
左がJetson Nano Developer Kit B01 、右が Raspberry Pi 3 (Model B): Allanさんから引用
|
シングルボードコンピュータの代表的な製品は Rapberry Pi と Jetson Nano の2種類です。Jetson nanoはアメリカの半導体メーカーであるNVIDIA社が製造・販売をするシングルボードコンピューターです。このページでは、NVIDIAが提供している Jetson Nano Developer Kit B01 の使用法について説明します。
左がJetson Nano Developer Kit B01 、右が Raspberry Pi 3 (Model B): Allanさんから引用
Jetson Nanoは、Tegra X1のSoCに4GBのメモリを搭載したコンピューティングモジュールで、ピーク性能は472GFLOPS を実現しています。Maxwell世代のGPUを内蔵しているため、CUDAを使った推論を利用して、画像認識などの機能を実装できます。Jetson Nano自体は多種類のインターフェイス機器を内蔵していませんが、開発キットと呼ばれる追加の機能を持つベース基板に接続されています。この開発キットにはJetson Nanoのモジュールそのものと、I/Oを内蔵した基板が組み合わさって提供されており、Jetson Nano単体では用意できない各種I/O(USBやHDMIなど)や電源回路が搭載されています。
バース基板にはRealTekのEthernetコントローラとM.2のスロットが搭載されている。ベース基板にはほかにも40ピンの拡張用ヘッダー、MIPI CSI カメラコネクタが用意されています。背面のポートにはUSB 3.0×4、Gigabit Ethernet、HDMIとDisplayPortのディスプレイ出力、スマートフォン用の5V/2AのUSB ACアダプタを接続できるMicro USB形状のDC入力が用意されています。また、5V入力のDC入力も用意されており、5Vを出力する丸形のACアダプタを接続して利用することもできる。
「NVIDIA® Jetson Nano™ を利用すれば、電力効率に優れたさまざまな小型 AI システムに驚異的な新機能を導入することができます。エントリレベルのネットワーク ビデオ レコーダー (NVR)、ホーム ロボット、分析機能をフルに搭載したインテリジェント ゲートウェイなど、組み込み IoT アプリケーションの新しい世界を開きます。Jetson Nano は、すぐに試せるプロジェクトと活発で情熱的な開発者コミュニティのサポートを活用して、現実社会の環境で AI とロボティクスについての学習を開始できる最適なツールでもあります。」と謳われています。
Jetson Nano は、最新の画像分類、物体検出、セグメンテーション、音声処理などのアプリケーションを小型サイズ、低電力、低コストで実現可能になっています。使用する OS (JetPack)には機械学習ライブラリのPyTorchやTensorFlow、プログラム実行環境のJupyter Lab等が容易にインストールできます。ただ、Raspberry PI と異なり、無線LAN接続の機器が内蔵されていませんので、無線LANを使用するときはそのためのアダプターが必要です。
Jetson Nano開発者キットの仕様は以下の通りです。
別途用意が必要なものは
microSDカード(64 GB UHS-1以上)このページでは、PCとして Mac を使用した手順を説明しています。
Jetson Nanoの最大の弱点は、リモートPCからssh接続中に、Host Downという表示が出て、ssh接続が切断されることです。この場合、Jetson Nano本体は稼働していますが、ssh接続ができません。ssh接続をするためには、Jetson Nanoを再稼働する必要があります。
Last updated: 2022.1.20
Jetson Nano へのJetPack OS のインストールと起動 |
Jetson Nano へのOSのインストールと起動の手順について、公式サイトに沿って説明します。 Jetson Nano の OS、JetPackをダウンロードし、開発用のPCからmicroSDへ書き込みます。JetPackはJetson用のLinuxであるL4TをベースとしてCUDAドライバなどのソフトウェアをまとめたものです。最新バージョンはJetPack 4.6 で、Ubuntu 18.04LTS を基礎としたものです。最初に、JetPack の圧縮ファイル(jetson-nano-jp46-sd-card-image.zip)を NVIDIAの公式サイトからダウンロードします。7GB程度の圧縮ファイルです。これを解凍すると、sd-blob-b01.img が作成されます。約14GBのイメージファイルです。
イメージファイルを microSD カードに書き込むために、balenaEtcherを使用します。
$ diskutil list
と入力すると、micro SD のデバイス名がわかります。多分、/dev/disk2/ となっていると思います。balenaEtcher を起動して、Flash from file で sd-blob-b01.img ファイルを選択し、select target を microSD名(/dev/disk2/) にして、書き込み(Flash)します。書き込みが終わったら、 microSD カードを取り出します。「接続したディスクは、このコンピュータで読み取れないディスクでした」という警告が出ますが無視します。
microSD カードを用いて、以下の手順でJetson Nano へのインストールをおこないます。
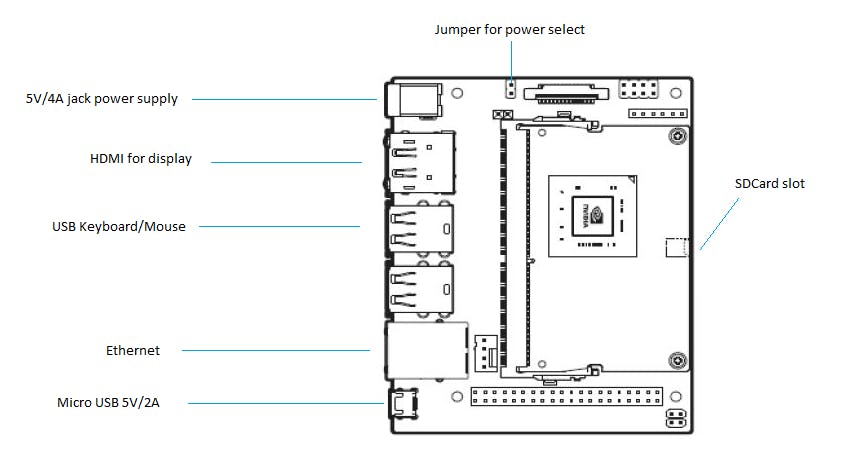
