
|
敵対的生成ネットワーク (GAN, Generative Adversarial Networks) は、機械学習の分野で最も興味深いアルゴリズムの一つです。このネットワーク・モデルには、Generator と Discriminator という2 つのネットワークが組み込まれています。この2種類のネットワークが敵対するような関係になることからこの名称で呼ばれます。generator (「芸術家」the artist) がリアルに見える画像(フェイク画像)を作成することを学習し、その一方で、 discriminator (「芸術評論家」 the art critic」) がフェイク画像からリアル画像を識別することを学習します。現在、こうした GANs のモデルをさまざまに拡張したディープラーニングのモデルが提案されています。
特に、CycleGAN と類似していますが、上で見たように、ある画像を別のスタイルの画像に変換する、写真をモネ風やゴッホ風の画像に変換する便利な手法が提案されています。
このページでは、Neural Style Transfer およびその拡張版のFast Neural Style Transfer モデルの Python 実装について説明します。使用する Python API は Pytorch と TensorFlow です。これらのコードを実行するには、GPU を使用できないノートPCでは時間がかかり過ぎるので、Google Colab などの無料GPU サービスを利用する方が便利です。
この理由から、このページで取り上げるコードはGoogle Colabで実証できるように準備しました。また、私のGithub Repoに4種類のコード neural_style、 neural style transfer 、 fast-style-transfer、および、fast_neural_styleを用意しましたので、ご利用ください。
私の GitHub Repo からローカル PC にフォルダーを git clone して、この PC でコードを利用する方法では、トラブルは少ないと思います。Google Colab の /My Drive/ にフォルダーを git clone する方法も、ファイルの中身が見えるので、問題は少ないと思います。Google Colab の /content/ に直接 git clone するケースでは、ファイルのコードを編集するなどの操作をするためには、Linux の知識が必要となりますので、ご注意ください。
Last updated: 2020.4.4 (first uploaded 2020.3.8)
Deep Dream の使用法 |
最初に、最も分かりやすいスタイル変換プログラムである DeepDream というソフトを取り上げます。言うまでもなく、DeepDream は、 GoogleのエンジニアであるAlexander Mordvintsevによって作成されたコンピュータービジョンのプログラムです。 「このソフトウエアは、 畳み込みニューラルネットワークを使用し、アルゴリズムのパレイドリアを介して画像の中にパターンを検出および強化し、意図的に過剰処理することで、夢のような幻覚的な画像を生成する。このGoogleのプログラムは、「深く夢見る (deep dreaming)」という用語を普及させ、訓練されたディープネットワークにより望みの活性化処理を施し、画像を生成することを指すようになった。」(Wikipedia から引用) Google が公開したコードは、このGitHub Repoにあります。
この DeepDream のコードは、Tensorflow の Tutorials からアクセスできます。 この Google Colab でも実行できます。
DeepDream の骨格は以下のようになっています。
base_model = tf.keras.applications.InceptionV3(include_top=False, weights='imagenet') # Maximize the activations of these layers names = ['mixed3', 'mixed5'] layers = [base_model.get_layer(name).output for name in names] # Create the feature extraction model dream_model = tf.keras.Model(inputs=base_model.input, outputs=layers)
このコードから理解されるとおり、DeepDream が採用しているネットワーク構成は InceptionV3 と呼ばれるモデルです。generator と discrinimator から構成されるGANs のような構成にはなっていません。周知の通り、InceptionV3 は Google が開発した CNN モデルです。以下のコードが損失の計算最適化のモジュールとなっています。学習用のモジュールを説明することは詳細は省略します。
class DeepDream(tf.Module):
def __init__(self, model):
self.model = model
@tf.function(
input_signature=(
tf.TensorSpec(shape=[None,None,3], dtype=tf.float32),
tf.TensorSpec(shape=[], dtype=tf.int32),
tf.TensorSpec(shape=[], dtype=tf.float32),)
)
def __call__(self, img, steps, step_size):
print("Tracing")
loss = tf.constant(0.0)
for n in tf.range(steps):
with tf.GradientTape() as tape:
# This needs gradients relative to `img`
# `GradientTape` only watches `tf.Variable`s by default
tape.watch(img)
loss = calc_loss(img, self.model)
# Calculate the gradient of the loss with respect to the pixels of the input image.
gradients = tape.gradient(loss, img)
