GANs モデルの基本形
|
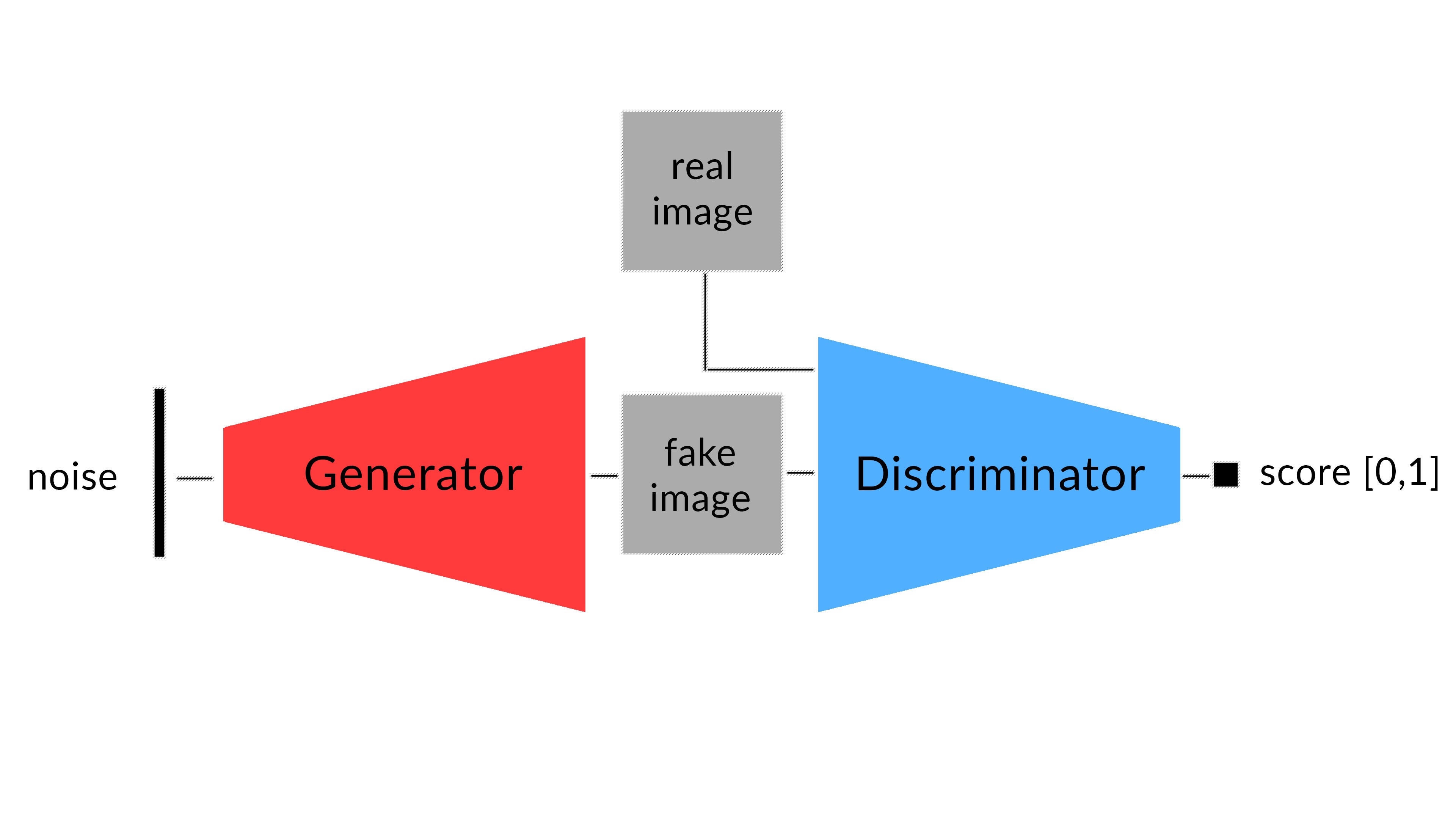
敵対的生成ネットワーク (GAN, Generative Adversarial Networks) は、機械学習(ディープラーニング)の分野で最も興味深いアルゴリズムの一つです。このネットワーク・モデルには、Generator と Discriminator という2 つのネットワークが組み込まれています。この2種類のネットワークが敵対するような関係になることからこの名称で呼ばれます。generator (「芸術家」the artist) がリアルに見える画像(フェイク画像)を作成することを学習し、その一方で、 discriminator (「芸術評論家」 the art critic」) がフェイク画像からリアル画像を識別することを学習します。
学習する間、generator はリアルに見える画像を作成することに次第に上達し、その一方で、 discriminator はフェイクとリアルを識別することに上達します。discriminator がもはやフェイクからリアル画像を識別できないとき、学習プロセスは終了します。
Generative Adversarial Networks (GANs) の論文は こちらに掲載されています。このGANsモデルを色々と拡張したアルゴリズムに、DCGAN,LSGAN, ConditionalGAN, CycleGAN などいくつかの発展系GANモデルがあります。
GAN はシンプルなニューラルネットワークによる生成モデルであり、不安定性の問題を改善するために、generator に CNN を採用したモデルが DCGAN と呼ばれています。DCGAN の論文は、Deep Convolutional Generative Adversarial Network (DCGAN)です。LSGAN(Least Square GAN)のネットワーク構造は DCGAN と同じですが、LSGANは正解ラベルに対する二乗誤差を用いるところが異なります。現論文はこちらです。また、DCGAN では、生成するフェイク画像のクラスを指定できない欠点を改善して、画像のクラスを指定できるようにしたモデルが ConditionalGAN と呼ばれるものです。pix2pix はこの CoditionalGAN に属します。
このページでは、DCGAN およびCycleGANモデルの Python 実装について説明します。使用する Python API は Pytorch と TensorFlow です。これらのコードを実行するには、GPU を使用できないノートPCでは時間がかかり過ぎるので、Google Colab などの無料GPU サービスを利用する方が便利です。
私のGithub Repoの DCGAN_examplesおよび CycleGAN をご利用ください。この GitHub Repo を git clone して利用して下さい。Google Colab の直下 /content/ に git Clone する方法と、/My Drive/ に mount して git clone する方法があります。後者のケースでは、修正したファイルなどが Colab drive に保存されますが、前者のケースではそれはできません。
Google Colab の /My Drive/ に GitHub Repo を git clone するための手順を説明します。Google Colab に行って、以下のセルだけのノートブックを作成します。
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/My Drive/
! git clone https://github.com/mashyko/pytorch-CycleGAN-and-pix2pix # GitHub Repo に応じて修正
これを実行すると、/My Drive/ の下に Github の pytorch-CycleGAN-and-pix2pix のフォルダーが作成されます。このノートブックは閉じて、削除してもかまいませんが、名前を付けて保存した方が便利かもしれません。作成されたフォルダーに CycleGAN.ipynb があります。このノートブックを開きます。最初に、先頭に、空のセルを作成して
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/My Drive/pytorch-CycleGAN-and-pix2pix
をその中にコピペして下さい。これで、/My Drive/pytorch-CycleGAN-and-pix2pix/ にあるファイルの読み込みが可能になります。
なお、このページでは PyTorch を Python API として採用することにします。Tensorflow を用いた python 実装については説明しませんので、Tensorflow を用いたときの実装例への簡単な説明を付記します。
MNISTデータセットを用いてDCGANsネットワークをKeras + Tensorflow で実装した例は、Tensorflow の公式ページに掲載されています。英語が理解できる方は、このMITのディープラーニング入門のビデオを見るといいと思います。CMが頻繁に表示されるのが難点ですが、Tensorflow を使った、シンプルで、分かりやすい内容となっています。
また、Tensorflowを用いた CycleGAN 実装例は Tensorflow のTutorialsにあります。そちらを参考にして下さい。
Last updated: 2020.3.29 (first uploaded 2020.3.8)
GANs モデルの基本形
DCGAN の構造とPyTorch による実装の簡単な説明 |
この節では、DCGAN の構造を簡単に説明して、主として PyTorch を用いた実装コードを取り上げます。PyTorch のコードを用いたdcgan のPython 実装の例を説明します。この節でのコードの説明をスキップしても、Google Colab での実装コードは実行できます。
PyTorch での Generator と Discriminator のネットワーク構成の主要部分を説明します。Pytorch のTutorials の例 に沿って説明します。
Pytorch モジュールの import の部分は省略します。実際のコードは上記の Tutorial をみて下さい。Generator およびDiscriminator を定義するに当たり、幾つかのパラメータに数値を指定する必要があります。登場するパラメータは以下のとおりです。
dataroot = "data/celeba" # Root directory for dataset workers = 2 # Number of workers for dataloader batch_size = 128 # Batch size during training image_size = 64 # Spatial size of training images. All images will be resized to this size using a transformer. nc = 3 # Number of channels in the training images. For color images this is 3 nz = 100 # Size of z latent vector (i.e. size of generator input) ngf = 64 # Size of feature maps in generator ndf = 64 # Size of feature maps in discriminator num_epochs = 5 # Number of training epochs lr = 0.0002 # Learning rate for optimizers beta1 = 0.5 # Beta1 hyperparam for Adam optimizers ngpu = 1 # Number of GPUs available. Use 0 for CPU mode.
すべてのモデルの重みは正規分布[0, 0.2]からランダムに初期化します。weights_init 関数はランダムなデータを入力として受け取って、すべてのconvolutional, convolutional-transpose, batch normalization layersを再初期化する時に使用されます。
# custom weights initialization called on netG and netD
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
Generator 𝐺 は latent space vector (𝑧) を画像空間に射影します。つまり、Generator は、以下に説明する fixed_noise から、データのイメージ画像と同一のサイズ、例えば、3x64x64、のRGB 画像(フェイク)を作成します。この過程は、以下の図で示されたようなネットワークから構成されます。generator からの出力は、数値を[-1, 1]に規格化するためにtanh 関数に送られます。convolutional transpose layers の説明については、原論文を参照ください。
