|
近年の急激なコンピュータ技術の発達により人口知能(AI)技術がロボットや自動車の安全運転、スマホによる自然言語や音声の認識、フィンテック、さらには、セキュリティ・システムやIoTのインフラ技術などに応用されるようになってきました。人工知能(AI)技術の基礎は深層学習(deep learning)と言われる分野での研究開発に多くを負っています。深層学習も機械学習(machine learning)の一つの分野であり、または大量のデータを用いてパラメータの学習をするという意味では、データサイエンスと呼ばれている分野における研究にも属します。
CNNを用いた画像分類(image classifier)の代表的なモデル、VGG16,19、Inception_v3、ResNetなどについてはすでに前のページにて 説明しました。このページでは、一般物体検出(object detection)のネットワーク・モデルを代表する、YOLO、SSD、R-CNN、Caffe、Segnetなどについて概括的な説明を行います。Pythonの機械学習用のライブラリであるScikit-learnを用いた機械学習アルゴリズムの実装については、Scikit-Learnを用いたCNNの実装のページを参照ください。
現在では、Transformer と呼ばれるアーキテクチャーを組み込んだAIが画像識別や物体検出のタスクでも認識精度を向上させています。Transformer を組み込んだコンピュータビジョンの仕組みについては、Transformer のページを参照ください。
通常使用のPCでは、メモリが足りず処理できなかったり、1試行ごとに数十分~数時間もかかる問題などを回避するために、クラウド上のGPUをレンタルするという方法もあります。IBM Cloud、Amazon AWS、Google Cloud Platform、そしてMicrosoft Azure 等のCloud版GPUサービスが提供されています。ただし、これらのサービスの利用は基本的に有料です。
GoogleがGoogle Colaboratory という無料で使用できるCloud サービスを提供しています。Google Colaboratoryは、Jupyter Notebook をベースとした、Googleの仮想マシン上で動くPython実行環境です。無料であり、Googleアカウントを登録すれば、インストール等の作業に手間を取られることなく、すぐに機械学習のコードを実行することができます。ソースコードや実行結果はGoogleドライブに保存されるため、共有・同時編集することが容易に行えます。GPUも無料で利用することができるので、GPUコンピューティングによる機械学習やDeep Learning等の高速化処理も可能です。Google Colaboratoryの使用方法について簡単な説明を行います。
AIに関するページで説明されるPython コードを自分の手で実行したいと希望する方は、Googleのアカウント登録、および、GitHubのアカウントの登録をすることをお勧めします。両方とも無料で行えます。
ディープラーニングの多くのフレームワークはPython及びC++で記述されています。ニューラルネットワークの基本的構造とその実装を理解するための言語としてはPythonが理解できれば十分でしょう。そういう意味では、この領域において必須のプログラミング言語はPythonです。
Last updated: 2026.1.10(first uploaded 2019.4.11)
画像分類(Image Classifier)のPython APIライブラリ |
Deep Learningを基礎とする画像分類(Image Classification)のPython APIライブラリの種類と特徴について大まかに説明します。画像分類(Image Classification)とは、入力画像から画像を検出して、画像のラベルの分類を決定することです。