# Normalize the gradients.
gradients /= tf.math.reduce_std(gradients) + 1e-8
# In gradient ascent, the "loss" is maximized so that the input image increasingly "excites" the layers.
# You can update the image by directly adding the gradients (because they're the same shape!)
img = img + gradients*step_size
img = tf.clip_by_value(img, -1, 1)
return loss, img
deepdream = DeepDream(dream_model)
このノートブックを実行すると、処理される画像としてラブラドール犬の写真(YellowLabradorLooking new.jpg)が読み込まれます。その後で、変換された後の画像は以下のように表示されます。
現在、画像変換のDeep Dream を web 上で利用可能にした Deep Dream Generatorの公式サイトはこちらです。
この Deep Dream Generator の利用の仕方について説明します。(取説がどこにもないので、自己流です)上記の Deep Dream Generator の web site に行きます。ログインをします。Facebook などのアカウントを持っていれば、新しく登録しなくてもログインできます。ログインしたら、右上にある「Generate」をクリックします。次に、「Upload Image」をクリックしたら、PC内にある好みの写真画像を選択して、アップロードします。「Deep Style」「Thin Style」「Deep Dream」のどれかを選びます。その後、「Choose Style Image」の中から好みのものを選択して、「Generate」します。「Access?」は取り敢えず「Keep it private」にして下さい。しばらくすると、編集された画像が表示されます。これで完了です。
トップページ(Home)に表示されている以下の画像はこの Deep Dream Generator を用いて作成したものです。

江ノ島に落ちる夕日 |

ゴッホ風の画像 |
上記のサイトで使用できる画像生成の種類は固定されています。もっと自由度の高い画像編集を実現するためには、以下に説明する CycleGANs の変形バージョンである Style Transfer を活用する方が便利です。
Neural Style Transfer の Tensorflow 実装 |
CycleGAN と類似していますが、上で見たように、ある画像を別のスタイルの画像に変換する、例えば、写真をゴッホ風や浮世絵風の画像に変換する便利な手法が、2015年にA Neural Algorithm of Artistic Style (by Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge)と言うタイトルの論文 で提案されています。このアルゴリズムは、CycleGAN に比較すると、学習済みCNNを使用することから、何百倍も処理時間が早くなります。使用される代表的なCNN は VGG19 です。このアルゴリズムは、省略形で、Style Transfer または Neural Transfer などとも呼ばれています。CycleGAN と Style Transfer の関係については、 この解説を参照ください。
このアルゴリズムを Python で実装した例は、Tensorflow の公式Tutorials および Pytorch 公式ページに説明があります。Tensorflow を用いた例は、このColabにコピーしてあります。また、Pytorch の例はこのColab で実行できる形にしています。
簡単な説明をします。Gatys らのモデルは、畳み込みニューラルネットワーク(convolutional neural network, CNN)を使用していて、VGG モデルがベースになっています。アルゴリズムのキーとなるアイデアは、画像のコンテンツとスタイルの分離です。スタイル抽出には、このVGGから全結合層を取り除いたものを使用します。
以下の図を見てみください。CNNの各層において画像がどのように特徴表現されているかを表す図です。
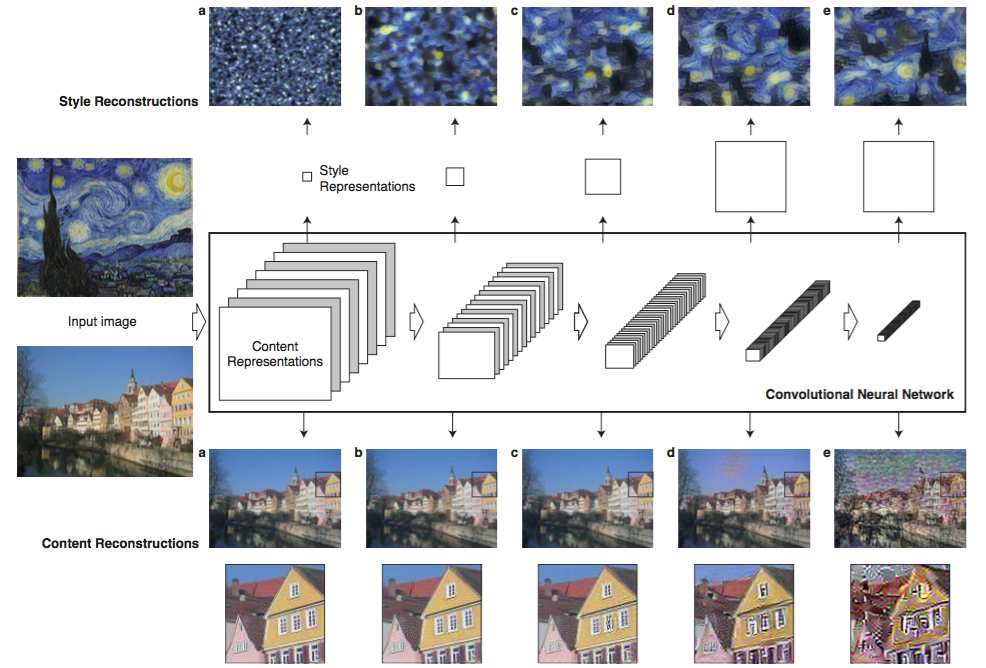
Gatys et al. 2016より引用
上段はスタイル画像、 下段はコンテンツ画像の特徴マップに対応します。a, b, c, d, eはそれぞれconv1_2, conv2_2, conv3_2, conv4_2, conv5_2に対応する特徴画像です。
まずは、下段を見てみます。これらの画像はそれぞれの層において、入力画像を復元したものです。a, b, cまでは元の入力画像とほとんど変わらないように見えますが、d, eでは詳細な情報が落ちてきているように見えます。VGGは元々画像を分類する目的で訓練されています。深い層に行くにつれて、分類するにあたって重要なコンテンツが残り、それとはあまり関係のない詳細な見た目などの情報は落ちていっています。これはコンテンツとスタイルをある程度分離することができているとも考えられます。
この性質をうまく利用し、コンテンツを保ったままスタイルを別のものと入れ替えることを考えます。画像のコンテンツ表現とスタイル表現を用いることで、画像間のコンテンツとスタイルの類似度(損失)を別々に求めることができます。VGG を使ってコンテンツ画像のコンテンツとスタイル画像のスタイルに類似する画像を生成するようにホワイトノイズを更新して、画像を再生成します。
