2d_2 (Conv2D) (None, 32, 32, 32) 16416 _________________________________________________________________ conv2d_3 (Conv2D) (None, 32, 32, 32) 9248 _________________________________________________________________ conv2d_4 (Conv2D) (None, 16, 16, 64) 32832 _________________________________________________________________ conv2d_5 (Conv2D) (None, 16, 16, 64) 36928 _________________________________________________________________ conv2d_6 (Conv2D) (None, 8, 8, 128) 131200 _________________________________________________________________ conv2d_7 (Conv2D) (None, 8, 8, 64) 73792 _________________________________________________________________ conv2d_8 (Conv2D) (None, 8, 8, 32) 18464 _________________________________________________________________ conv2d_9 (Conv2D) (None, 8, 8, 1) 2049 _________________________________________________________________ conv2d_10 (Conv2D) (None, 8, 8, 32) 320 _________________________________________________________________ conv2d_11 (Conv2D) (None, 8, 8, 64) 18496 _________________________________________________________________ up_sampling2d (UpSampling2D) (None, 16, 16, 64) 0 _________________________________________________________________ conv2d_12 (Conv2D) (None, 8, 8, 128) 131200 _________________________________________________________________ up_sampling2d_1 (UpSampling2 (None, 16, 16, 128) 0 _________________________________________________________________ conv2d_13 (Conv2D) (None, 16, 16, 64) 73792 _________________________________________________________________ up_sampling2d_2 (UpSampling2 (None, 32, 32, 64) 0 _________________________________________________________________ conv2d_14 (Conv2D) (None, 16, 16, 64) 65600 _________________________________________________________________ up_sampling2d_3 (UpSampling2 (None, 32, 32, 64) 0 _________________________________________________________________ conv2d_15 (Conv2D) (None, 32, 32, 32) 18464 _________________________________________________________________ up_sampling2d_4 (UpSampling2 (None, 64, 64, 32) 0 _________________________________________________________________ conv2d_16 (Conv2D) (None, 32, 32, 32) 16416 _________________________________________________________________ up_sampling2d_5 (UpSampling2 (None, 128, 128, 32) 0 _________________________________________________________________ conv2d_17 (Conv2D) (None, 64, 64, 32) 16416 _________________________________________________________________ up_sampling2d_6 (UpSampling2 (None, 128, 128, 32) 0 _________________________________________________________________ conv2d_18 (Conv2D) (None, 128, 128, 32) 65568 _________________________________________________________________ up_sampling2d_7 (UpSampling2 (None, 256, 256, 32) 0 _________________________________________________________________ conv2d_19 (Conv2D) (None, 256, 256, 1) 2049 ================================================================= Total params: 746,210 Trainable params: 746,210 Non-trainable params: 0 _________________________________________________________________ Found 352 images belonging to 1 classes. Found 39 images belonging to 1 classes. INFO:autoencoder.autoencoder:initiating learning rate finder to determine best learning rate. simulating training for different learning rates... this may take a few moments... 中略 44/44 [==============================] - 21s 470ms/step - loss: 0.2352 - ssim: 0.7648 - val_loss: 0.1631 - val_ssim: 0.8342 Epoch 33/1024 44/44 [==============================] - 21s 471ms/step - loss: 0.2349 - ssim: 0.7651 - val_loss: 0.1631 - val_ssim: 0.8370 Epoch 34/1024 44/44 [==============================] - 21s 467ms/step - loss: 0.2343 - ssim: 0.7657 - val_loss: 0.1640 - val_ssim: 0.8357 Epoch 35/1024 44/44 [==============================] - 21s 465ms/step - loss: 0.2342 - ssim: 0.7658 - val_loss: 0.1639 - val_ssim: 0.8349 Epoch 36/1024 44/44 [==============================] - 21s 468ms/step - loss: 0.2332 - ssim: 0.7668 - val_loss: 0.1633 - val_ssim: 0.8372 Epoch 37/1024 44/44 [==============================] - 21s 468ms/step - loss: 0.2335 - ssim: 0.7665 - val_loss: 0.1641 - val_ssim: 0.8377 Epoch 00037: Reducing Max LR on Plateau: new max lr will be 0.00016756477998569608 (if not early_stopping). Restoring model weights from the end of the best epoch. Epoch 00037: early stopping Weights from best epoch have been loaded into model.INFO:autoencoder.autoencoder:loss_plot.png successfully saved. INFO:autoencoder.autoencoder:lr_schedule_plot.png successfully saved. INFO:autoencoder.autoencoder:training history has been successfully saved as csv file. INFO:autoencoder.autoencoder:training files have been successfully saved at: /content/drive/My Drive/Anomaly_detection/MVTec-Anomaly-Detection/saved_models/data/mvtec_anomaly_detection/hazelnut/mvtecCAE/ssim/10-04-2021_22-48-37 INFO:__main__:done.