Jetson Nanoに電源を入れると、最初にインストールのためのデスクトップ画面が表示されます。無線LANアダプタはTP-Link社のTL-WN725Nを用いました。ライセンス確認の画面が表示されるので、Continueを押します。言語選択(system cofiguration)の画面で言語を日本語に、キーボード選択で日本語、地域でTokyoを選択します。WiFiネットワークの選択画面が出るので使用しているWiFi を選択、タイムゾーン選択画面が出るので、Tokyoを選択します。次に、ユーザー名、パスワードなどの設定をします。次の画面で、APP partition size はデフォルトのサイズ(最大値)で良いと思います。スワップ領域とはPyTorch等でAIのモデルを読み込む際に、メモリの不足分を補うための領域です。基本的にはデフォルトの「作成する(Create SWAP File)」を選びます。初期設定に使った余分な領域を削除するかの確認が出ますが、基本的には「続ける(continue)」を押して先に進みます。節電設定の選択はデフォルトで良いと思います。
PCを headless mode で用いてインストールの手続きをするケースについては、「Setup and First Boot」ページの「Initial Setup Headless Mode」の項を参照ください。Jetson Nanoには電源供給ポートが2つあります。1つはMicroUSBポートによるUSBからの給電、もう一つはACアダプタを利用したDCジャックからの給電です。headless mode の手順ではDCジャックからの給電を想定した手順になっています。なお、DCジャックから給電するためにはDCジャック後方にある「J48」と書かれているジャンパーを再差し込みする必要があります。「Jumper the J48 Power Select Header pins」の意味は、jumper for power select の箇所で、1つのピンに挿してあるジャンパーを抜いて、二つのピンが接続するようにジャンパーを差し込むことです。こうすると、DC電源の端子をBarrel jackに接続すると、電源が供給されて、microUSB端子にPCのUSBから接続できます。このケースでは、マウスやキーボードはPCが担います。
JetPack のデスクトップ画面
インストールが完了したら、デスクトップ画面が表示されます。ログインして、ターミナル(LXTerminal)をクリックして
$ sudo apt update $ sudo apt upgrade
とパッケージをアップデートします。JetPackには、デフォルトのエディタとしてvimが入っていますが、 vimの扱いは初心者には煩雑ですので、nanoをインストールします。
$ sudo apt install nano
IPアドレスを知るために、ターミナルから
$ ifconfig
と打ちます。このIPアドレスの番号を記録してください。
リモート PC から ssh 接続をします。Jetson Nano に設定したユーザー名とIPアドレスを使って、PCのターミナルから
$ ssh ユーザー名@192.168.**.**
と入力します。パスワードを入力すれば、以下のように表示されて、ログインできます。
jetson login: koichi Password: Last login: Fri Jan 21 11:38:58 JST 2022 on ttyGS0 Welcome to Ubuntu 18.04.5 LTS (GNU/Linux 4.9.253-tegra aarch64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage This system has been minimized by removing packages and content that are not required on a system that users do not log into. To restore this content, you can run the 'unminimize' command. koichi@jetson:~$
これ以降、リモートPCから ssh 接続で Jetson Nano を操作することができます。デスクトップ画面にはアクセスできません。
リモートPCから Jetson Nano のデスクトップ画面にアクセスするためには、 NVC-Server を設定する必要があります。Jetson Nano への NVC-server 設定の方法については、日本語解説のサイト、及び、英語での解説を参照ください。
最初に、Vino をインストールします。
$ sudo apt update $ sudo apt upgrade $ sudo apt install vino
次に、Vino.gschema.xml ファイルを開いて、修正します。
$ sudo nano /usr/share/glib-2.0/schemas/org.gnome.Vino.gschema.xml
nano エディタを用いて下記のコードを追加します。
<key name='enabled' type='b'>
<summary>Enable remote access to the desktop</summary>
<description>
If true, allows remote access to the desktop via the RFB
protocol. Users on remote machines may then connect to the
desktop using a VNC viewer.