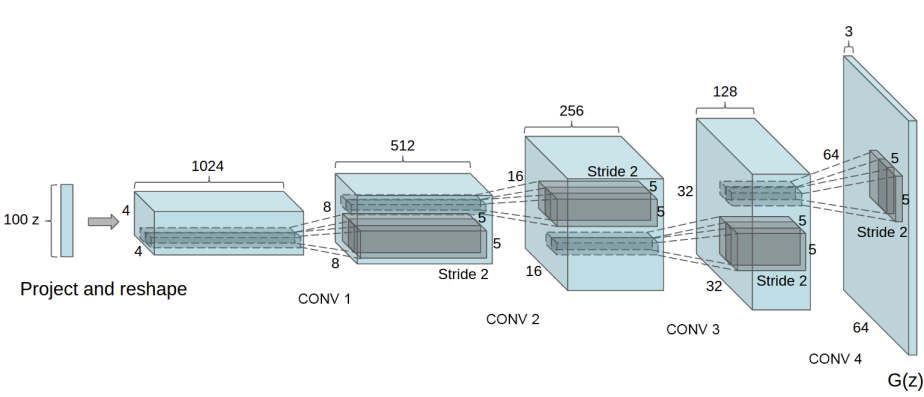
Pytorch でコード化された Generator のネットワーク構成は以下のとおりです。
class Generator(nn.Module): def __init__(self, ngpu): super(Generator, self).__init__() self.ngpu = ngpu self.main = nn.Sequential( # input is Z, going into a convolution nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False), nn.BatchNorm2d(ngf * 8), nn.ReLU(True), # state size. (ngf*8) x 4 x 4 nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf * 4), nn.ReLU(True), # state size. (ngf*4) x 8 x 8 nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf * 2), nn.ReLU(True), # state size. (ngf*2) x 16 x 16 nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf), nn.ReLU(True), # state size. (ngf) x 32 x 32 nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False), nn.Tanh() # state size. (nc) x 64 x 64 ) def forward(self, input): return self.main(input)
実際に生成器Gのインスタンスを作成するためには、以下にようにします。
# Create the generator netG = Generator(ngpu).to(device) # Handle multi-gpu if desired if (device.type == 'cuda') and (ngpu > 1): netG = nn.DataParallel(netG, list(range(ngpu))) # Apply the weights_init function to randomly initialize all weights # to mean=0, stdev=0.2. netG.apply(weights_init) # Print the model print(netG)
Discriminator は、フェイク画像を入力として、入力画像がリアルであるとする確率を出力します。サイズ3x64x64の入力画像をConv2d, BatchNorm2d, and LeakyReLU layersからなるネットワークに送ります。最後に、Sigmoid 関数を通してactivation します。Discriminator のコード構成はこうなっています。
class Discriminator(nn.Module): def __init__(self, ngpu): super(Discriminator, self).__init__() self.ngpu = ngpu self.main = nn.Sequential( # input is (nc) x 64 x 64 nn.Conv2d(nc, ndf, 4, 2, 1, bias=False), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf) x 32 x 32 nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 2), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf*2) x 16 x 16 nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 4), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf*4) x 8 x 8 nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 8), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf*8) x 4 x 4 nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False), nn.Sigmoid() ) def forward(self, input): return self.main(input)
実際に識別器Dのインスタンスを作成するためには、以下にようにします。
netD = Discriminator(ngpu).to(device) # Handle multi-gpu if desired if (device.type == 'cuda') and (ngpu > 1): netD = nn.DataParallel(netD, list(range(ngpu))) # Apply the weights_init function to randomly initialize all weights # to mean=0, stdev=0.2. netD.apply(weights_init) # Print the model print(netD)
フェイク画像とリアル画像を識別するために、リアル画像のラベルを1、フェイク画像のラベルを0 とします。最適化関数として Adam optimizers を採用します。正規分布からランダムに取り出したノイズ(fixed_noise)を a fixed batch of latent vectors の値として入力します。
# Initialize BCELoss function criterion = nn.BCELoss() # Create batch of latent vectors that we will use to visualize # the progression of the generator fixed_noise = torch.randn(64, nz, 1, 1, device=device) # Establish convention for real and fake labels during training real_label = 1 fake_label = 0 # Setup Adam optimizers for both G and D optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999)) optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
後は、学習のためのループをコード化すれば終了です。学習ループの実装については、Tutorials を参照ください。
DCGAN の Python 実装 |
MNIST データセットを用いた DCGANs ネットワークを PyTorch API で実装します。Pytorch の公式Tutorials で説明されているコードを修正して使用します。前節で取り上げた Generator と Discrinimator の構成は同一です。ただし、手書き数字の画像サイズは28x28なので、image_size=28 、白黒なので、nc=1 と設定し直します。
import のセルは以下の通りです。
from __future__ import print_function #%matplotlib inline import argparse import os import random import torch import torchvision import torch.nn as nn import torch.nn.parallel import torch.backends.cudnn as cudnn import torch.optim as optim import torch.utils.data import torchvision.datasets as dset import torchvision.transforms as transforms import torchvision.utils as vutils import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML
MNIST データセットのダウンロードは以下のように行います。このコードはこの Google Colab にアップロードしていますので、Colab で実行できます。
# データセットの設定
dataset = dset.MNIST(root='./data', download=True,
transform=transforms.Compose([
transforms.Resize(64),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),]))