early stoppingが働いて終了しました。結果は、
saved_models/data/mvtec_anomaly_detection/hazelnut/mvtecCAE/ssim/10-04-2021_22-48-37
に保存されました。
次に、finetune.pyスクリプトを実行します。このスクリプトは、訓練用の正常な画像の部分集合とテスト用に用意された異常な画像と正常な画像の部分集合を使って、最小異常領域と閾値のペアを推計します。これらのパラメータは分類とセグメンテーションに適用されます。先程の結果を用いて、
python finetune.py -p saved_models/data/mvtec_anomaly_detection/hazelnut/mvtecCAE/ssim/10-04-2021_22-48-37/mvtecCAE_b8_e24.hdf5 -m ssim -t float64
と打ちます。フォルダー(ssim/10-04-2021_22-48-37)の中を覗かないと重みの名称 mvtecCAE_b8_e24.hdf5 がわからないので、確認してから明記します。ここで、引数は
-p , --path path to saved model
-m , --method method for generating resmaps: 'ssim' or 'l2'
-t , --dtype datatype for processing resmaps: 'float64' or 'uint8'
以下のような結果が表示されます。
中略
Found 39 images belonging to 1 classes.
2021-04-10 23:15:34.969153: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
2021-04-10 23:15:34.969589: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 2199995000 Hz
2021-04-10 23:15:35.163814: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-04-10 23:15:37.049325: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-04-10 23:15:37.514183: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
Found 110 images belonging to 5 classes.
step 1/2: computing largest anomaly areas for increasing thresholds...
Progress: |████████████████████████████████████████████████████████████████████████████████| 100.0% Complete