</description>
<default>false</default>
</key>>
次に、以下のコマンドを入力して、コンパイルします。
$ sudo glib-compile-schemas /usr/share/glib-2.0/schemas
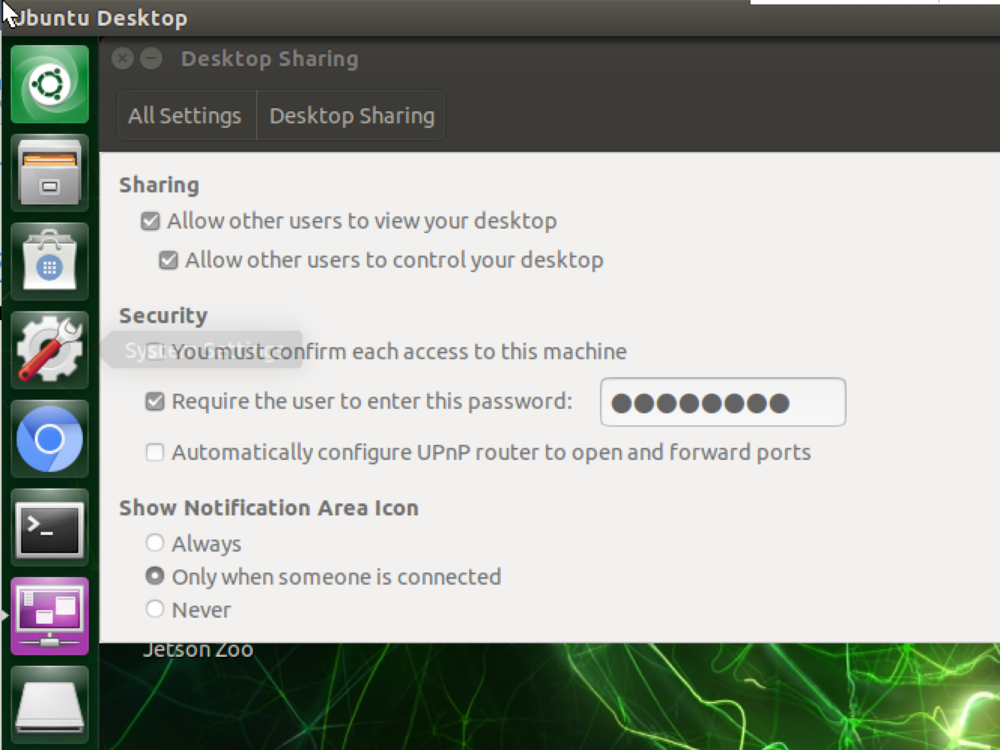
jetson のデスクトップ画面で メニューの「setting」 をクリックして、「デスクトップの共有(desktop sharing)」を開いて、以下のように修正します。
続いて,起動時にリモートアクセスできるように,[自動起動するアプリケーションの設定(startup applications)]をひらき,[追加(add)]で以下の画像のように vino-server を追加して,「save」して閉じます。
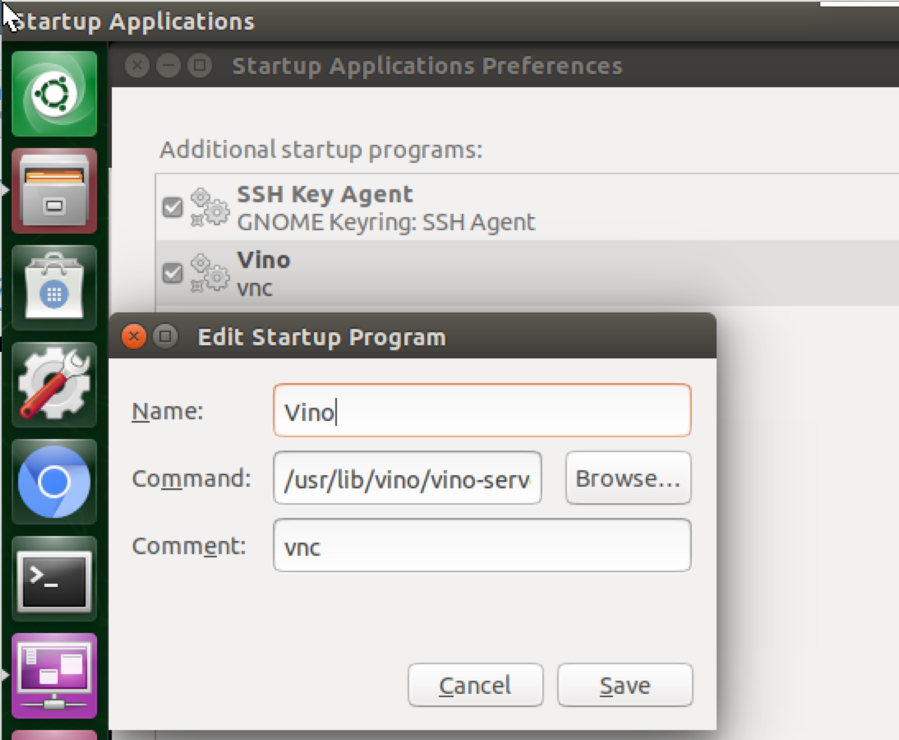
command には /usr/lib/vino/vino-server と記述します。「startup applications」はメニューの左上のUbuntuのロゴをクリックして、「startup applications」と検索すると表示できます。
最後に
$ sudo gsettings set org.gnome.Vino prompt-enabled false $ sudo gsettings set org.gnome.Vino require-encryption false
とコマンドを実行すると,リモートPCからVNCを用いてJetsonのデスクトップ画面にアクセスできるようになります。使用するPCには、例えば、RealVNC Viewer をインストールします。
PCの VNCViewer を起動すると、デスクトップにVNCviewerのウインドウが開きます。PCのデスクトップに表示されるポップアップ画面内で、「File」- 「New connection」と行って、VNC Server 欄にJetson NanoのIPアドレスを記入し、名称を入力します。次に進むと、パスワードを入力する画面がポップアップしますので、Jetson Nanoのログインパスワードを入力すると、Jetson Nanoのデスクトップが表示されます。
ただし、Jetson Nano を起動したときにデスクトップ画面でログインしないと Vino-Server へのアクセスが拒否されます。また、Vino-Server を介した Jetson Nano のデスクトップ画面の動作が非常に遅いので、快適な利用はできないと思います。Jetson Nano のファイルなどにアクセスして利用するケースでは、ファイル共有ソフトなど他の手段を用いた方がベターだと思われます。
VNC に代替するもっと簡単な方法は xrdp と呼ばれる RDP server を利用することです。以下のコマンドで xrdp をインストールします。
$ sudo apt-get install xrdp
このインストールが完了したのち、Jetson Nano を reboot します。再起動した後、リモートPCから接続して
$ sudo apt install nmap $ nmap jetson
と実行して、 xrdp が正常に作動していることを確認します。以下のような表示が出たら成功です。
Starting Nmap 7.70 ( https://nmap.org ) at 2019-04-13 01:39 BST Nmap scan report for jetson (192.168.1.118) Host is up (0.0025s latency). Not shown: 996 closed ports PORT STATE SERVICE 22/tcp open ssh 111/tcp open rpcbind 3389/tcp open ms-wbt-server Nmap done: 1 IP address (1 host up) scanned in 1.25 seconds
Jetson Nano のコンソールからログインしていないので、VNC server は作動しませんが、 RDP は作動しています。
Microsoft がこのRDPに対応した viewer を無料ソフト「Microsoft Remote desktop」を提供しています。 Mac App Storeでダウンロードして、インストールします。 「Microsoft Remote Desktop」を起動して、「+」-「Add PC」をクリックします。「PC name」 に Jetson Nano のIPアドレスを入力して、「Group」にJetson と記述して、「Save」して続けます。その後、パスワードの記入を3回程度求められますが、続けていくと、Jetson Nano のデスクトップ画面が表示されます。この画面は、一般的なUbuntu desktopの表示になっています。
Jetson Nano と Mac の間でファイル共有 |
Jetson Nano のデスクトップ画面をVNC Viewer で操作することを極力少なくしたいとき、 Jetson Nano とPCの間でファイル共有をした方が便利です。SSHで Jetson Nano とPCの間でファイル共有を可能にするためには、mac OS の場合には若干手数がかかります。FUSE for macOSというソフトをインストールする必要があります。
FUSE for macOSのページから、「FUSE for macOS」および「SSHFS」をダウンロードします。前者がMacで標準対応していないファイルシステムを扱う枠組みを提供し、後者が実際にSSHをつかってファイルをやり取りするためのソフトです。
FUSE for macOSのインストールでは、サードパーティー製のソフトなので、個別に許可する必要があります。FUSE for macOS をインストールする最後に、このソフトに対するアプリケーション実行の許可を認証する要求が表示されます。「セキュリティ環境設定を開く」をクリックし、ダウンロードしたアプリケーション実行の「許可」をクリックします。これをしないとインストールできません。