2012年開催された大規模画像認識のコンペILSVRC(ImageNet Large Scale Visual Recognition Challenge) でAlexNetが圧倒的な成績で優勝して以来、ディープラーニングの手法(CNN)が画像認識での主役に躍り出ました。 2014年に開催されたILSVRCでの優勝者はGoogLeNetでした。GoogLeNetは複雑に見える構成ですが、基本的には、AlexNetのようなCNNと本質的には同じです。ただ、GoogLeNetには、縦方向に深さがあるだけでなく、横方向にも深さがあるという点で異なっています。横方向の幅はinception構造と呼ばれています(Inceptionモデルと呼ばれます) 。
このとき、VGGは2位の成績に終わりましたが、シンプルな構成なので応用面ではよく使用されます。ちなみに、VGGでは、3x3のフィルターによる畳み込み層を2回から4回連続して、プーリング層でサイズを半分にするという処理を繰り返します。重みのある層を16層にしたモデルをVGG16、19層にしたものをVGG19と呼んでいます。
2015年のILSVRCでの優勝者はResNetで、Microsoftのチームによって開発されたニューラルネットワークでした。その特徴は、層を深くしすぎると過学習などの問題が起きるのを回避するために、スキップ構造(ショートカット)と呼ばる概念を導入した点です。ResNetは、VGGのネットワークをベースにして、スキップ構造を取り入れて、層を深くしています。具体的には、畳み込み層を2層おきにスキップしてつなぎ、層を150層以上まで深くしています。ILSVRCのコンペでは、誤認識率が3.5%という驚異的な成果を出しています。
以上のVGG16,19、Inception_v3、ResNetが画像分類の代表的なネットワーク・モデルとなっています。最近では、これらのモデルを改善した物体検出むけのR-CNN、YOLO、SSDなどのモデルも登場しています。
機械学習及びディープラーング向けのPython プラットフォームの中で、Googleが公開したTensorFlow と、Facebook が開発した PyTorch が最も利用頻度が高いものです。
TensorFlow はGoogleのTensorFlowのサイトで公開されています。2019年10月1日、GoogleのTensorFlow開発チームはオープンソースの機械学習ライブラリ TensorFlow 2.0 を発表しました。JavaScript 向けの TensorFlow.js、大規模な実装向けの TensorFlow Extended などを提供し、機械学習向けの包括的なプラットフォームを目指しています。低レベルのAPIも強化し、研究者向けの機能強化も加わっています。
Tensorflowのパッケージのなかで、最も取り扱いが容易なライブイラリはKerasです。Kerasは当初プロジェクトONEIROS (Open-ended Neuro-Electronic Intelligent Robot Operating System) の研究の一環として開発されました。2019年10月にTensorflow 2.0に統合化されています。Kerasを活用すれば、簡単な入力でCNNモデルを構築したり、それを学習させることも容易にできます。Kerasには、VGG16、Inception_v3、ResNetなどのCNNモデルがモジュールとして組み込まれているので、自分でモデルを一から構築する必要がありません。ImageNetのデータを用いて学習した学習済みモデルも用意されていますので、訓練用のデータも必要ありません。実際の運用については、Kerasを使って画像分類のページに説明があります。
PyTorch は Tensorflow と同じく機械学習用の Python 利用プラットホームですが、もともとは、Torch7と呼ばれるLua言語で書かれたライブラリでした。PyTorchは、このTorch7とPreferred Networks社のChainerをベースに2017年2月に作られたPython用ライブラリで、 BSDオープンソースです。現在は、Team PyTorch というコミュニティが開発しています。Chainerは日本のPreferred Networks社が開発したライブラリですが、2019年末に、PyTorchに統合されました。画像分類の Pytorch を用いた実装については、Pytorch による画像分類のページを参照ください。