したがって、この問題はコンテンツとスタイルの損失を最小化する最適化問題として解くことができます。コンテンツの損失は、conv4_2において、コンテンツ画像と生成画像を比較することによって計算します。このプロセスを図式化したのが下の図です。
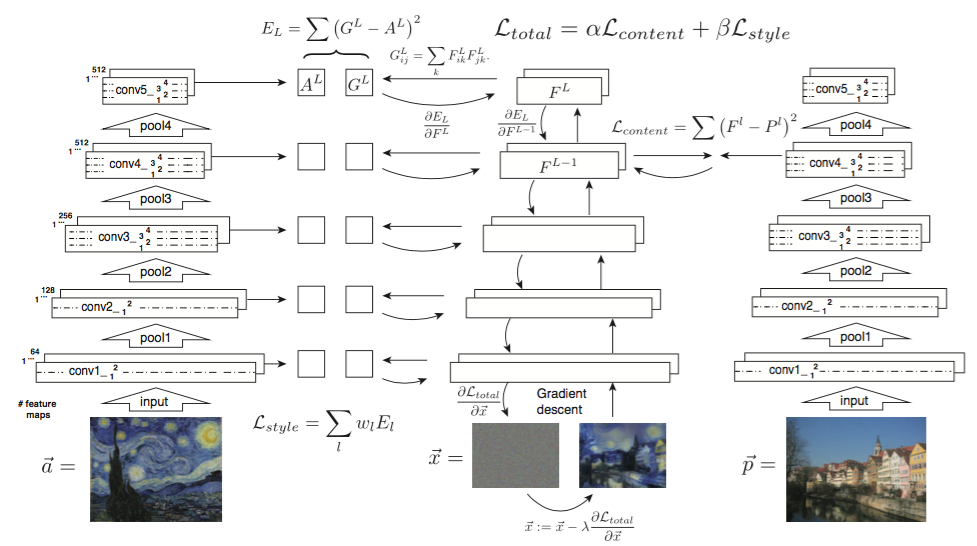
Gatys et al. 2016より引用
左側には、各レイヤーで style 画像のスタイル表現が抽出、保存される様子が図式化されています。右側には、各レイヤーで content 画像のコンテンツ表現が保存される過程を描いています。中央には、ノイズ画像から新しい画像を生成する学習過程を図式化しています。
Gatys らの論文で発表された画像変換の結果は以下の画像です

Gatys et al. 2016より引用
ここで、Keras を用いて neural style transfer のアルゴリズムを実装したコードを取り上げます。Keras の公式 GitHub Repo でアップされている例を見てみましょう。ただ、このコードはTensorflow 2.0 には対応していません。Tensorflow 1.15 にダウングレードして下さい。
手持ちのPCで実装するときは、https://keras.io/examples/neural_style_transfer/の Python コードをコピペして、 neural_style_transfer.py を作成します。neural_style_transfer.py の中は以下のようのコードで構成されています。内容の説明は省略します。
以下の様なディレクトリ構成にします。
neural_style_transfer.py # python コード
img/ # 入力画像を配置するフォルダー
kamakura.jpg
style/ # 用いるスタイルの画像
picasso.jpg
results/ # 変換結果が保存されるフォルダー
result_at _iteration_9.png
私の GitHub Repo をダウンロードする方が簡単でしょう。このとき、以下のディレクトリ構成になっています。
. ├── LICENSE ├── README.md ├── img │ ├── akadake_1.jpg │ ├── akadake_2.jpg │ ├── chicago.jpg │ ├── dancing.jpg │ ├── enoshima_1.jpg │ ├── enoshima_2.jpg │ ├── escher_sphere.jpg │ ├── golden_gate.jpg │ ├── kamakura.jpg │ ├── kiyoharu.jpg │ ├── makiba.jpg │ ├── minato_mirai.jpg │ ├── seisenryo.jpg │ └── tubingen.jpg ├── neural_style_transfer.py ├── results │ └── result ├── style │ ├── frida_kahlo.jpg │ ├── gogh_1.jpg │ ├── gogh_2.jpg │ ├── gogh_3.jpg │ ├── matisse.jpg │ ├── picasso_1.jpg │ ├── picasso_2.jpg │ ├── picasso_3.jpg │ ├── rain_princess.jpg │ ├── shipwreck.jpg │ ├── starry_night.jpg │ ├── the_scream.jpg │ ├── udnie.jpg │ └── wave.jpg └── style_transfer.ipynb
このRepo を Google Colab に git clone して、実行するためのノートブックは この Colab にアップロードしてあります。ご利用ください。
基本的なスタイル変換のコマンドは neural_style_transfer.py を実行することになります。オプションは以下のようにします。コンテンツ画像、スタイル画像、生成される画像のファイル名のプレフィックスを引数にします。
!python neural_style_transfer.py path_to_your_image.jpg path_to_your_style.jpg prefix_for_results
ノートブックでは、以下のようになっています。
!python neural_style_transfer.py img/kamakura.jpg style/picasso.jpg results/my_kamakura
このコマンドを実行すると、 results/ の中に、
my_kamakura_at_iteration_1.png ... my_kamakura_at_iteration_9.png
というファイル名の画像が10枚生成されます。以下の画像が my_kamakura_at_iteration_9.png を表示したものです。

鎌倉八幡宮のピカソ風スタイルの画像
フォルダー img と style にはそれぞれ十枚以上の画像を用意しています。色々と組み合わせを変えて、画像の変換を楽しんでください。
上でも触れた通り、このKeras のコードはTensroflow 1.15 をサポートしてますが、Tensorflow 2.0 以降ではエラーが出ます。このため、手持ちのPCに Tensorflow 2.0 がインストールしてある時は、このコードは正常に作動しません。なので、Google Colab を利用する方が得策です。実行する前に、ランタイムの設定を GPU に切り替えた方が処理スピードが速くなります。
Tensorflow の公式サイトでの Tutorials は、tensorflow_style_transfer.ipynb になります。なお、Google Colab の 公式 Documentation に Neural Style Transfer with tf.keras が掲載されていますので、これも参考になります。後者の方がより多様な例が実行できます。