次に、ダウンロードしたSSHFSをインストールします。pkgファイルを開くとインストーラーが起動します。使用許諾に同意する場合は「同意する」をクリックして進めます。
最後に、 Jetson Nano のディレクトリを参照できるようにします。ソフトの環境が整ったので、 Jetson Nano のディレクトリをMac上のFinderやターミナルから見られるようにしてみましょう。まず Jetson Nano のディレクトリをマウントする場所を用意しておく必要があります。ホームに「macfuse」という名前のディレクトリを作成します。マウントするには、ターミナルから以下の形式のコマンドを実行します。 Jetson Nano のユーザー名とIPアドレスを使用します。
$ sshfs koichi@192.168.**.**:/home/koichi ~/jetsonfuse
finderを開くと、ユーザーのホームに「macFUSE Volume 0 (sshfs)」というディレクトリが作成されています。
マウントを解除するには、umountコマンドを使用します。
$ umount jetsonfuse
Jetson-Inference パッケージを用いて物体検出の実行 |
まず最初にすることは cmake と git をインストールすることです。
$ sudo apt-get install cmake $ sudo apt-get install git
Jetson Nano で機械学習及びディープラーニングを始めるために、このHello AI World サイト(Jetson-Inference)の説明に沿って始めます。
このHello AI World は、NVIDIA TensorRTを用いて、Jetsonプラットフォームにニューラルネットワークを組み込んで、ディープラーニングを効率的に実行できる環境を用意しています。具体的には、画像認識用のimageNet、オブジェクト検出用のdetectNet、セマンティックセグメンテーション用のsegNet、及び、ポーズ推定用のposeNetなどのコンピュータビジョンのためのモジュールを提供しています。ライブカメラからのストリーミングや画像処理の例が提供されています。 C++およびPythonの詳細なライブラリは以下の通りです。
| library | C++ | Python |
| Image Recognition | imageNet.cpp | imageNet.py |
| Object Detection | detectNet.cpp | detectNet.py |
| Segmentation | segNet.cpp | segNet.py |
| Pose Estimation | poseNet.cpp | poseNet.py |
| Monocular Depth | depthNet.cpp | depthNet.py |
Image Recognition で利用できる学習済みモデルは、
AlexNet
GoogleNet
GoogleNet-12
ResNet-18
ResNet-50
ResNet-101
ResNet-152
VGG-16
VGG-19
Inception-v4
となっています。また、Object Detection で利用できるモデルは
SSD-Mobilenet-v1
SSD-Mobilenet-v2
SSD-Inception-v2
DetectNet-COCO-Dog
DetectNet-COCO-Bottle
DetectNet-COCO-Chair
DetectNet-COCO-Airplane
ped-100
multiped-500
facenet-120
の中から選択できます。
これらのモデルのどれを使用するかは、「--network=googlenet」のようなオプションで指定します。
これらのライブラリを利用するために、GitHub repo をダウンロードします。 Docker container を使用しない方法で行います。
$ git clone https://github.com/dusty-nv/jetson-inference $ cd jetson-inference $ git submodule update --init
ソースコードをビルドします。
$ mkdir build $ cd build $ cmake ../ $ make $ sudo make install
と打って、ビルドを実行します。学習済みの各種モデルとPytorchのインストールが行われます。make コマンド実行で少々時間がかかります。jetson-inference/build の中に必要最小限の sh ファイル等がインストールされます。build ディレクトリは以下の構造となります。
CMakeCache.txt cmake_install.cmake examples python CMakeFiles docs install-pytorch.rc tools Makefile download-models.rc install-pytorch.sh utils aarch64 download-models.sh install_manifest.tx
この jetson-inference プロジェクトは jetson-inference/build/aarch64 にビルドされて、以下のファイル構造となります。
|-build
\aarch64
\bin where the sample binaries are built to
\networks where the network models are stored
\images where the test images are stored
\include where the headers reside