モバイル デバイスや組み込みデバイスにモデルをデプロイするための軽量なライブラリとして、TensorFlow Lite が利用できます。同じように、PyTorch からもモバイル デバイスで利用可能なPyTorch Mobile が公開されています。これらのAPI は Linux、iOS、Androidをサポートしています。
上記のTensorflow 及び PyTorchの性質とはかなり異なりますが、Caffeと呼ばれる機械学習のフレームワークがあります。Caffeはカリフォルニア大学バークレー校の研究グループがC++を用いて開発したフレームワークです。ホームページは、 http://caffe.berkeleyvision.org/にあります。現在では、Berkeley Vision and Learning Center(BVLC)を中心として、コミュニティの研究者たちがGitHub上で開発を重ねています。Caffeには「Model Zoo」という学習済みのモデルを配布するライブラリーがあります。機械学習ではCNNのパラメータをゼロから学習することが難題となりますが、Model Zooを用いることでこの難題を避けることができます。なお、最近、Caffe2はPytorchに統合されましたので、 Pytorchを経由して実行します。
一般物体検出(Object Detection)のPython APIライブラリ |
自動車の自動運転を実現するためには、センサーから入手したデータから一般物体(人間、車、歩道、樹木など)の検出を可能とするソフトウエアが必要です。コンピュータビジョンの分野における物体検出(Object Detection)とは、ある画像の中から定められた物体の位置とカテゴリー(クラス)を検出することを指します。物体検出の問題は、性質のわからない、数が不明な物体をビデオ画像やカメラ画像から特定するという問題になります。だから、画像からの物体検出は、同時に2つの問題を解決する必要があります。画像の特定の領域が物体であるかどうかを判断し、どの物体であるかを調べる。後者の部分は画像分類にあたるので、上で取り扱ってきた画像分類のモデルを使えば解決できます。が、前者の部分と後者の部分を同時に解決するためには新しいモデルが必要です。
一般的にコンピュータ・ビジョンのカテゴリは以下のように大きく3つに分類されます。
Classification : 各画像ごとにラベルの分類
Object Detection : 画像内で検出された各物体領域ごとにラベルの分類
Segmentation : 画像内の各pixelごとにラベルの分類 (Semantic or Instance)
各タスクごとに用いられるデータセットや指標、そしてアルゴリズムはまったく異なります。Classification(画像分類)でよく利用されるデータセットはMNISTデータセットやImageNetの画像セット、Kaggleのイメージ画像などですが、物体検出の精度の比較によく用いられているデータセットは PASCAL VOC2007 と PASCAL VOC2012 、あるいは、別の年度の PASCAL VOC や MS COCO などのデータセットです。また、物体検出の分野で重要とされている指標は、mAP (mean Average Precision) と FPS (Frame Per Second) です。つまり、物体検出精度と処理速度です。
物体検出アルゴリズムは
Region Proposal : 物体らしい箇所を検出
Classification : 検出箇所のラベル分類
Bounding Box Regression : 正確な物体を囲う位置座標を推定