スマホ用アプリ Prisma のサーバーには、この neural style transfer のアルゴリズムを用いた技術が使用されています。
Style Transfer の Pytorch 実装 |
この節では、 Pytorch の Neural Algorithm of Artistic Style の実装コード neural_style_tutorial.ipynb を用いて画像変換を実際に行うことにします。この https://github.com/mashyko/neural_style を git clone してご利用下さい。
この GitHub Repo には、ディレクトリ内に、/images/ というフォルダーが作成してあります。フォルダー/images/内に、content 用の画像として enoshima_1, 2.jpg、makiba.jpg など、また、Style 用の画像として udnie.jpg 、gogh_1,2.jpg などの画像が配置されています。
最初に、Google Colab の /My Drive/ に git clone して、このコードを実行するケースについて説明します。Google Colab で新規でノートブックを作成し、以下のセルを入力します。
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/My Drive/
! git clone https://github.com/mashyko/neural_style
これを実行するとすると、/My Drive/ の下に neural_style という名前ののフォルダーが作成されます。これが確認されたら、このノートブックは閉じて下さい。フォルダーの構成は以下の通りです。
. ├── images │ ├── content │ │ ├── akadake_1.jpg │ │ ├── akadake_2.jpg │ │ ├── chicago.jpg │ │ ├── dancing.jpg │ │ ├── enoshima_1.jpg │ │ ├── enoshima_2.jpg │ │ ├── escher_sphere.jpg │ │ ├── golden_gate.jpg │ │ ├── kamakura.jpg │ │ ├── kiyoharu.jpg │ │ ├── makiba.jpg │ │ ├── minato_mirai.jpg │ │ ├── seisenryo.jpg │ │ └── tubingen.jpg │ ├── output │ │ ├── anzie_picaso.jpg │ │ ├── brad_fake.jpg │ │ └── makiba_gogh.png │ └── style │ ├── frida_kahlo.jpg │ ├── gogh_1.jpg │ ├── gogh_2.jpg │ ├── gogh_3.jpg │ ├── matisse.jpg │ ├── picasso_1.jpg │ ├── picasso_2.jpg │ ├── picasso_3.jpg │ ├── rain_princess.jpg │ ├── shipwreck.jpg │ ├── starry_night.jpg │ ├── the_scream.jpg │ ├── udnie.jpg │ └── wave.jpg └── neural_style_tutorial.ipynb
作成されたフォルダーに images とノートブック neural_style_tutorial.ipynb があります。ノートブックneural_style_tutorial.ipynb の先頭セルに、
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/My Drive/neural_style/
をコピペして下さい。その後、ノートブック全体を実行して下さい。
なお、Google Colab の直下に git clone するコードはこのColab にあります。
以上のどれかの方法で GitHub Repo の git clone すれば、ノートブック neural_style_tutorial.ipynb が利用できます。以下、このノートブックの利用方法について説明します。
style images および content images に使用される original PIL images ピクセルは[0, 255] の値になっていますので、torch tensors に変換する際には [0, 1] に正規化する必要があります。torch library のneural networks は [0, 1] の範囲のテンソルとして学習が行われます。なお、 Caffe library から得た pre-trained networks は [0, 255] のテンソル画像になっています。さらに、画像の次元を同一に揃える必要があります。必要なモジュールを読み込みます。
from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from PIL import Image import matplotlib.pyplot as plt import torchvision.transforms as transforms import torchvision.models as models import copy
このノートブックのデータを読み込むためのセルの以下の部分を修正します。imsize = 512 if torch.cuda.is_available() else 128 をコメントアウトして、imsize=(512,512) を追加します。スタイル画像と入力画像を適宜修正します。
# desired size of the output image
#imsize = 512 if torch.cuda.is_available() else 128 # use small size if no gpu