\lib where the libraries are build to
Python 3.6 に対するバインディングを作成するためには、以下のパッケージをインストールする必要があります。
$ sudo apt-get install libpython3-dev python3-numpy
jetson-inference/build/aarch64/bin の images ディレクトリにある画像を利用して画像識別及び物体検出をしてみましょう。リモートPCから ssh 接続で行います。
最初に、フルーツの種類を識別する実験をしましょう。imagenet また imagenet-console を使用します。
$ cd ~/jetson-inference/build/aarch64/bin $ ./imagenet images/fruit_0.jpg fruit_out.jpg
初回ではネットワークを最適化する処理のために、少々時間がかかります。以下の結果が得られます。
[image] loaded 'images/fruit_0.jpg' (688x1024, 3 channels) class 0950 - 0.928711 (orange) class 0951 - 0.023438 (lemon) class 0989 - 0.044830 (hip, rose hip, rosehip) imagenet: 92.87109% class #950 (orange) [image] saved 'fruit_out.jpg' (688x1024, 3 channels)

物体識別の結果画像
画像にある植物は確率92%でオレンジという結果になります。ネットワークの指定をしないときは、デフォルトで、 GoogleNet または ResNet-18 が読み込まれます。ネットワークを指定するときは、以下のようにします。
# network を指定するとき $ ./imagenet --network=googlenet images/orange_0.jpg output_0.jpg # --network flag is optional
imagenet の利用方法については、GitHub の説明を参照ください。
リモートPCから ssh 接続で、以下の例も C++ コードで実行してます。
$ cd ~/jetson-inference/build/aarch64/bin $ ./imagenet images/orange_0.jpg images/test/output_0.jpg 結果 [image] loaded 'images/orange_0.jpg' (1024x683, 3 channels) class 0950 - 0.966309 (orange) imagenet: 96.63086% class #950 (orange) [image] saved 'images/test/orange_output_0.jpg' (1024x683, 3 channels)
次に、物体検出を実行してみましょう。detectnet または detectnet-console を使います。
$ cd ~/jetson-inference/build/aarch64/bin $ ./detectnet images/dog_0.jpg out.jpg coco-dog
初回ではネットワークを最適化する処理のために、少々時間がかかります。以下の結果が得られます。
[image] loaded 'images/dog_0.jpg' (500x375, 3 channels) 2 objects detected detected obj 0 class #1 (person) confidence=0.980469 bounding box 0 (0.000000, 50.445557) (229.370117, 353.027344) w=229.370117 h=302.581787 detected obj 1 class #18 (dog) confidence=0.835449 bounding box 1 (211.669922, 84.869385) (431.884766, 364.013672) w=220.214844 h=279.144287 [image] saved 'out.jpg' (500x375, 3 channels)

物体検出の結果画像
dog_0.jpg には人物と犬が写っていることが検出されています。detectnet の説明はこのdocsを参照ください。ネットワークを指定しないときは、デフォルトで、 SSD-Mobilenet-v2 が読み込まれます。 以下のように detectnet コマンドで、ネットワークを指定することもできます。
$ cd ~/jetson-inference/build/aarch64/bin $ ./detectnet --network=ssd-mobilenet-v2 images/peds_0.jpg images/test/output.jpg 結果 [image] loaded 'images/peds_0.jpg' (1920x1080, 3 channels) 4 objects detected detected obj 0 class #1 (person) confidence=0.984375 bounding box 0 (1074.375000, 109.160156) (1396.875000, 1002.480469) w=322.500000 h=893.320312 detected obj 1 class #1 (person) confidence=0.697266 bounding box 1 (458.671875, 123.398438) (742.500000, 942.890625) w=283.828125 h=819.492188 detected obj 2 class #1 (person) confidence=0.976074 bounding box 2 (742.031250, 160.576172) (1021.875000, 941.835938) w=279.843750 h=781.259766 detected obj 3 class #1 (person) confidence=0.860840 bounding box 3 (1477.500000, 149.238281) (1721.250000, 914.941406) w=243.750000 h=765.703125 [image] saved 'images/test/output.jpg' (1920x1080, 3 channels)