というRegion Proposal, Classification, Bounding Box Regression の 3 phase に大きく別れています。
Deep Learning(CNN)を応用した一般物体検出アルゴリズムで代表的なものとしては、3種類挙げられます。
R-CNN (Regions with CNN features)の発展系Faster R-CNN、に大別できます。
それらに対応する論文はです。論文の内容までは説明しません。興味のある人は読んで見てください。これらのアルゴリズムを組み込んだプログラムは TensorFlow や Pytorch などの Python APIで実装可能となっています。これらのアルゴリズムを実装したモデルの精度を比較した結果が多数ネット上で閲覧できます。これらによると、YOLO系とSSD系の一騎打ちのようです。Faster R-CNNはセグメンテーションのアルゴリズムとして用いられています。
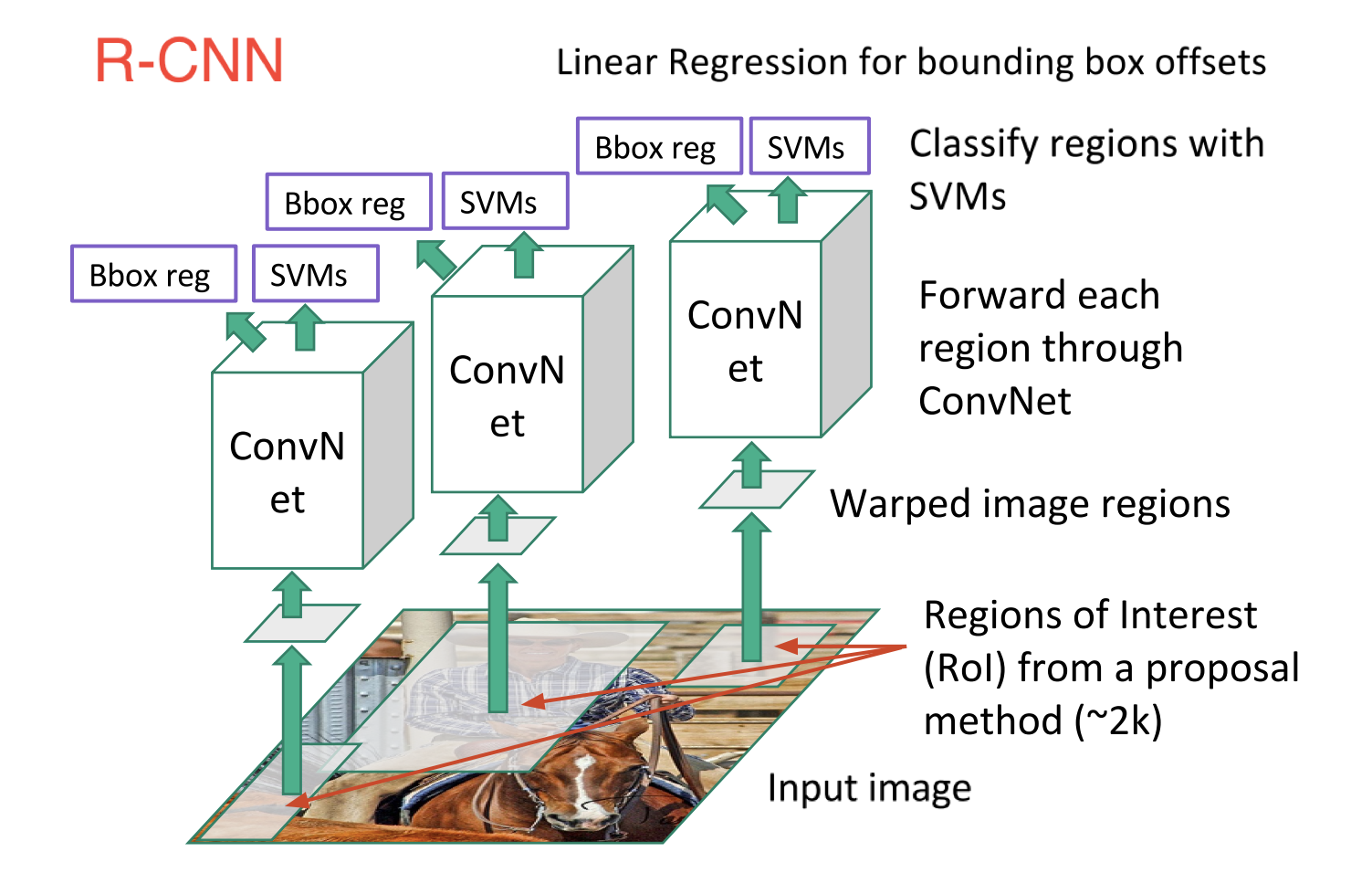
物体検出のアーキテクチャの基礎はR-CNN系のモデルですが、R-CNNのアルゴリズムは
物体が存在する可能性のある領域を提案するの3段階構成になっています。画像内のすべてのピクセルに隈なくCNNを走らせると時間がかかりすぎるので、最初に物体があると予想される領域を提案させて、その領域内のみ計算すればいいので高速化が期待できる。物体がある可能性の領域をregion-of-interest(ROI)と呼びます。ROIを提案するモデルをregion proposalと呼びます。
したがって、R-CNNでは、最初に、物体がありそうな領域の提案(Region Proposal)が行われ、次に、CNNを用いて特徴マップを作成して、物体の分類を行います。最後に、CNNの出力から、物体の分類を確定し、物体の境界ボックス(Bounding Box)を確定します。下の図はこのアルゴリズムを簡単に模型化したものです。
また、Faster R-CNNでは、領域提案のアルゴリズムを改善して、処理の高速化と正確さを達成しています。特に、物体領域の提案をRPN(Region Proposal Network)という別のネットワークを併用することで処理が高速化しています。以下の模型図がFaster R-CNNの構造を示しています。
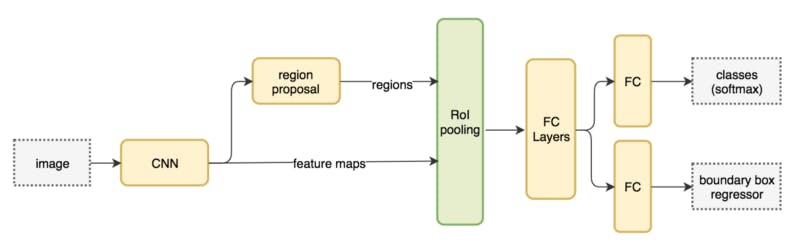
その後登場したYOLO(You Only Look Once)とSSD(Single Shot Multibox Detector)では、画像を多数のグリッドに分割して、それぞれの領域グリッドに対して固定サイズ別のバウンディングボックスの当てはまり具合を見るという方法を採用しています。通常、画像にある物体のサイズはさまざまですが、一回の処理で全ての物体をもれなく検出できるのが望ましいです。しかし、特徴マップがネットワークの深さとともに縮小していきますから、小さい物体の検出は層が深くなるにつれて難易度が上がります。直感的には、物体のサイズに応じて、異なる段階の層で物体を検出するのが理想的です。それ故、異なるサイズを異なる段階の層で処理する仕組みを採用することになります。
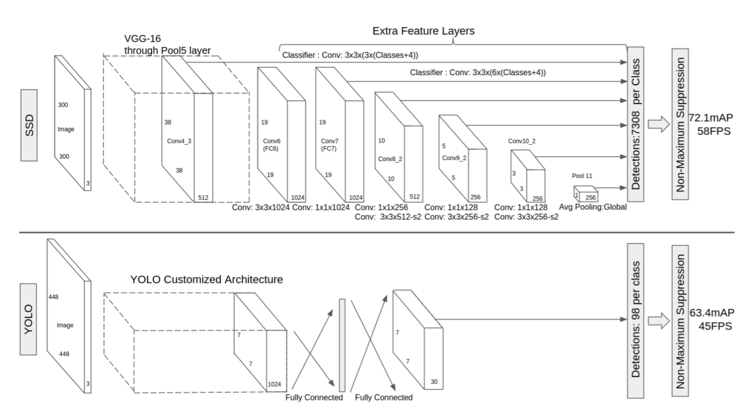
SSDではExtra Feature Layersという畳み込み層を挿入している。図を見れば分かるように、後段に向かうほど特徴マップの分割領域数をスケールダウンさせている。そしてこの分割領域それぞれに対し、いくつかのアスペクト比のデフォルトボックスを対応させ、正解に近いボックスを複数選択しています。
YOLOはv.3からv.7まで、および、それらの派生バージョンScaled-YOLOv4、YOLOS、YOLOR、YOLOXなどもあります。