step 2/2: selecting best minimum area and threshold pair for testing...
Progress: |████████████████████████████████████████████████████████████████████████████████| 100.0% Complete
finetuning results: {'best_min_area': 135, 'best_threshold': 0.7820000000000006, 'best_score': 0.7857142857142857, 'method': 'ssim', 'dtype': 'float64', 'split': 0.1}
INFO:__main__:finetuning results saved at /content/drive/My Drive/Anomaly_detection/MVTec-Anomaly-Detection/results/data/mvtec_anomaly_detection/hazelnut/mvtecCAE/ssim/10-04-2021_22-48-37/finetuning/ssim_float64
min_area threshold plot successfully saved at:
/content/drive/My Drive/Anomaly_detection/MVTec-Anomaly-Detection/results/data/mvtec_anomaly_detection/hazelnut/mvtecCAE/ssim/10-04-2021_22-48-37/finetuning/ssim_float64
scores plot successfully saved at:
/content/drive/My Drive/Anomaly_detection/MVTec-Anomaly-Detection/results/data/mvtec_anomaly_detection/hazelnut/mvtecCAE/ssim/10-04-2021_22-48-37/finetuning/ssim_float64
最後に、異常検知を実行します。
python3 test.py -p saved_models/mvtec/hazelnut/mvtecCAE/ssim/10-04-2021_22-48-37/mvtecCAE_b8_e24.hdf5
以下が結果です。
結果をどのように解釈しますか。異常なしの画像は good、異常のあるhazelnutの画像は、傷の種類に対応させて、crack, cut, hole, print とに分類されています。TPR(True Positive Rate)=0.78、TNR(True Negative Rate)=1、score=0.82857 は結構良い精度です。異常のある画像のうち、そのうちの78%に対して異常を検出しています。TNR=1なので、異常なしの画像はすべて異常なしと判定されています。
なお、引数で登場した ssim について説明します。SSIMとは、structural similarity index measure のことで、ふたつの画像の類似度を測定する尺度です。この計算式の説明は省略します。