物体検出に使用された歩行者の画像
ここまでは、C++ のコードで実行していますが、Python スクリプトを用いて実行するときは、
$ python3 detectnet.py images/peds_0.jpg images/test/output.jpg
という形式でコマンドを使います。「[OpenGL] failed to open X11 server connection. [OpenGL] failed to create X11 Window.」という警告が出ます。
最後に、/usr/share/visionworks/sources/data にあるビデオファイルから物体検出をすることを見てみましょう。手持ちのWebcamera をUSB端子に、あるいは、Raspberry Pi 用のカメラモジュールV2を接続してください。jetson-inference-camera streamingに解説があります。歩行者を撮影した動画を用いて、以下のようなコマンドを打ちます。
$ ./detectnet /usr/share/visionworks/sources/data/pedestrians.mp4 images/test/pedestrians_ssd.mp4
images/test/pedestrians_ssd.mp4 のビデオファイルに検出の結果が記憶されます。
以上までの操作は ssh 接続したリモートPCからの操作でした。カメラからのリアルタイム映像を Jetson Nano のディスプレイに表示させるためには、Jetson のデスクトップ画面のターミナルから操作する必要があります。ssh 接続のターミナルからはできません。Vino-server を利用した(リモートPC上の)Jetson デスクトップ画面からは可能です。
接続されているカメラの情報を取得するためにv4l-utilsをインストールします。利用できるWebカメラの一覧を取得します。
$ sudo apt install v4l-utils $ v4l2-ctl --list-devices
webcamera からのリアルタイム映像の detectnet を用いた物体識別は以下のようにできます。USB webcam は V4L2 devices によってサポートされています。なので、(カメラ)入力を v4l2:///dev/video0 と指定します。省略形で、/dev/video0 と指定することもできます。
$ ./detectnet /dev/video2 # imagenet を使用するときは、./imagenet /dev/video0
物体識別の結果映像がJetson のデスクトップ画面にリアルタイムで表示されます。
Jetson Nano が内蔵するカメラモジュール(Raspberry Pi Camera Module v2)を使用するときは、MIPI CSI カメラをカメラモジュールに接続して、
$ ./detectnet csi://0 # imagenet を使用するときは、./imagenet csi://0
とします。「[gstreamer] gstDecoder -- failed to retrieve next image buffer video-viewer: failed to capture video frame」というエラーが出流可能性があります。どういうわけか、Pytorch、Tensorflow, ROSなどのインストール後は正常に作動します。「esc」キーで終了します。
Jetson Nano のカメラがとらえたリアルタイム映像をストリーミング映像として配信して、それをリモートPCで受信する方法を取り上げます。映像のストリーミング配信の方法について説明します。このgithub.com/dusty-nv/jetson-inferenceサイトに説明があります。Jetson Nano から Gstreamer を用いた映像のストリーミングは以下のようにします。
利用するカメラは Raspberry Pi Camera または usb-Webcamera の2種類を想定します。Raspberry Pi Camera は MIPI CSI cameras に分類されます。webcameraはV4L2 cameras に分類されます。MIPI CSI cameraの利用するprotocol は csi://になり、V4L2 camera の利用するprotocolは v4l2://なります。したがって、入力のデバイス指定はそれぞれ csi://0 、[v4l2://]/dev/video0 のようになります。
出力は RTP protocol で配信します。RTP ネットワークストリーミングは UDP/IP 上でホスト機器に配信されます。UDP/IP は TCP/IPと異なる配信方式です。rtp://{remote-ip}:1234形式で配信先を指定します。したがって、csi カメラを使用するときは、リモートPCのIPアドレスが 192.168.10.10 のとき
$ cd jetson-inference/build/aarch64/bin $ video-viewer --input-flip=rotate-180 csi://0 rtp://192.168.10.10:1234