初期バージョンYOLOv3のネットワークは主に75層の畳み込み層からなり、物体の特徴量を抽出します。Fully connected層を使わないので入力画像のサイズが任意です。また、pooling layerの代わりにstride=2の畳み込み層を用いることで特徴マップをダウンサンプリングし、スケール不変な特徴量を次の層へ伝播しています。このほか、YOLOv3では、ResNetとFPN構造を利用して検出精度を更に向上させています。YOLOv3では速度を少し犠牲にして、精度を上げましたが、モバイルデバイスにしてはまだ重いです。YOLOv3の軽量版であるTiny YOLOv3がリリースされたので、これを使うとリアルタイムで実行可能になります。
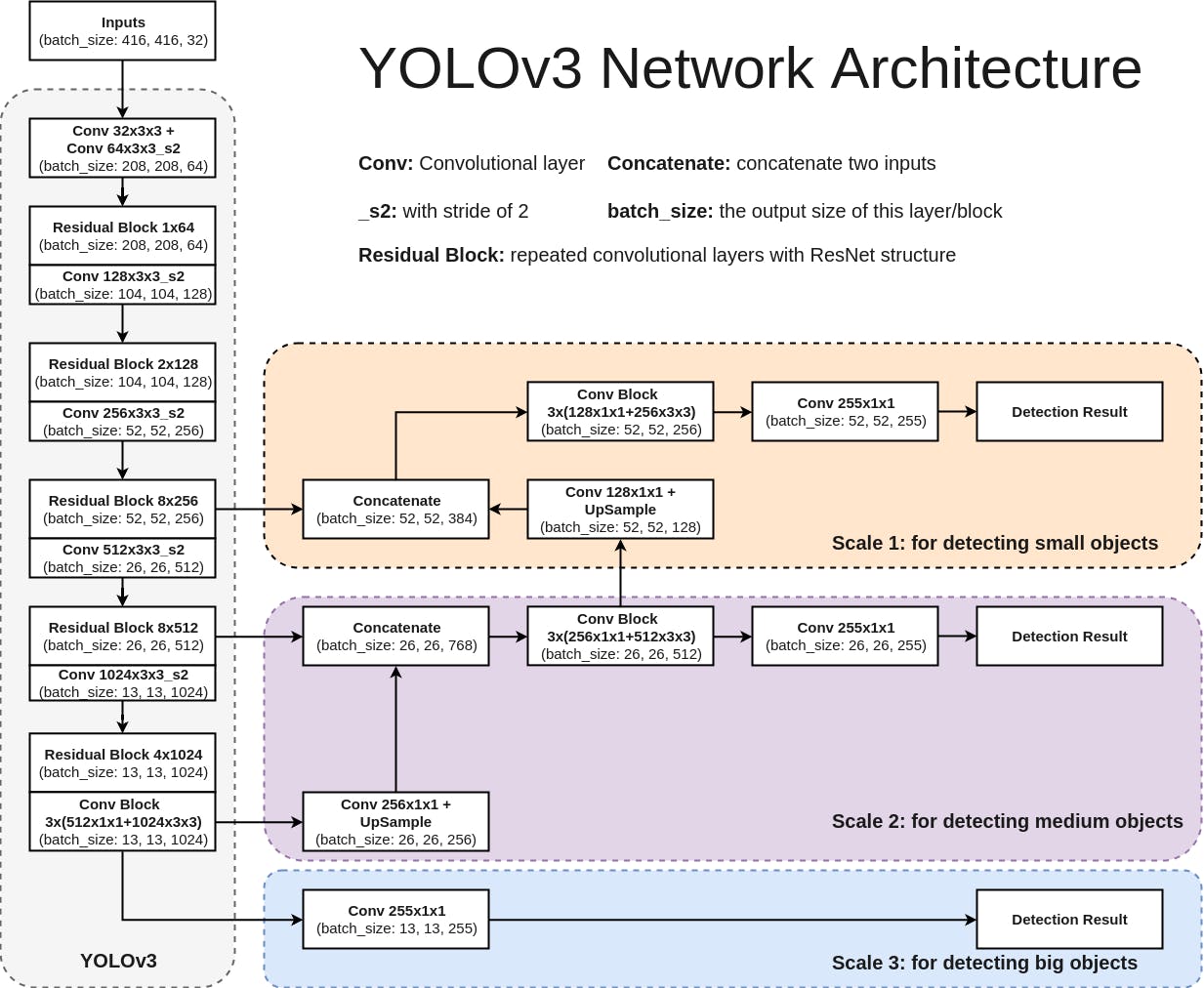
このYOLOv3の画像元はCyberailabからのものです。
YOLOv4、YOLOv5、YOLOv6、YOLOv7と改善がなされていくにつれて、処理スピードが高速化し、検出精度も改善されています。これらの説明と対応するコードについては、Roboflow のサイトを参照ください。
以上で説明した、Faster R-CNN(Region-based Convolutional Neural Network)、YOLO(You Only Look Once)、SSD( Single Shot MultiBox Detector )などのアルゴリズムを実装した Python API ライブラリが利用可能となっています。Tensorflowを用いた物体検出問題に対するPython実装については、Tensorflowで物体検出のページを参照してください。また、Pytorchを用いたSSDやYOLOアルゴリズムのPython実装については、Pytorchで物体検出のページを見て下さい。
Faster R-CNN、YOLOやSSDなどのオブジェクト検出方法の多くのアプローチとアーキテクチャを説明してきました。一方で、最近登場したMask R-CNNは Faster R-CNNの基盤を、オブジェクトを検出するだけでなく、検出された各オブジェクトのピクセルレベルのマスク(画像セグメンテーション)を提供するソリューションに拡張した方法です。
画像セグメンテーションには、セマンティック・セグメンテーションとインスタンス・セグメンテーションの2つの大きなカテゴリがあります。基本的に、インスタンス・セグメンテーションはセマンティックセグメンテーションの拡張です。 理由は次のとおりです。
セマンティックセグメンテーションは、主に前景と背景の間で、各ピクセルを一連のカテゴリに分類します。個々のオブジェクトを区別せず、類似したクラスのオブジェクトのみに焦点を当てます。
一方、インスタンス・セグメンテーションは、同じクラスの個々のオブジェクトの検出に重点を置いています。 結果として、このタイプのセグメンテーションは次の組み合わせになります。
フレーム内の個々のオブジェクトを検出するためのオブジェクト検出
各オブジェクトが存在する場所のバウンディングボックス座標を提供するためのオブジェクトのローカリゼーション
フレームに存在するオブジェクトを分類する物体分類。
従って、インスタンス・セグメンテーションは、セマンティックセグメンテーションからさらに一歩進んで、前景と背景だけでなく、各オブジェクトを明確に区別します。
2017年1月に、Facebookの研究チームであるFacebook AI Research(FAIR)が、Mask R-CNNによる画像セグメンテーションを実装した Detectron2 をオープンソースとして公開しました。FacebookのrepositoryはDetectron2のGithubサイトにあります。Detectron2はディープラーニング向けライブラリのCaffeを基礎としています。GPUの使用を前提としていますが、cpuだけでも学習済みのモデルを利用することはできます。Detectron2の簡単な使用法は、Detectron2 のPython 実装事例にあります。