# 入力画像のチャネル数
nc=1
# バッチサイズ
batchsize = 64
# Dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batchsize, shuffle=True, num_workers=2)
このコードで MNIST のデータセットがダウンロードされて、ディレクトリ ./data/ に保存されます。
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# Plot some training images
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))
このセルを実行すると、データセットの一部(64枚の画像)が表示されます。

num_epochs = 5 と設定して、学習ループのセルを実行します。数分後に結果が出ます。
#%%capture
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())
このセルを実行すると、生成されたフェイク画像が以下のように表示されます。

公式 Tutorials 以外の PyTorch を用いた DCGAN の実装例を2種類紹介します。一つ目は、公式Tutorials と同じCNNを用いたPytorch のコードがあります。このコードでは、以下が Generator と Discriminator のネットワーク構成になっています。
Generator( (main): Sequential( (0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU() (3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU() (6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (8): ReLU() (9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (11): ReLU() (12): ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (13): Tanh() ) ) Discriminator( (main): Sequential( (0): Conv2d(1, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (1): LeakyReLU(negative_slope=0.2, inplace=True) (2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (4): LeakyReLU(negative_slope=0.2, inplace=True) (5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (7): LeakyReLU(negative_slope=0.2, inplace=True) (8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) (9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (10): LeakyReLU(negative_slope=0.2, inplace=True) (11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False) (12): Sigmoid() ) )
ここで、nz=100、 nch=1、 nch_g=64、 nch_d=64 となっています。このネットワークを用いたコードは この Google Colab にあります。
もう少し簡単なCNNを使用した PyTorch のコードは、このGoogle Colabにあります。実行を試みて、手書き数字のフェイク画像をお楽しみください。
次に、CIFAR10 のデータセットを利用して、フェイク画像を生成する例を取り上げます。Pytorch の公式Tutorials の コードを修正して使用します。当然、Generator と Discriminator のネットワーク構造は同じです。
以下のセルのコードでCIFAR10 のデータセットをダウンロードします。
# Create the dataset transform = transforms.Compose([ transforms.Resize(image_size), transforms.CenterCrop(image_size), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainset = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=transform) dataloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=4, pin_memory=True)
ダウンロードされた CIFAR10 の最初の64枚の画像を以下に表示します。

Cifar-10 のデータセットを用いたケースのコードはこのGoogle Colabにアップしておきました。このコードを Colab で実行して確認してみて下さい。
10 epoch数の学習によるフェイク画像生成の結果は以下のようになります。

鮮明なフェイク画像を出すためには、epoch 数を100程度まで増加させる必要があります。ただ、時間がかかります。
この節の最後に、CelebA データセットを用いて、DCGAN のPython 実装をして、モデルの学習をしてみます。
ここで使用する Celeb-A Faces dataset は、mmlab.ie.cuhk.edu.hk/projects/CelebA.htmlから入手できますが、Google driveを利用します。このGoogle drive に行くと、CelebAのデータがアップされていますので、ディレクトリ /Img/ の中にある img_align_celeba.zip ファイルをダウンロードします。/celeba/ という新しいディレクトリを作成して、この中にzipファイルを解凍・展開します。約20万枚のface画像ファイルを含みます。サイズは約1.4ギガあります。celebA という名称は、セレブの人々の顔写真の集合という程度の意味です。
以下で説明するdcgan のコードは暗黙でGPUを前提にしていますので、ノートPCでは学習終了までに1日以上の時間が必要です。数時間の学習で切り上げるという手もありますが、Google Colab でGPU を利用して学習した方がベターです。dcganのコードを実行中に接続が切れる時がありますが、やむを得ません。Google Colab では約25分で学習は終了します。
それでは、DCGAN のプログラムの説明に入ります。必要なライブラリを import するコードは前節と同じなので、省略します。
CelebA のデータセットをダウンロードします。このGiHubのコードを利用して、CelebA をダウンロードします。
import requests
def download_file_from_google_drive(id, destination):
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination):
CHUNK_SIZE = 32768
with open(destination, "wb") as f:
for chunk in response.iter_content(CHUNK_SIZE):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params = { 'id' : id }, stream = True)
token = get_confirm_token(response)
if token:
params = { 'id' : id, 'confirm' : token }
response = session.get(URL, params = params, stream = True)
save_response_content(response, destination)
import sys
# TAKE ID FROM SHAREABLE LINK
file_id = "0B7EVK8r0v71pZjFTYXZWM3FlRnM"
# DESTINATION FILE ON YOUR DISK
destination = "img_align_celeba.zip"
download_file_from_google_drive(file_id, destination)
データセットを保存するディレクトリ /celeba/ を作成します。ダウンロードしたファイル img_align_celeba.zip を解凍して、ディレクトリ /content/celeba/ に展開します。
!mkdir /content/celeba !cp img_align_celeba.zip /content/celeba/ %cd /content/celeba/ !unzip img_align_celeba.zip %cd ..