と入力します。csi カメラの時、オプション--input-flip=rotate-180が指定されていないと、映像が上下に反転しています。「[gstreamer] gstDecoder -- failed to retrieve next image buffer video-viewer: failed to capture video frame」というエラーが出ま可能性があります。どういうわけか、ROSのインストール後は正常に作動します。「Ctrl+c」キーで終了します。
デフォルトではストリーミングされた映像が上下に反転しているので、 --input-flip=rotate-180 というオプションで反転を直しています。usbに接続されたWeb cameraのケースでは必要ありませんので、以下のようになります。カメラモジュールを1個使用しているときは、/dev/video1と設定します。カメラモジュールを2個使用しているときは、/dev/video2と設定します。カメラモジュールにカメラが接続されているときは、/dev/video0 の設定は間違いです。
$ video-viewer /dev/video2 rtp://192.168.10.10:1234
Input Options と Output Options の詳細についてはgithub.com/dusty-nv/jetson-inferenceの解説を参照ください。
Jetson Nano からの映像のストリーミングをリモートPCから受信する方法について説明します。GStreamer または VLC player を用いた方法があります。ここでは、VLC Playerを用いた映像の表示を取り上げます。各プラットフォームに対応したVLC Player を公式ページからダウンロードします。表示された手順に従ってインストールします。
適当なディレクトリに以下の内容の SDP file (.sdp)を作成します。jetson.sdp と名前をつけて保存します。
v=0 c=IN IP4 192.168.10.10 m=video 1234 RTP/AVP 96 a=rtpmap:96 H264/90000
VLC player
VLC プレイヤーを起動して、再生リストにjetson.sdp が表示されたら、再生のボタンをクリックする手順となります。実際には、Jetson Nano でストリーミングを開始したら、再生のボタンをクリックします。ストリーミングされた映像が再生されます。映像が再生されたら成功です。
ライブ映像の物体識別及び物体検出を行うことを考えます。Web camera を使用するケースでは以下のようになります。
$ ./detectnet /dev/video2 rtp://192.168.10.10:1234 $ ./imagenet /dev/video2 rtp://192.168.10.10:1234
csi カメラを用いるケースでは、
$ cd ~/jetson-inference/build/aarch64/bin $ ./detectnet --input-flip=rotate-180 csi://0 rtp://192.168.10.10:1234 $ ./imagenet --input-flip=rotate-180 csi://0 rtp://192.168.10.10:1234
とします。動画がストリーミングされますので、リモートPCのVLCで受信します。
GPUを使用しているので、検出スピードは速いです。当然ながら、映像の精度は、csi カメラよりも webcam の方が格段に良いです。
Jetson-Inferenceパッケージを用いた物体セグメンテーションの実行 |
Semantic Segmentation 及び Pose Estimation で利用できるモデルの使用方法を説明します。 そのためには、学習済みモデルをダウンロードする必要があります。利用可能なモデルとデータセットについては、Pre-Trained Segmentation Modelsを参照ください。 以下のコマンドを用いて適宜ダウンロードします。
$ cd jetson-inference/tools $ ./download-models.sh
Pythonで物体のセグメンテーションを実行するためには、以下のような形式でコマンドを入力します。
# C++
$ ./segnet --network={model} input.jpg output.jpg # overlay segmentation on original
$ ./segnet --network={model} --alpha=200 input.jpg output.jpg # make the overlay less opaque
$ ./segnet --network={model} --visualize=mask input.jpg output.jpg # output the solid segmentation mask
# Python
$ python segnet.py --network={model} input.jpg output.jpg # overlay segmentation on original
$ python segnet.py --network={model} --alpha=200 input.jpg output.jpg # make the overlay less opaque
$ python segnet.py --network={model} --visualize=mask input.jpg output.jpg # output the segmentation mask