また、Caffeを基礎とする画像セグメンテーションソフトのフレームワークの一つにSegNetと呼ばれるCNNがあります。SegNetはケンブリッジ大学の研究グループが2015年に開発した画像セグメンテーションのための畳み込みニューラルネットワークです。論文は( Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla,「SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation」)、ホームページは
http://mi.eng.cam.ac.uk/projects/segnet/になります。
このホームページにwebdemoが掲載されていますので、自分の写真をアップして物体検出を実行してみると面白いです。自動車から撮影された動画実例と検出結果もアップされています。楽しんで見てください。
SegNetは以下に示すような畳み込みニューラルネットワークの構造を持っています。
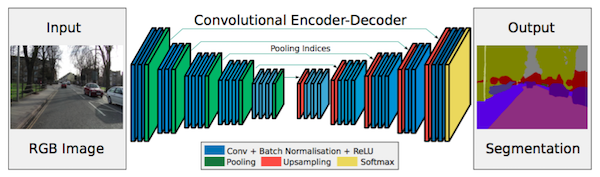
左側の画像は自動車のカメラで撮影された画像で、これが入力画像としてニューラルネットワークでセグメンテーション処理されて出力された結果が右側の画像になります。SegNetの基礎になっているフレームワークはCaffeと呼ばれるCNNなので、Caffeが正常に作動しないPCでは十全に機能しません。注意が必要です。
Google ColaboratoryのGPUを使った機械学習 |
Google Colaboratoryは、Jupyter Notebook をベースとした、Googleの仮想マシン上で動くPython実行環境です。無料であり、Googleアカウントを登録すれば、インストール等の作業に手間を取られることなく、すぐに機械学習のコードを実行することができます。使用するPCなどにはPython環境などをインストールする必要もありません。Google ColaboratoryのGPUを使って機械学習を実行する手順について説明します。Google アカウントは登録していることを前提にします。
Google Colaboratoryを使ってKerasのコードでMNISTデータを用いたモデルの学習と分類を実行してみます。Kerasを用いた機械学習の詳しい説明については、Keras + TensorFlow 2.0 を用いた画像分類のページを参照して下さい。ここでは、Kerasを用いた単純な畳み込みモデルを学習させてみます。
Google Colaboratoryにアクセスします。「ファイル」→「ノートブックを新規作成」を開きます。ノートブックのセルがポップアップします。このColabのセルの中に、以下のコードをコピペします。8層からなるCNNを用いた手書き数字の分類を行うコードです。「ランタイム」で「ランタイムのタイプを変更」をクリックして、「ハードウェア アクセラレータ」でCPUからGPUに切り替えます。
import keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
batch_size = 128
num_classes = 10
epochs = 12
img_rows, img_cols = 28, 28
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = y_train.astype('int32')
y_test = y_test.astype('int32')
y_train = keras.utils.np_utils.to_categorical(y_train, num_classes)
y_test = keras.utils.np_utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs,
verbose=1, validation_data=(x_test, y_test))
「ランタイム」で「すべてのセルを実行」をクリックするか、または、セルの左上の三角形の実行ボタンをクリックして、コードを実行します。結果は以下の通りです。1回のエポックにCPUだと2分ほどかかりますが、GPUでは7秒で処理されます。素晴らしい!