imsize=(512,512) # 上のラインをコメントにして、ここを追加します
loader = transforms.Compose([
transforms.Resize(imsize), # scale imported image
transforms.ToTensor()]) # transform it into a torch tensor
def image_loader(image_name):
image = Image.open(image_name)
# fake batch dimension required to fit network's input dimensions
image = loader(image).unsqueeze(0)
return image.to(device, torch.float)
style_img = image_loader("./images/gogh_1.jpg") # ここを適宜修正
content_img = image_loader("./images/makiba.jpg") # ここを適宜修正
assert style_img.size() == content_img.size(), \
"we need to import style and content images of the same size"
torch tensors で表現されている画像を PIL format に戻してから、plt.imshow を実行します。
unloader = transforms.ToPILImage() # reconvert into PIL image
plt.ion()
def imshow(tensor, title=None):
image = tensor.cpu().clone() # we clone the tensor to not do changes on it
image = image.squeeze(0) # remove the fake batch dimension
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
imshow(style_img, title='Style Image')
plt.figure()
imshow(content_img, title='Content Image')

牧場の写真 |

ゴッホの絵画 |
Loss function を定義します。
class ContentLoss(nn.Module):
def __init__(self, target,):
super(ContentLoss, self).__init__()
# we 'detach' the target content from the tree used
# to dynamically compute the gradient: this is a stated value,
# not a variable. Otherwise the forward method of the criterion
# will throw an error.
self.target = target.detach()
def forward(self, input):
self.loss = F.mse_loss(input, self.target)
return input
def gram_matrix(input):
a, b, c, d = input.size() # a=batch size(=1)
# b=number of feature maps
# (c,d)=dimensions of a f. map (N=c*d)
features = input.view(a * b, c * d) # resise F_XL into \hat F_XL
G = torch.mm(features, features.t()) # compute the gram product
# we 'normalize' the values of the gram matrix
# by dividing by the number of element in each feature maps.
return G.div(a * b * c * d)
class StyleLoss(nn.Module):
def __init__(self, target_feature):
super(StyleLoss, self).__init__()
self.target = gram_matrix(target_feature).detach()
def forward(self, input):
G = gram_matrix(input)
self.loss = F.mse_loss(G, self.target)
return input
VGG モデルをロードします。
cnn = models.vgg19(pretrained=True).features.to(device).eval()
cnn_normalization_mean = torch.tensor([0.485, 0.456, 0.406]).to(device)
cnn_normalization_std = torch.tensor([0.229, 0.224, 0.225]).to(device)
# create a module to normalize input image so we can easily put it in a
# nn.Sequential
class Normalization(nn.Module):
def __init__(self, mean, std):
super(Normalization, self).__init__()