cityscapes-datasetと呼ばれる都市部の道路交通の動画を集積したデータセットがあります。 これは、50の異なる都市のストリートシーンで記録されたビデオ動画の多様なセットを含む新しい大規模データセットです。高品質のピクセルレベルでのラベル注釈付きの5000フレームの動画と、荒いラベル付きの約20000フレームの動画の大きなセットがあります。 the Cityscapes modelを用いたurban street sceneのセグメンティングの場合、以下のコマンドを使用します。
$ cd ~/jetson-inference/build/aarch64/bin # C++ $ ./segnet --network=fcn-resnet18-cityscapes images/city_0.jpg images/test/output.jpg # Python $ python segnet.py --network=fcn-resnet18-cityscapes images/city_0.jpg images/test/output.jpg

SegNetによるセグメンテーションの例
DeepSceneデータセットは、オフロードの森林歩道と植生で構成されており、屋外ロボットの経路追跡などの利用で役立ちます。引数「--visualize」を指定して、セグメンテーションオーバーレイとマスクを生成する例を次に示します。学習済みモデル「fcn-resnet18-deepscene」が必要です。
# C++ $ ./segnet --network=fcn-resnet18-deepscene images/trail_0.jpg images/test/output_overlay.jpg # overlay $ ./segnet --network=fcn-resnet18-deepscene --visualize=mask images/trail_0.jpg images/test/output_mask.jpg # mask # Python $ python segnet.py --network=fcn-resnet18-deepscene images/trail_0.jpg images/test/output_overlay.jpg # overlay $ python segnet.py --network=fcn-resnet18-deepscene --visualize=mask images/trail_0.jpg images/test/output_mask.jpg # mask
また、サンプルスクリプト「segnet.cpp / segnet.py」はリアルタイムでのカメラ映像を入力動画として実行することもできます。物体検出の節で説明したように、MIPI CSI cameras (csi://0)、 V4L2 cameras (/dev/video0)、および、RTP/RTSP streams (rtsp://username:password@ip:port)という3種類の入力をサポートします。以下の形式でコマンドを実行します。
# C++
$ ./segnet --network={model} csi://0 # MIPI CSI camera
$ ./segnet --network={model} /dev/video2 # V4L2 camera
$ ./segnet --network={model} /dev/video2 output.mp4 # save to video file
# Python
$ python segnet.py --network={model} csi://0 # MIPI CSI camera
$ python segnet.py --network={model} /dev/video2 # V4L2 camera
$ python segnet.py --network={model} /dev/video2 output.mp4 # save to video file
具体的には、例えば、以下のコマンドを使用します。ネットワークモデルは上のセグメンテーションで用いたモデルです。
# C++ $ ./segnet --network=fcn-resnet18-deepscene /dev/video2 # Python $ python segnet.py --network=fcn-resnet18-deepscene /dev/video2
ただし、森の中にJetson Nanoを持ち込む必要があります。また、「fcn-resnet18-cityscapes」を使用するときは都市の道路などにJetson Nanoを移動させる必要があります。
poseNetは、画像を入力として受け入れ、オブジェクトのポーズのリストを出力します。 各オブジェクトポーズには、検出されたキーポイントのリストと、それらの位置およびキーポイント間のリンクが含まれています。これらを照会・照合して、ポーズの特色を見つけることができます。posenet.cpp (C++)およびposenet.py (Python)の利用の方法については、Pose Estimation with PoseNetを読んでください。
Pose-ResNet18-Bodyを用いて人物のポーズの推論をするコマンドは以下の通りです。
# C++ $ ./posenet "images/humans_*.jpg" images/test/pose_humans_%i.jpg # Python $ ./posenet.py "images/humans_*.jpg" images/test/pose_humans_%i.jpg # C++ $ ./posenet /dev/video2 # csi://0 if using MIPI CSI camera # Python $ ./posenet.py /dev/video2 # csi://0 if using MIPI CSI camera
以上は、Jetson-inferenceに従ってJetPack にインストールされたパッケージ(TensorRT)を利用する方法です。PyTorch などを用いた物体検出については、Jetson Nano で機械学習のページにお進みください。