x_train shape: (60000, 28, 28, 1) 60000 train samples 10000 test samples Epoch 1/12 469/469 [==============================] - 17s 9ms/step - loss: 0.0724 - accuracy: 0.8840 - val_loss: 0.0135 - val_accuracy: 0.9794 Epoch 2/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0236 - accuracy: 0.9702 - val_loss: 0.0098 - val_accuracy: 0.9845 Epoch 3/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0182 - accuracy: 0.9765 - val_loss: 0.0088 - val_accuracy: 0.9865 Epoch 4/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0157 - accuracy: 0.9799 - val_loss: 0.0089 - val_accuracy: 0.9866 Epoch 5/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0135 - accuracy: 0.9834 - val_loss: 0.0071 - val_accuracy: 0.9893 Epoch 6/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0118 - accuracy: 0.9860 - val_loss: 0.0070 - val_accuracy: 0.9900 Epoch 7/12 469/469 [==============================] - 5s 10ms/step - loss: 0.0108 - accuracy: 0.9871 - val_loss: 0.0065 - val_accuracy: 0.9902 Epoch 8/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0100 - accuracy: 0.9881 - val_loss: 0.0063 - val_accuracy: 0.9908 Epoch 9/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0094 - accuracy: 0.9884 - val_loss: 0.0067 - val_accuracy: 0.9909 Epoch 10/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0086 - accuracy: 0.9898 - val_loss: 0.0063 - val_accuracy: 0.9907 Epoch 11/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0077 - accuracy: 0.9915 - val_loss: 0.0064 - val_accuracy: 0.9916 Epoch 12/12 469/469 [==============================] - 4s 9ms/step - loss: 0.0074 - accuracy: 0.9914 - val_loss: 0.0065 - val_accuracy: 0.9916
テストデータによる検証の正確度は0.9983になります。ノートブックに名前をつけて、「ファイル」で保存して、ウインドウを閉じていいです。自分のアカウントのGoogle Drive に保存されます。GitHubにアカウントを持っていれば、GitHubのrepoに保存することもできます。ちなみに、これがGitHub Repに保存したノートブックです。「Open in Colab」をクリックすれば、Google Colabでノートブックが開くので、すぐ実行できます。
保存したノートブックを再度編集・使用したいときは、Google Drive のサイトにログインして、「アプリで開く」「Google Colaboratory」をクリックします。最初のときは、「アプリで開く」で「アプリを追加」で「Google Colaboratory」を追加します。Google Colaboratoryのサイトにアクセスしても、Google Drive に行けます。
Google Colaboratoryのホームページには、機械学習をするためにseedbank という例が掲載されています。Keras と TPU で Fashion MNISTを用いて、 ファッション関連の画像をディープラーニングで分類するノートブックや、独自の写真から DeepDream 画像を生成できるDeepDreamのノートブックも実習できます。
自分のPCにあるファイルやフォルダーをGoogle Colabにアップロードするときは、Google Driveに行って「マイドライブ」を右クリックすると、又は、「新規」をクリックすると、プルダウンに「フォルダーをアップロードする」という項目を選択します。アップロードしたノートブックはGoogle Colabのアプリで開けば、すぐに実行できます。
アップロードした画像ファイルなどをGoogle ドライブにマウントして、そのドライブで画像ファイルを読み書きする方法を説明します。使用するノートブックの最初のセルに、以下のように入力します。
from google.colab import drive
drive.mount('/content/drive')
----
Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?
Enter your authorization code:
とでますので、上記URLに行って、Driveへのログインの認証をしたら、ポップアップしたページの「このコードをコピーし、アプリケーションに切り替えて貼り付けてください。」から認証コードをコピーして、Enter your authorization code:の後に貼り付けて使用します。
Mounted at /content/drive
と確認がされたら、以下のように使用します。実行後は、https://drive.google.com/ で新しいファイル(foo.text)を確認できます。
with open('/content/drive/My Drive/foo.txt', 'w') as f:
f.write('Hello Google Drive!')