次に、Sub-Image Anomaly Detection with Deep Pyramid Correspondences (SPADE) in PyTorchを紹介します。このアルゴリズムと上記のアルゴリズムとの最大の相違点は、画像分類のpretrained modelを利用するので、モデルの学習が必要ないことです。原論文はこのarXiv.orgにあります。
この論文で提案されたアルゴリズムをPytorchで実装したパッケージをgit clone します。
git clone https://github.com/byungjae89/SPADE-pytorch cd SPADE-pytorch/src
ディレクトリsrcの中に、スクリプト main.py があるので、これを実行します。
python main.py
以下のように、最初に、pretrained modelの重みwide_resnet50_2-95faca4d.pthがダウンロードされます。その後、datasets/mvtec.pyが呼び出されて、MVTecのデータセットがダウンロードされ、data/mvtec_anomaly_detection/の下に保存されます。画像セットのクラス名は以下の通りです。
CLASS_NAMES = ['bottle', 'cable', 'capsule', 'carpet', 'grid','hazelnut', 'leather', 'metal_nut', 'pill', 'screw','tile', 'toothbrush', 'transistor', 'wood', 'zipper']そして、このデータを用いた異常検知が実行されます。MVTec AD データセットのサイズは約5ギガあります。MVTec のダウンロードもあるので、Colabで1時間以上かかります。
/content/drive/My Drive/Anomaly_detection/SPADE-pytorch/src Downloading: "https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth" to /root/.cache/torch/hub/checkpoints/wide_resnet50_2-95faca4d.pth 100% 132M/132M [00:01<00:00, 69.8MB/s] mvtec_anomaly_detection.tar.xz: 5.26GB [13:24, 6.54MB/s] unzip downloaded dataset: ../data/mvtec_anomaly_detection.tar.xz /usr/local/lib/python3.7/dist-packages/torchvision/transforms/transforms.py:258: UserWarning: Argument interpolation should be of type InterpolationMode instead of int. Please, use