# .view the mean and std to make them [C x 1 x 1] so that they can
# directly work with image Tensor of shape [B x C x H x W].
# B is batch size. C is number of channels. H is height and W is width.
self.mean = torch.tensor(mean).view(-1, 1, 1)
self.std = torch.tensor(std).view(-1, 1, 1)
def forward(self, img):
# normalize img
return (img - self.mean) / self.std
以下のコードは長いので、説明は省略します。
上記の修正が済んだら、ノートブック全体を実行します。ノートPCで数分程度で結果が出ます。以下のような画像が表示されます。

牧場のゴッホ風スタイルの画像
このようにして、content 用の画像と style 向けの画像を用意すれば、簡単にできます。両方の画像サイズを同一にするところに注意が必要です。
Fast Style Transfer の Tensorflow 実装 |
2016年に、「Neural Algorithm of Artistic Style」で提案されたモデルをより高速に処理できるアルゴリズムが Justin Johnson のグループから提案されました。対応するコードは、この GitHub Repoにありますが、言語は lua です。Python で実装したいので、Python で書かれたコードを使います。Python 実装のコードは「fast-style-transfer」 と名付けられて、 この GitHub Repoにあります。
この GitHub repo のコードは、 Tensorflow 1.xおよびscipy 1.1.0 をサポートしています。なので、Tensorflow 2.0 、scipy 1.1.0 以降のバージョンを使用する時には要注意です。evaluate.py および transform.py に対して Tensorflow 2.0 が使用できるように修正したコードは私の https://github.com/mashyko/fast-style-transfer にあります。この Repo を git clone して使用します。
この Google Colab のノートブックを開いて下さい。このノートブックを実行すると、私の GitHub が git clone されて、/content/にフォルダー fast-style-transfer が作成されます。以下のような構成になっています。
. ├── README.md ├── _gitignore ├── ckpt │ ├── la_muse.ckpt │ ├── rain_princess.ckpt │ ├── scream.ckpt │ ├── udnie.ckpt │ ├── wave.ckpt │ └── wreck.ckpt ├── docs.md ├── evaluate.py ├── examples │ ├── content │ │ ├── chicago.jpg │ │ ├── enoshima_1.jpg │ │ ├── enoshima_2.jpg │ │ ├── fox.mp4 │ │ ├── golden_gate.jpg │ │ ├── minato_mirai.jpg │ │ ├── stata.jpg │ │ └── tubingen.jpg │ ├── results │ │ ├── chicago_la_muse.jpg │ │ ├── chicago_rain_princess.jpg │ │ ├── chicago_the_scream.jpg │ │ ├── chicago_udnie.jpg │ │ ├── chicago_wave.jpg │ │ ├── chicago_wreck.jpg │ │ ├── enoshima_wave.jpg │ │ ├── fox_udnie.gif │ │ ├── stata_udnie.jpg │ │ └── stata_udnie_header.jpg │ ├── style │ │ ├── la_muse.jpg │ │ ├── rain_princess.jpg │ │ ├── the_scream.jpg │ │ ├── the_shipwreck_of_the_minotaur.jpg │ │ ├── udnie.jpg │ │ └── wave.jpg │ └── thumbs │ ├── la_muse.jpg │ ├── rain_princess.jpg │ ├── the_scream.jpg │ ├── the_shipwreck_of_the_minotaur.jpg │ ├── udnie.jpg │ └── wave.jpg ├── fast-style-transfer.ipynb ├── setup.sh ├── src │ ├── __pycache__ │ │ ├── transform.cpython-36.pyc │ │ ├── utils.cpython-36.pyc │ │ └── vgg.cpython-36.pyc │ ├── optimize.py │ ├── transform.py │ ├── utils.py │ └── vgg.py ├── style.py └── transform_video.py
このノートブックでは、evaluate.py を使って画像のスタイル変換を実行します。学習済みモデルは、「--checkpoint ./ckpt/wave.ckpt 」で、入力画像は 「--in-path ./examples/content/enoshima_2.jpg 」、出力先は「--out-path ./examples/results/enoshima_wave.jpg 」で指定しています。それぞれのフォルダーの中に、ここで指定したファイルがあります。なお、出力先の画像は新しく作成されるファイルです。
!python evaluate.py --checkpoint ./ckpt/wave.ckpt --in-path ./examples/content/enoshima_2.jpg --out-path ./examples/results/enoshima_wave.jpg
というコマンドが画像変換を実行するコードです。
上記のノートブックを実行して生成された江ノ島の浮世絵風の画像です。

江ノ島 |

浮世絵風の画像 |
この画像ファイルはフォルダー /results/ の中に保存されます。なお、フォルダー/examples/の中にあるファイルも見て下さい。
動画の画像をスタイル変換するためには、 transform_video.py を使用します。以下のように入力します。ディレクトリ /content/ に fox.mp4 が配置されています。