# We can use an image folder dataset the way we have it setup.
# Create the dataset
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# Plot some training images
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))
学習で用いられた64枚のデータ画像が表示されます。このコードをGoogle Colabで実行してみて下さい。以下と同じ画像が表示されます。

学習ループを定義して、実際に学習してみます。実際に、Google Colabで実行してみて下さい。学習の経過は以下のように表示されます。
Starting Training Loop... [0/5][0/1583] Loss_D: 1.8664 Loss_G: 4.9949 D(x): 0.5050 D(G(z)): 0.5928 / 0.0106 [0/5][50/1583] Loss_D: 0.9210 Loss_G: 17.6558 D(x): 0.9809 D(G(z)): 0.4592 / 0.0000 [0/5][100/1583] Loss_D: 0.3781 Loss_G: 4.7942 D(x): 0.8840 D(G(z)): 0.0567 / 0.0439 [0/5][150/1583] Loss_D: 0.3246 Loss_G: 2.6198 D(x): 0.9260 D(G(z)): 0.1542 / 0.1485 [0/5][200/1583] Loss_D: 0.3635 Loss_G: 1.4417 D(x): 0.8331 D(G(z)): 0.0944 / 0.3049 [0/5][250/1583] Loss_D: 0.7100 Loss_G: 4.5035 D(x): 0.8746 D(G(z)): 0.3776 / 0.0206 [0/5][300/1583] Loss_D: 0.6694 Loss_G: 4.0361 D(x): 0.8410 D(G(z)): 0.3382 / 0.0268 [0/5][350/1583] Loss_D: 0.9349 Loss_G: 5.7440 D(x): 0.9294 D(G(z)): 0.5145 / 0.0061 [0/5][400/1583] Loss_D: 0.3928 Loss_G: 3.8426 D(x): 0.7994 D(G(z)): 0.1106 / 0.0331 [0/5][450/1583] Loss_D: 0.5034 Loss_G: 4.0665 D(x): 0.7266 D(G(z)): 0.0588 / 0.0288 [0/5][500/1583] Loss_D: 0.9713 Loss_G: 4.5079 D(x): 0.8745 D(G(z)): 0.4480 / 0.0256 [0/5][550/1583] Loss_D: 0.7846 Loss_G: 4.8868 D(x): 0.7768 D(G(z)): 0.3282 / 0.0129 ..
以下のコードを実行するとフェイク画像作成のアニメーションが作成されます。
#%%capture
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())
Google Colab のプログラムを用いて5回の epoch で作成されたフェイク画像は以下のように表示されています。実際の写真画像に比較すると、若干ぼやけていますが、結構上手くできています。

手持ちのノートPCで学習した結果では、ここまで鮮明なフェイク画像とはなりませんでした。手持ちのPCで実行するときには、このGoogle Colabのノートブックをダウンロードして、CelebA データセットをダウンロードして、そこへのパスを以下のように修正してください。
# Root directory for dataset dataroot = "./dataset/celeba/"
ディレクトリ /celeba/ の中に、img_align_celeba.zip を解凍して配置してください。ローカルのPCで実行してみたいときは、試みてください。
ConditionalGAN の Python 実装 |
DCGAN を拡張したモデルに Conditional GAN があります。DCGAN では生成するフェイク画像にクラスを指定できませんでした。生成するフェイク画像にクラスの指定を可能したアルゴリズムが Conditional GAN です。これを実現するために、Generator にラベルを導入して、各ラベルに対応したノイズを生成することが必要です。この時、各ラベルに対応したフェイク画像が生成されることになります。リアル画像にもラベルを貼り付けておけば、フェイクとリアル画像の識別も容易です。
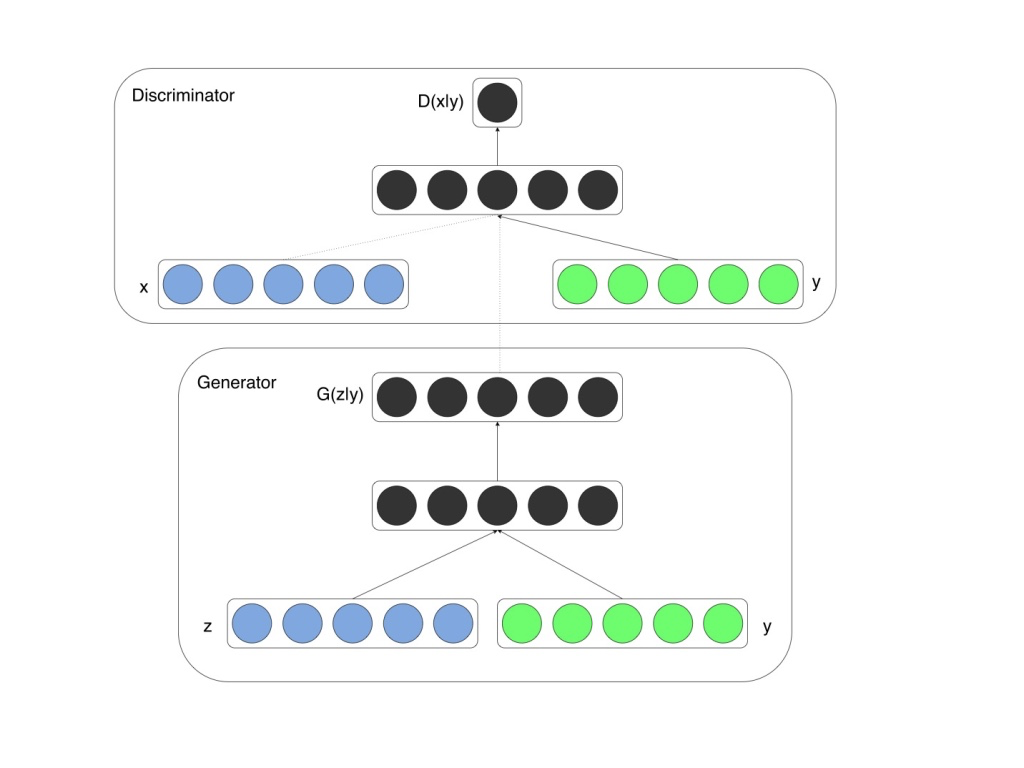
これが、Conditional GAN が学習する時の概念図です。生成する画像を明示的に書き分けるために、訓練時に教師データのカテゴリ(ラベル)情報 (y) を用います。ラベルは One-Hot 形式にします。
ノイズベクトル入力 (z) に、例えば、ラベル番号1をOne-Hot形式にした [ 0 , 1, 0 ] を加算します。ノイズベクトル z の次数が 100 のとき、Generator への入力ベクトルは 100次元+3 = 103 次元となります。
生成画像の方は、ラベル番号1をOne-Hot形式にした [ 0, 1, 0 ] を、さらに画像のサイズに拡大します。0だけで埋まった64×64の画像(真っ黒な画像)と1だけで埋まった64×64の画像(真っ白な画像)を作って、チャンネルに追加します。従って、 画像のチャネル数は 3ch +3 = 6 ch となります。
このような形で、画像を学習する時に、ラベル情報も合わせて学習することで、学習後は、Generator のノイズ入力に、指定したラベル番号を付加することで、生成画像のクラスのコントロールが可能になります。
ConditionalGAN では、One-Hot 形式で画像およびノイズにラベルを連結する必要がるので、以下のコードでこれを実現します。