InterpolationMode enum. "Argument interpolation should be of type InterpolationMode instead of int. " load train set feature from: ./result/temp/train_bottle.pkl | feature extraction | test | bottle |: 100% 3/3 [00:37<00:00, 12.38s/it] bottle ROCAUC: 0.972 | localization | test | bottle |: 100% 83/83 [01:35<00:00, 1.15s/it] bottle pixel ROCAUC: 0.970 /usr/local/lib/python3.7/dist-packages/torchvision/transforms/transforms.py:258: UserWarning: Argument interpolation should be of type InterpolationMode instead of int. Please, use InterpolationMode enum. "Argument interpolation should be of type InterpolationMode instead of int. " load train set feature from: ./result/temp/train_cable.pkl | feature extraction | test | cable |: 100% 5/5 [01:06<00:00, 13.25s/it] cable ROCAUC: 0.848 中略 | feature extraction | test | wood |: 100% 3/3 [00:40<00:00, 13.41s/it] wood ROCAUC: 0.958 | localization | test | wood |: 100% 79/79 [01:31<00:00, 1.16s/it] wood pixel ROCAUC: 0.953 /usr/local/lib/python3.7/dist-packages/torchvision/transforms/transforms.py:258: UserWarning: Argument interpolation should be of type InterpolationMode instead of int. Please, use InterpolationMode enum. "Argument interpolation should be of type InterpolationMode instead of int. " load train set feature from: ./result/temp/train_zipper.pkl | feature extraction | test | zipper |: 100% 5/5 [00:56<00:00, 11.35s/it] zipper ROCAUC: 0.966 | localization | test | zipper |: 100% 151/151 [02:54<00:00, 1.15s/it] zipper pixel ROCAUC: 0.986 Average ROCAUC: 0.854 Average pixel ROCUAC: 0.964