!mkdir output !python transform_video.py --in-path examples/content/fox.mp4 \ --checkpoint ckpt/wave.ckpt \ --out-path output/fox_wave.mp4 \ --device /gpu:0 \ --batch-size 4
このコマンドを入力すると、ビデオファイル fox_wave.mp4 が生成されます。
好みの動画をアップロードして、好みのスタイルに変換してみて下さい。ただし、利用できるスタイルはディレクトリ /ckpt/ にあるものに限ります。
なお、好みのスタイルを変換するための .ckpt ファイルを作成すために、style.py は以下のように入力して使用します。ゴッホ風へのスタイル変換を学習させています。
学習のためのデータセットとして、train2014 の代わりに、train2017 のなかの val2017 を使用することにします。画像の枚数が5000枚で、サイズが1ギガ以内に収まります。ディレクトリ /data/ に配置します。
!wget http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat !mkdir data !mv imagenet-vgg-verydeep-19.mat data !wget http://images.cocodataset.org/zips/val2017.zip !unzip val2017.zip !mv val2017 data !rm val2017.zip !ls data/
ピカソのスタイルを学習して、結果のファイルを checkpoint に保存します。エポック数2(デフォルト)で数分の時間で処理されます。
!mkdir checkpoint
!python style.py --style examples/style/picasso_1.jpg \
--checkpoint-dir checkpoint \
--train-path train/val2017 \
--test examples/content/enoshima_1.jpg \
--test-dir examples/content \
--content-weight 1.5e1 \
--checkpoint-iterations 1000 \
--batch-size 20 \
--epochs 2\
--vgg-path data/imagenet-vgg-verydeep-19.mat
evaluate.py では、江ノ島の写真をピカソのスタイルに変換するようなコードになっています。
!python evaluate.py --checkpoint checkpoint \
--in-path ./examples/content/enoshima_1.jpg \
--out-path ./examples/results/enoshima_picasso.png
この結果、ピカソ風にスタイル変換された画像が生成されます。

val2017 を用いた学習で生成されたモデルを用いた結果は以上の通りです。学習のエポック数を増加すれば、もう少し鮮明な画像になるかもしれないです。デフォルトで使用することになっている CoCo2014を使用すれば相当に鮮明なスタイル変換ができるでしょうが、Colab ではこの程度でしょう。CoCo2014 データセットのサイズは約13ギガ(8万枚の画像)の大きさなので、Colab で学習するのは無理です。
Fast Style Transfer の Pytorch 実装 |
次に、Pytorch を用いて Fast Style Transfer のコードを実装してみます。 この https://github.com/mashyko/fast_neural_style からコードを git clone します。Github Repo をGoogle Colab で使用するためには、前節の説明と同じように操作します。
このGitHub Repo の構成は以下の通りです。
.
├── README.md
├── download_saved_models.py
├── fast_neural_style.ipynb
├── images
│ ├── content-images
│ │ ├── akadake_1.jpg
│ │ ├── akadake_2.jpg
│ │ ├── amber.jpg
│ │ ├── anzie.jpg
│ │ ├── chicago.jpg
│ │ ├── dancing.jpg
│ │ ├── enoshima_1.jpg
│ │ ├── enoshima_2.jpg
│ │ ├── escher_sphere.jpg
│ │ ├── golden_gate.jpg
│ │ ├── kamakura.JPG
│ │ ├── kiyoharu.jpg
│ │ ├── makiba.jpg
│ │ ├── minato_mirai.jpg
│ │ ├── seisenryo.jpg
│ │ └── tubingen.jpg
│ ├── output-images
│ │ ├── amber-candy.jpg
│ │ ├── amber-mosaic.jpg
│ │ ├── amber-rain-princess.jpg
│ │ ├── amber-udnie.jpg
│ │ ├── minato_mirai.jpg
│ │ └── test.jpg
│ ├── style-images
│ │ ├── candy.jpg
│ │ ├── gogh.jpg
│ │ ├── gogh_2.jpg
│ │ ├── gogh_3.jpg
│ │ ├── matisse.jpg
│ │ ├── mosaic.jpg
│ │ ├── picasso.jpg
│ │ ├── picasso_2.jpg
│ │ ├── picasso_3.jpg
│ │ ├── picasso_4.jpg
│ │ ├── rain-princess-cropped.jpg
│ │ ├── rain-princess.jpg
│ │ ├── starry_night.jpg
│ │ ├── the_scream.jpg
│ │ ├── udnie.jpg
│ │ ├── wave.jpg
│ │ └── wave_crop.jpg
│ └── train-images
│ ├── 2014-08-01\ 17_41_55.jpg
│ ├── 2014-08-01\ 22_38_22.jpg
│ ├── 2014-08-02\ 00_36_32.jpg
│ ├── 2014-08-02\ 11_46_
| .....(150枚の学習用画像)
|
├── neural_style
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── transformer_net.cpython-37.pyc
│ │ ├── utils.cpython-37.pyc
│ │ └── vgg.cpython-37.pyc
│ ├── neural_style.py
│ ├── transformer_net.py
│ ├── utils.py
│ └── vgg.py
├── saved_models
│ ├── candy.pth
│ ├── mosaic.pth
│ ├── rain_princess.pth