!cat /content/drive/My\ Drive/foo.txt
Driveにアップロードした画像データ(images/*.jpgなど)を読み込むためのパス(img_path)を設定するときは、例えば、photo.jpgを読み込むためには、以下のようにします。
img_path ="/content/drive/My Drive/images/photo.jpg"
これらの例は、ファイルの読み取り、書き込みに対応しています。
Github の仕組みと使用法について |
GitHubとは、Gitの仕組みをオンライン上で動くようにしたサービスです。その用語の説明からします。
ここでは,GitHubにデータを送信するまでの大まかな流れと仕組みを説明します
①ローカル・リポジトリを作成する
②ローカル・リポジトリにファイルを追加する
③追加したファイルをリポジトリに登録する
④追加・編集したファイルをリモート・リポジトリにプッシュする
これで、GitHubへのアップロードは完了します。
それでは早速GitHubにアカウントの登録してみましょう。まずは、GitHubのトップページにアクセスします。ここで、ユーザ名とメールアドレス、パスワードを入力して、アカウント登録を行ってください。Freeプランで登録するので、「Free」を選んでから「Finish sign up」ボタンをクリックします。
ではまず,GitHub上にリポジトリを作ります。GitHubにログインした状態で、TOPページ右下の,「+New Repository」を押してください。次に表示される画面では、「Repository name」の入力のあと、必要に応じて「Description」も入力します。また、リポジトリの種類を「Public」か「Private」を選択します。この「Private」リポジトリは、有料会員のみ作成することが可能です。無料の「Public」を選択します。必要項目の入力が終わり「Create repository」ボタンをクリックするとリポジトリの作成は完了です。表示されたページのURIを使いますので,とりあえずそのアドレスをメモって下さい。
次に、ローカルのPC上にローカルリポジトリを作成します。今回は「hello」というディレクトリを作成することにします。
$ mkdir hello $ cd hello $ git init
「mkdir」は新しくディレクトリを作成するコマンドで、「cd」はディレクトリを移動するコマンドになります。Helloというディレクトリを作成し、そのディレクトリに移動してから作業を始めます。この「git init」コマンドはGitリポジトリを新たに作成するコマンドです。
例えば、「README.md」のファイルをローカルリポジトリに追加しましょう。以下のコマンドでインデックスに追加します。インデックスとは、リポジトリにコミットする準備をするために変更内容を一時的に保存する場所のことです。
$ git add README.md
フォルダー内のすべてのファイルを追加する時は、" git add . " と打ちます。
次に、インデックスに追加されたファイルをコミットします。コミットとは、ファイルやディレクトリの追加や変更をリポジトリに記録する操作のことです。
$ git commit -m "add _new file"
これで、リポジトリに対してファイルの追加が記録されました。ファイルが追加されているか確認します。
$ git status
さらに、リモートリポジトリに反映させる前に、リモートリポジトリの情報を追加します。この情報は、先ほどGitHub上に表示された、リモートリポジトリのアドレスです。今回は例を示します。
$ git remote add origin https://github.com/ /hello.git
ローカルリポジトリの変更を、GitHub上にあるリモートリポジトリに反映させるため、以下のコマンドを実行します。
$ git push origin master
GitHubのユーザ名とパスワードを尋ねられますので入力してください。これで、GitHubへプッシュしてリモートリポジトリへ反映させることができました。
新しく作成したファイルをgitに追加、コミットすには、
$ git add goodmorning.html $ git commit -m "add a _new file " $ git push origin master
これで、GitHub上のリモート・リポジトリに対してファイルの追加が完了しました。こでは、master ブランチだけを用いてます。
なお、GitHub 上のリポジトリを新しく作成して、直接編集することもできます。自身のGitHubのページに行き、「Your repositories」をクッリクして、リポジトリのリストを表示させます。新しいリポジトリを作成するときは、「New」をクリックして、「Repository name」に名称を記入して作成します。
新しいファイルを追加したいときは、対応するリポジトリを開きます。ローカルのPCからアップロードする時は「Upload files」をクリックします。もしくは、新しいファイルを編集して、追加したい時は「Create _new file」をクリックします。追加したファイルを確定するために、必ず、編集の変更などの「Commit _new file」を確定する必要があります。この確定を実行しないと、ファイルの変更などが登録されません。詳しくは、Getting started with GitHub を参照ください。
GitHubのpublic keyを登録していないと、鍵のかかったrepoをgit clone する際、以下のようなエラーが出ます。
git@github.com: Permission denied (publickey).
fatal: Could not read from remote repository.
このような公開鍵をかけたrepoをgit clone するために、public key を登録してから git cloneします。
まずは、公開鍵と秘密鍵のペアを生成しましょう。鍵を入れる.sshフォルダに移動します。次に、コマンドで鍵を生成します。
$cd ~/.ssh $ssh-keygen -t rsa
はじめて鍵を生成するときは何も入っていないはずです。オプションは付けずに、このコマンドで十分です。
Generating public/private rsa key pair. Enter file in which to save the key (/Users/(username)/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again:
デフォルトのまま、3回エンターキーを押せば、id_rsaとid_rsa.pubの2つの鍵が生成されます。 なお、2回目、3回目はパスワード設定のようなものですが、この設定はなくて大丈夫です。
GitHub に鍵を登録します。以下のgithub.com/settings/sshを開きます。「New SSH key」をクリックして、名称とキーの内容を登録します。
鍵の中身のクリップボードへのコピーは以下のコマンドで可能です。
$ pbcopy < ~/.ssh/id_rsa.pub # for Mac $ clip < ~/.ssh/id_rsa.pub # for Windows