def onehot_encode(label, device, n_class=10): """ カテゴリカル変数のラベルをOne-Hoe形式に変換する :param label: 変換対象のラベル :param device: 学習に使用するデバイス。CPUあるいはGPU :param n_class: ラベルのクラス数 :return: """ eye = torch.eye(n_class, device=device) # ランダムベクトルあるいは画像と連結するために(B, c_class, 1, 1)のTensorにして戻す return eye[label].view(-1, n_class, 1, 1) def concat_image_label(image, label, device, n_class=10): """ 画像とラベルを連結する :param image: 画像 :param label: ラベル :param device: 学習に使用するデバイス。CPUあるいはGPU :param n_class: ラベルのクラス数 :return: 画像とラベルをチャネル方向に連結したTensor """ B, C, H, W = image.shape # 画像Tensorの大きさを取得 oh_label = onehot_encode(label, device) # ラベルをOne-Hotベクトル化 oh_label = oh_label.expand(B, n_class, H, W) # 画像のサイズに合わせるようラベルを拡張する return torch.cat((image, oh_label), dim=1) # 画像とラベルをチャネル方向(dim=1)で連結する def concat_noise_label(noise, label, device): """ ノイズ(ランダムベクトル)とラベルを連結する :param noise: ノイズ :param label: ラベル :param device: 学習に使用するデバイス。CPUあるいはGPU :return: ノイズとラベルを連結したTensor """ oh_label = onehot_encode(label, device) # ラベルをOne-Hotベクトル化 return torch.cat((noise, oh_label), dim=1) # ノイズとラベルをチャネル方向(dim=1)で連結する
このコードは、『PyTorch ニューラルネットワークの実装ハンドブック』(秀和システム、1999) で提供されているコードです。
MNIST データセット使って、手書き数字のフェイク画像を生成しましょう。MNIST データセットのダウンロードはすでに取り扱いましたので、ここでは省略します。コード全体はこの Google Colab にあります。
ラベルに従って、フェイク画像を作成した例が以下の画像になります。10 epoch の学習を行いました。

epoch 数を20程度まで増加させるともっと鮮明なフェイク画像が得られます。
次に、STL!0 データセットを用いた例を取り上げます。データセット STL10 は、以下のコードでダウンロードします。
trainset = dset.STL10(root='./dataset/stl10_root', download=True, split='train',
transform=transforms.Compose([
transforms.RandomResizedCrop(64, scale=(88/96, 1.0), ratio=(1., 1.)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.05, contrast=0.05, saturation=0.05, hue=0.05),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])) # ラベルを使用するのでunlabeledを含めない
testset = dset.STL10(root='./dataset/stl10_root', download=True, split='test',
transform=transforms.Compose([
transforms.RandomResizedCrop(64, scale=(88/96, 1.0), ratio=(1., 1.)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.05, contrast=0.05, saturation=0.05, hue=0.05),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
dataset = trainset + testset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=int(workers))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device:', device)
ダウンロードした画像のサンプルは以下の通りです。

Conditional GAN の PyTorch コードは この colab にアップしておきました。このコードで、50回ほどのepoch数で学習すると、以下のようなフェイク画像が生成されます。

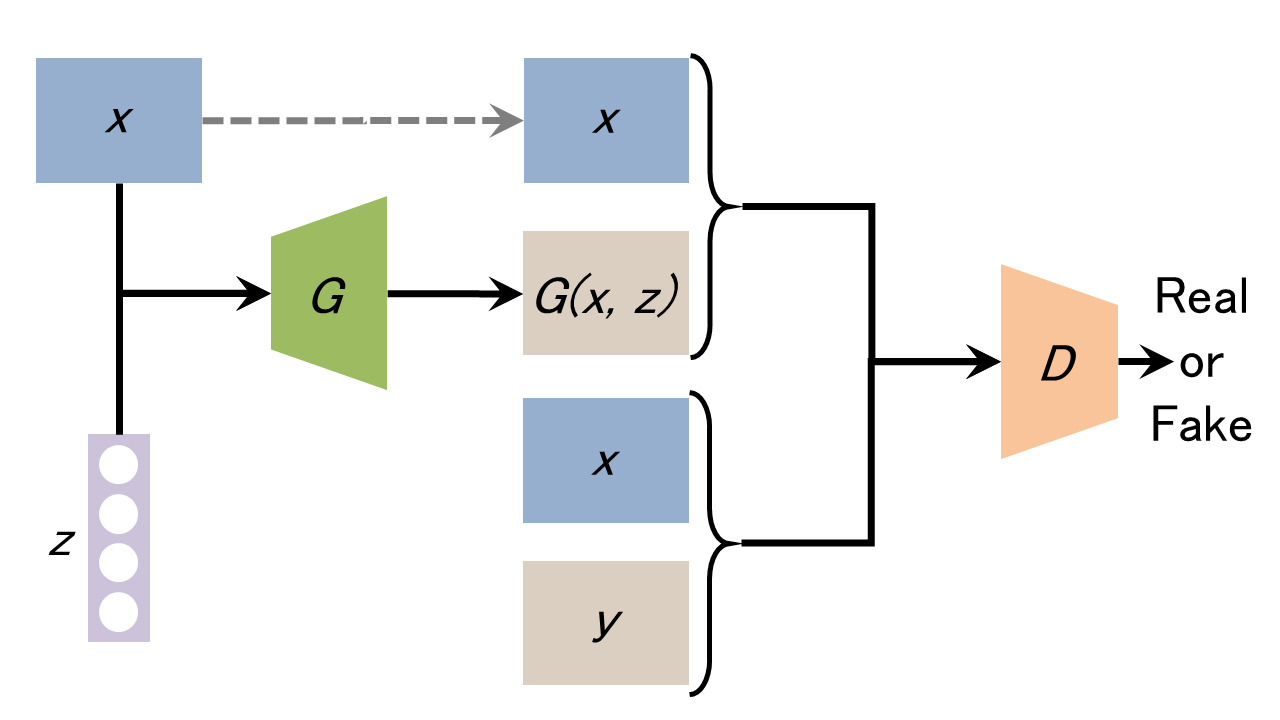
ConditionalGAN の変種に、pix2pix というモデルがあります。 pix2pix モデルの概念図は下の様になります。
CycleGAN の Python 実装 |
DCGAN を拡張した ディープラーニングの手法に CycleGAN があります。論文"Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks"で提案されたアルゴリズムがCycleGAN と呼ばれています。このアルゴリズムを用いると、ゼブラの画像を馬の画像に変換したり、風景写真をモネやゴッホの絵のように変換することが容易にできます。pix2pix のように、白黒写真をカラー画像に変換することもできます。著者たちの web site はCycleGAN Project Pageになります。この Github サイトで、CycleGAN のコードも公開しています。この公開されたコードを使った CycleGAN の Pytorch での実装例を取り上げます。
CycleGAN の基本構造は以下のようになっています。モデルを学習するためには、二つのカテゴリに分類された画像の集合が必要です。例えば、馬の画像の集合とゼブラの画像の集合のように、異なる2種類の画像の集合です。これらの2種類の画像の集合をそれぞれ Domain X、Domain Y(数学での定義域のことです)と呼ぶことにします。馬の画像からゼブラの画像への変換は、数学的には、Domain (定義域) Xから Domain (定義域) Yへの写像(関数)G となります。ゼブラの画像から馬の画像への変換は、Domain (定義域) Yから Domain (定義域) Xへの写像(関数)F となります。写像 F(y) は写像 G(x) の逆写像になります。
このモデルには「XからYへの写像 G」と「YからXへの写像 F」に対応する二つの生成器(generator)が必要です。そして、学習のために、「ドメインXの画像xを変換したG(x)」のフェイク画像とリアル画像y との真偽を判定するための識別器と、「ドメインYの画像F(y)」に対応する識別器も必要です。学習の手順は、まず、ターゲットのdomain Y の画像と区別のつかないようなフェイク画像を生成する写像G(X)を敵対的損失(adversarial losses)を用いて学習させます。次に、 逆写像 F(G(x)) が作成するフェイク画像がドメインXのリアル画像と区別できないようになるまで、学習します。例えば、英語から日本語に変換する写像をF(x) とすると、G(y) は日本語から英語に翻訳する写像になります。この時、英語から日本語に翻訳して、それをさらに、英語に翻訳するとき、もとの英文と一致するまで、翻訳機を学習させます。つまり、cycle consistency losses を最小化する(cycle consistent な)写像が実現できるように学習を繰り返すことになります。ここで、forward cycle-consistency loss( x → G(x) → F (G(x)) ≈ x を学習する時の損失)という概念と, backward cycle-consistency loss(y → F (y) → G(F (y)) ≈ yを学習する時の損失)という概念が登場します。この意味で、 CycleGAN という名称で呼ばれることになったのです。