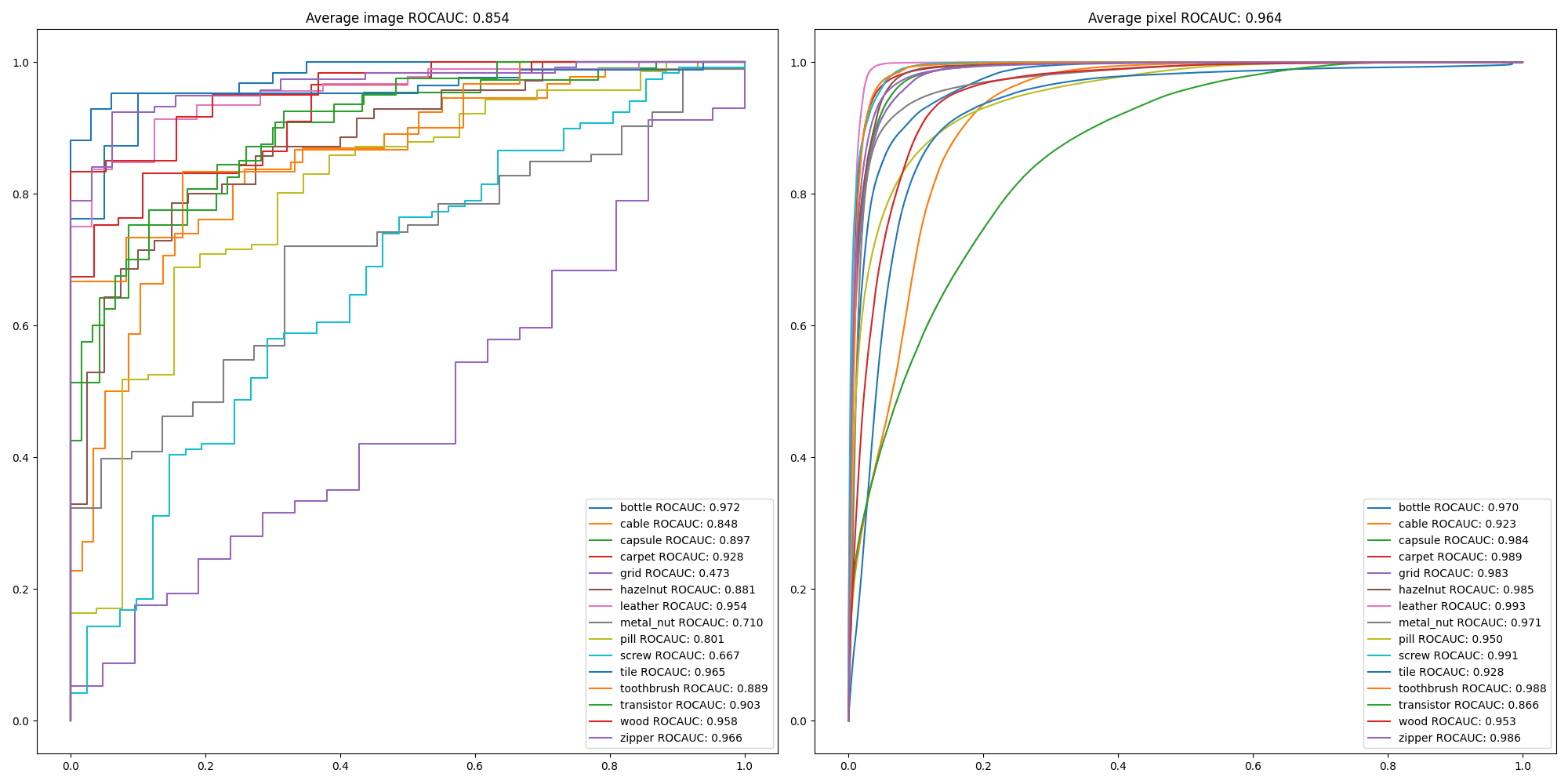
ROC曲線
grid, metal_nutとscrewを除けば、異常検知の精度は90%を超えて、かなり良いです。
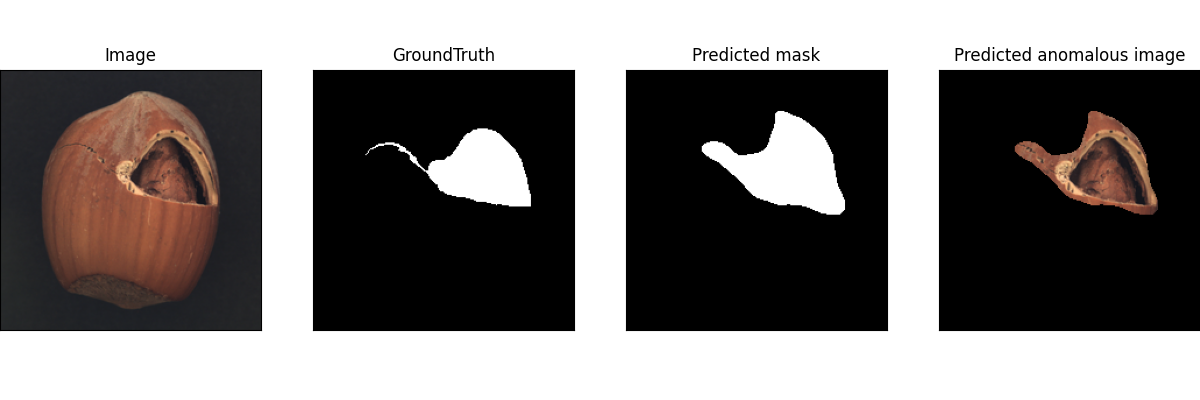
hazelnut/test/crackの異常検知画像
image及びGroundTruthの画像はダウンロードしたMVTecデータに含まれています。右側のPredicted maskとPredicted mask imageは推測された画像です。
最後に、論文「Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection」で提案されたモデルを取り上げます。
このモデルの特徴の解説はqiitaに掲載の@sUeharaE4及びshinmura0が参考になります。なので、ここではコードの説明を省略します。
実装コードは以下のGithub Repoにあります。MahalanobisAD-pytorch及び EfficientNet_AD_Segmentationです。コードをgit clone して実行できます。ただ、論文の公式コードも公開されていますが、Colabで実行すると、pytorch_lightningモジュールを使用している関係でエラーが出ます。
以下に上記コードMahalanobisAD-pytorchを実行したときの結果を表示します。
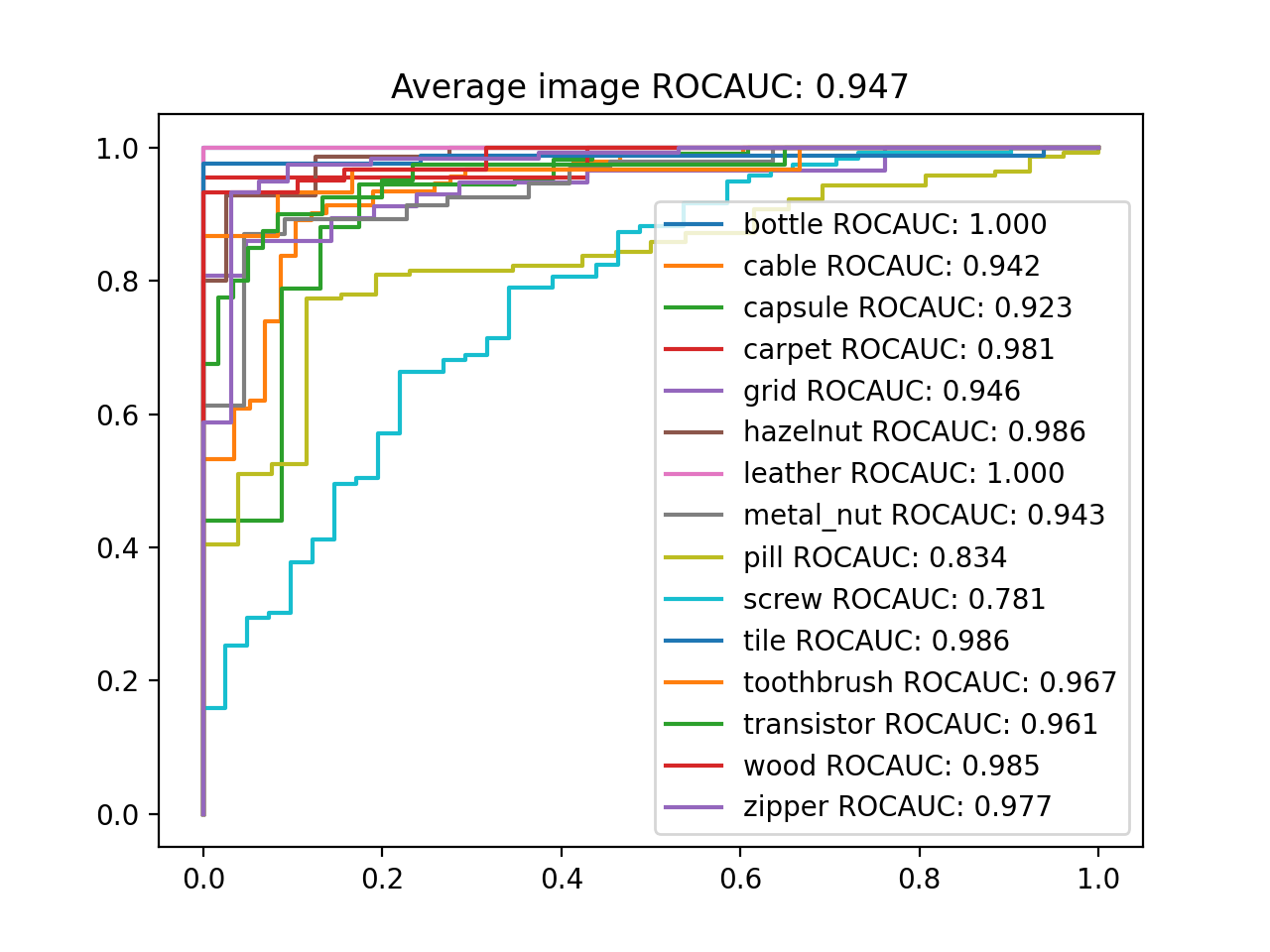
MahalanobisAD-pytorchの実行結果
なお、Anomaly Detection on MVTec ADの最近の進捗状況はこのサイトが参考になります。現時点(2021年4月)で、18種類のモデルが紹介されて、各モデルの検出精度のランキングがついています。ランキング1位は PaDiM、第2位はSTPM、第3位はSPADEです。
PaDiM のコードの Github は https://github.com/xiahaifeng1995/PaDiM-Anomaly-Detection-Localization-master です。
STPM の Github は https://github.com/hcw-00/STPM_anomaly_detection です。
SPADEのコードはここで取り上げました。PaDiMモデルは、論文「Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection」の拡張版で、SPADEと同じく、画像分類のpretrained model(efficientNet, ResNetなど)を利用しているという枠組みでは同種のモデルと言えます。