│ └── udnie.pth
└── style_train (学習用のスタイル画像)
├── gogh.jpg
└── picasso.jpg
GitHub Repo を Google Colab で git clone します。この Colab にアクセスします。この Colab のノートブックの説明をします。以下のセルのコマンドを実行します。
!git clone https://github.com/mashyko/fast_neural_style
import os
os.chdir('fast_neural_style')
pretrained model を用いて画像のスタイル変換をします。
!python neural_style/neural_style.py eval \ --content-image images/content-images/minato_mirai.jpg \ --model saved_models/udnie.pth \ --output-image images/output-images/minato_udnie.jpg \ --cuda 1 # set 1 if cuda is available
すると、みなとみらいの観覧車コスモクロックの写真を以下のように変換した画像が生成されます。出力されたフォルダーは images/output-images/minato_udnie.jpg です。
以下のコード利用して、画像を表示します
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
in_img=mpimg.imread('images/content-images/minato_mirai.jpg')
out_img=mpimg.imread('images/output-images/minato_mirai.udnie') #image to array
plt.figure()
plt.imshow(in_img)
plt.title('input image')
plt.figure()
plt.imshow(out_img) #array to 2Dfigure
plt.title('output image')
plt.show()

みなとみらい |

udnie 風の画像 |
Python ファイル neural_style.py (eval) のオプションは以下の通りです。
*Flags** - `--checkpoint`: Directory or `ckpt` file to load checkpoint from. Required. - `--in-path`: Path of image or directory of images to transform. Required. - `--out-path`: Out path of transformed image or out directory to put transformed images from in directory (if `in_path` is a directory). Required. - `--device`: Device used to transform image. Default: `/cpu:0`. - `--batch-size`: Batch size used to evaluate images. In particular meant for directory transformations. Default: `4`. - `--allow-different-dimensions`: Allow different image dimensions. Default: not enabled
こうして、画像のスタイルを変換することは簡単です。GPU を使用せず、CPU だけでも時間はそれほどかかりません。各スタイルの学習済みモデルが必要ですが、デフォルトでは4種類だけ用意されています。
ゴッホやピカソなどの各スタイルの学習済みモデルを作成するための手続きについて説明します。学習のための画像のデータセットを用意します。以下の例では、ディレクトリ/images/の中に /train-images/ というフォルダーの中に配置しています。150枚の画像が用意されています。style-image のための画像は、例えば、ディレクター style_train を作成して、その中に配置しています。この準備ができたら、ゴッホ風の画像への変換モデルを学習させる時は、以下のように入力します。
学習用の画像データセットとして、train2017 のなかの val2017 を使用することにします。画像の枚数が5000枚で、サイズが1ギガ以内に収まります。前節と同じく、ディレクトリ /data/ を作成して、この中に val2017 を配置します。
!python neural_style/neural_style.py train --dataset data/ \
--style-image style_train/gogh.jpg \
--save-model-dir save-models/gogh.pth --epochs 10 --cuda 1
このセルを実行すると、
Done, trained model saved at save-models/gogh.pth/epoch_50_Sat_Apr__4_13:49:59_2020_100000.0_10000000000.0.model
と結果が出ます。このデータセットを使用時には、10 epoch で学習時間は1時間30分以上かかります。保存されたファイル名をコピペして、以下のセルを実行します
!python neural_style/neural_style.py eval \ --content-image images/content-images/makiba.jpg \ --model save-models/gogh.pth/epoch_50_Sat_Apr__4_13:49:59_2020_100000.0_10000000000.0.model \ --output-image images/output-images/makiba_gogh.jpg \ --cuda 1 # set 1 if cuda is available
この結果、Gogh 風にスタイル変換された画像が生成されます。

学習用のデータセットの枚数が少ないので、この程度かなと思います。デフォルトでは、学習に使用されるデータセットはCoCo データ train2014 となっていて、そのサイズは約13Gの大きさがあります。GPU で実行しても数時間かかります。Google Colab では学習は難しいので、それ以外の手段を使用する必要があります。
Tensorflow でコード化された fast-style-transfer と Pytorch で書かれた fast_neural_style の間で、学習済みモデルを共通して使用できません。別々の学習済みモデルが必要です。また、「style transfer」のコードに比較して、スタイル変換の処理時間は速いのですが、学習のための操作が煩雑で、長時間かかります。それぞれ、一長一短です。