上記の論文の著者たちが自ら公開したコードが公開されています。Pytorch を用いた Python 実装例はこの GitHub Repoにあります。Tensorflowを使用したコードはこのTutorials にあります。ここでは、Pytorch のコードを取り上げます。
以下の画像は「CycleGAN Project Page」で紹介されている、CycleGAN を用いて作成した画像変換の例です。
以下では、私の Github Repo にあるコードを ローカルのPC、もしくは Google Colab に git clone して、利用する時の説明をします。Google Colab で git clone するコードは この Google Colab にあります。展開されたフォルダー内に、datasets 、 scripts などのフォルダーやpythonファイル等があります。
CycleGAN.ipynb の使用法について、簡単に説明します。以下のコードを用いて画像のデータセット(horse2zebra)をダウンロードします。
!bash ./datasets/download_cyclegan_dataset.sh horse2zebra
なお、用意されているデータセットは以下のとおりです。
apple2orange, orange2apple, summer2winter_yosemite, winter2summer_yosemite,
horse2zebra, zebra2horse, monet2photo,
style_monet, style_cezanne, style_ukiyoe, style_vangogh,
sat2map, map2sat, cityscapes_photo2label, cityscapes_label2photo,
facades_photo2label, facades_label2photo, iphone2dslr_flower
データセットの読み込みをすると、 CycleGAN-and-pix2pix 内のディレクトリ /datasets/の下に、サブホルダー(例えば、horse2zebra)が作成されます。その中に、フォルダー testA, testB, trainA, and trainB が作成されて、この中に使用する画像が保存されます。例えば、testA に zebra2horse 、testB に horse2zera の画像が配置されます。同様に、学習用の画像をtrainA 、trainB にも配置します。
次に、学習済みモデルをダウンロードします。学習済みモデルは、ディレクトリ ./checkpoints/ に保存されます。例えば、./checkpoints/horse2zebra_pretrained/latest_net_G.pt となります。
!bash ./scripts/download_cyclegan_model.sh horse2zebra
モデルの学習は以下のコードを用います。
!python train.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
ノートPCでこの学習をすると結構時間(1日)が必要とされます。Google Colab の GPU を活用するときも、途中で接続が切れますので、注意ください。一つのepochに6分程度かかりますので、10 epoch だと1時間以上かかります。ここでは、学習をせず、学習済みモデルを利用する方法を説明します。
学習済みモデルを使用して、画像のスタイル変換を実行したときの結果を見ることができます。以下のコードを入力してください。
!python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
以下のような表示が出ます。
----------------- Options ---------------
aspect_ratio: 1.0
batch_size: 1
checkpoints_dir: ./checkpoints
crop_size: 256
dataroot: datasets/horse2zebra/testA [default: None]
dataset_mode: single
direction: AtoB
display_winsize: 256
epoch: latest
eval: False
gpu_ids: 0
init_gain: 0.02
init_type: normal
input_nc: 3
isTrain: False [default: None]
load_iter: 0 [default: 0]
load_size: 256
max_dataset_size: inf
model: test
model_suffix:
n_layers_D: 3
name: horse2zebra_pretrained [default: experiment_name]
ndf: 64
netD: basic
netG: resnet_9blocks
ngf: 64
no_dropout: True [default: False]
no_flip: False
norm: instance
ntest: inf
num_test: 50
num_threads: 4
output_nc: 3
phase: test
preprocess: resize_and_crop
results_dir: ./results/
serial_batches: False
suffix:
verbose: False
----------------- End -------------------
dataset [SingleDataset] was created
initialize network with normal
model [TestModel] was created
loading the model from ./checkpoints/horse2zebra_pretrained/latest_net_G.pth
---------- Networks initialized -------------
[Network G] Total number of parameters : 11.378 M
-----------------------------------------------
creating web directory ./results/horse2zebra_pretrained/test_latest
processing (0000)-th image... ['datasets/horse2zebra/testA/n02381460_1000.jpg']
processing (0005)-th image... ['datasets/horse2zebra/testA/n02381460_1110.jpg']
processing (0010)-th image... ['datasets/horse2zebra/testA/n02381460_1260.jpg']
processing (0015)-th image... ['datasets/horse2zebra/testA/n02381460_1420.jpg']
processing (0020)-th image... ['datasets/horse2zebra/testA/n02381460_1690.jpg']
processing (0025)-th image... ['datasets/horse2zebra/testA/n02381460_1830.jpg']
processing (0030)-th image... ['datasets/horse2zebra/testA/n02381460_2050.jpg']
processing (0035)-th image... ['datasets/horse2zebra/testA/n02381460_2460.jpg']
processing (0040)-th image... ['datasets/horse2zebra/testA/n02381460_2870.jpg']
processing (0045)-th image... ['datasets/horse2zebra/testA/n02381460_3040.jpg']
フェイク画像とリアル画像の比較をしたいと思います。
import matplotlib.pyplot as plt
img = plt.imread('./results/horse2zebra_pretrained/test_latest/images/n02381460_1030_fake.png')
plt.imshow(img)
import matplotlib.pyplot as plt
img = plt.imread('./results/horse2zebra_pretrained/test_latest/images/n02381460_1030_real.png')
plt.imshow(img)
左の画像が馬からゼブラにスタイルを変換したフェイク画像で、右の画像は馬の写真です。
|
|
|
もう一つの例を取り上げます。上記のコードの後で、ダウンロードするデータを変更してみましょう。モネの絵画から浮世絵風フェイク画像に変換させてみましょう。ダウンロードのコードを以下のように変更します。
!bash ./datasets/download_cyclegan_dataset.sh monet2photo !bash ./scripts/download_cyclegan_model.sh style_ukiyoe
テストをします。
!python test.py --dataroot datasets/monet2photo/testA/ --name style_ukiyoe_pretrained --model test --results_dir results/ --no_dropout
結果を見てみましょう。
import matplotlib.pyplot as plt
img = plt.imread('./results/style_ukiyoe_pretrained/test_latest/images/00030_fake.png')
plt.imshow(img)
import matplotlib.pyplot as plt
img = plt.imread('./results/style_ukiyoe_pretrained/test_latest/images/00030_real.png')
plt.imshow(img)
左がフェイク画像、右がモネの絵です。
|
|
|
我が家の愛犬アンジーの写真をゴッホ風絵画のイメージに変換しました。好みのオリジナルの写真の画像集は、ディレクトリ /datasets/ の下に新しくサブフォルダ /photo2image/testA, testB のように作成して、testAの中に配置してください。testBは内容はtestA と同じにしましたが、中身はなくても大丈夫なようです。
!bash ./scripts/download_cyclegan_model.sh style_vangogh !python test.py --dataroot datasets/photo2image/testA --name style_vangogh_pretrained --model test --results_dir results/ --no_dropout
と入力します。そして、
import matplotlib.pyplot as plt
img = plt.imread('./results/style_vangogh_pretrained/test_latest/images/IMG_0069_fake.png')
plt.imshow(img)
とフェイク画像を表示させます。
|
|
|
style の学習済みモデルを利用するだけなら、ノートブックPCでも色々と遊べますね。しかし、モデルの学習には相当の時間がかかります。GPU を用いても、10時間程度はかかると思われます。手元のノートPCを使用する時は、これが難点ですね。
StyleGAN の Python 実装 |
StyleGAN と呼ばれる CycleGAN よりも精度の高い変換を目指したアルゴリズムが登場しています。解像度は1024×1024という高解像度です。original StyleGAN とその改良版 StyleGAN2 があります。YouTube の紹介Videoは https://youtu.be/c-NJtV9Jvp0 です。 TensorFlow での実装コードはこの GitHub にあります。この Google Drive には追加的ファイル等がアップされています。
原論文の著者たちが提供したコードは、高速なGPU を集中的に使用することを前提にしているので、個人が趣味的に Colab で実証できるものではありません。ちなみに、StyleGANの学習は、データセットとして1024×1024の画像70,000枚を使って行うのですが、V100というかなりハイグレードのGPUを8台並列で使っても6日と14時間掛かるらしいです。pretrained modelを読み込むときも GPU を前提としています。
ここでは、pretrained model を用いた画像の生成だけを取り上げます。論文の著者たちのコードを用いて、Google Colab で Tensorflow の pretrained model を読み込むセルを実行すると、「 Google Drive quota exceeded 」と表示が出てランタイムが終了してしまいます。この難点を避けるために、 pretrained model を/My Drive/ に保存してから、読み込むことにします。
まず初めに、StyleGANS 関連のコードをダウンロードしましょう。以下のコードは、 この Colab にあるので、これを実行できます。Google Colab に行って、ノートブックのセルを順番に実行します。
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/My Drive
!mkdir stylegans
%cd stylegans
!mkdir stylegans_dir
stylegan 関連の GitHub Repo をダウンロードします。
!git clone https://github.com/NVlabs/stylegan.git !git clone https://github.com/NVlabs/stylegan2.git著者配布の学習済みモデルの'karras2019stylegan-ffhq-1024x1024.pkl' をダウンロードして、ディレクトリ /datasets/ に保存します。このファイルは、この Google Drive にあります。このダウンロードした pretrained model を Google Drive の datasets にアップロードして下さい。これが終了したら、以下のセル以降を実行します。
%cd /content/drive/My Drive/stylegans/stylegan
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
# Initialize TensorFlow.
tflib.init_tf()
# Load pre-trained network.
*_, Gs = pickle.load(open('../datasets/karras2019stylegan-ffhq-1024x1024.pkl','rb'))
これで URL を使用しないで、pretrained model が読み込まれます。
2つのハイパーパラメータ( RandomState の値、truncation_psi の値 )を変えることで様々な種類・見た目の画像が生成できます。以下のコードでは、RandomState(210)、truncation_psi=0.7 となっています。
# Pick latent vector. rnd = np.random.RandomState(210) latents = rnd.randn(1, Gs.input_shape[1]) # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt) # Save image. result_dir='results' !makdir datasets os.makedirs(config.result_dir, exist_ok=True) png_filename = os.path.join(config.result_dir, 'example210.png') PIL.Image.fromarray(images[0], 'RGB').save(png_filename)
生成した画像を表示してみます。
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
#画像内に線を表示しない
fig,ax = plt.subplots()
ax.tick_params(labelbottom="off",bottom="off")
ax.tick_params(labelleft="off",left="off")
ax.set_xticklabels([])
ax.axis('off')
#画像の読み込み
im = Image.open("results/example210.png")
#画像をarrayに変換
im_list = np.asarray(im)
#貼り付け
plt.imshow(im_list)
#表示
plt.show()

顔の向き・顔のパーツ・髪型に関してはDestinationのスタイルをそのまま使い、背景の色や髪の色などの細かい部分はSourceのスタイルを使う、等々と変化させることにより、スタイルミックスの画像を生成することができます。詳しい解説はこのweb site に解説がありますので、参考にして下さい。以下に例を表示します。

ここまでの StyleGAN のコードでは、Tensorflow での pretrained model を使用することを前提としていました。
Pytorch で即使用可能な pretrained model を用いたコードを紹介します。この Google Colab にアップロードしましたので、利用して下さい。以下のコマンドを使用して、Pytorch 向けの pretrained model をダウンロードします。
! wget https://github.com/lernapparat/lernapparat/releases/download/v2019-02-01/karras2019stylegan-ffhq-1024x1024.for_g_all.pt
解像度は低いですが、以下の画像が生成されます。

ハイパーパラメータを変化させて、多種な画像を生成させてみて下さい。
次に、Tensorflow のpretrained model を Pytorch 用に変換して用いましょう。扱いやすいコードがこの GitHub のサイトにありますので、これを利用しましょう。
まず初めに、StyleGANS 関連のコードをダウンロードしましょう。以下のコードは、 この Colab にあるので、これを実行します。
from google.colab import drive
drive.mount('/content/drive')
と入力して、Drive を mount します。次に必要なディレクトリを作成します。
%cd /content/drive/My Drive !mkdir stylegans %cd stylegans !mkdir stylegans_dir
stylegan 関連の GitHub Repo をダウンロードします。
!git clone https://github.com/NVlabs/stylegan.git #!git clone https://github.com/NVlabs/stylegan2.git !git clone https://github.com/yuuho/stylegans-pytorch
以下では、 stylegan2 は使用しないので、ダウンロードは必要ではありません。著者配布学習済みモデルの'karras2019stylegan-ffhq-1024x1024.pkl' をダウンロードして、ディレクトリ /stylegans_dir/ に保存します。このファイルは、この Google Drive にあります。このダウンロードした pretrained model を Google Drive の stylegans_dir にアップロードして下さい。Tensorflow で作成された trained model を使用するために
!cp stylegans-pytorch/packaged/run_tf_stylegan1.py stylegan/
とします。著者たちのオリジナルコードは、Tensorflow 2.x には対応していないので
# For the old version: %pip install tensorflow==1.15
とダウングレードします。
%cd stylegans/stylegan !python run_tf_stylegan1.py -w ../datasets -o ../datasets %cd ..
!python stylegans-pytorch/packaged/run_pt_stylegan1.py -w datasets -o datasets
このコード実行により、以下の顔の画像が生成されます。画像は /datasets/ に保存されます。






