SSD ネットワークの構成
|
PyTorch はディープラーニングを実装する際に用いられるディープラーニング用ライブラリのPython APIの一つです。もともとは、Torch7と呼ばれるLua言語で書かれたライブラリでした。Chainerは日本のPreferred Networks社が開発したライブラリですが、Pytorchに統合されました。Caffe2もPyTorchに併合されました。現在、PyTorch は Team PyTorch によって開発されています。PyTorchの利点はDefine by Run(動的計算グラフ)と呼ばれる特徴です。Define by Runは入力データのサイズや次元数に合わせてニューラルネットワークの形や計算方法を変更することができます。
多くのユーザーを持つディープラーニングの Python API であるTensorFlow の特徴は Define and Run(静的計算グラフ)と呼ばれます。Define and Runではニューラルネットワークの計算方法をはじめに決めてしまうため、入力データの次元がデータごとに異なる状況に対応しづらいという特徴があります 。Keras + Tensorflow は見やすく簡易で、非常に簡単にネットワークを作成できるので、人工知能の専門家以外の人たちにとって、使いやすい必須の道具となっています。しかし、アップグレードが後方互換性を持たないという欠点と、動作が遅いという問題点もあります。他方で、PyTorchは、Define by Runという特徴ゆえに、AIを開発する専門家に必須のアイテムになりつつあります。Object Detection用のライブラリの中では処理速度が最も最速です。
このページでは、PyTorch を利用した物体検出の Python 実装を取り上げます。最初に、画像分類と物体検出の関係について簡単な説明をします。その後、物体検出のためのアルゴリズムである SSD を取り上げて説明し、その Python 実装例を紹介します。さらに、物体検出のもう一つの有用なアルゴリズムである YOLO の Python 実装について説明します。このページの主要な目的は、web camera からのライブ映像の物体検出になります。Pytorch のインストール方法は公式ページに行き、install ページの手順に従って、Run this Command:のコマンドラインをコピペして下さい。最新バージョンは Pytorch 1.12.1 ですが、このページで使用したバージョンはPytorch 1.10.2 です。以下の説明も注意書きがしていない限り、このバージョンで実証しています。PyTorch の初歩および画像分類に関する説明は、Pytorch入門のページを参照ください。
Pytorch の examples パッケージはpytorch examplesからダウンロードできます。
Last updated: 2022.9.20(first uploaded 2018.6.13)
物体検出と画像分類の関係 |
画像分類の歴史は大体以下のようになります。
畳み込みネットワークを組み込んだAlexNetが、2012年開催された大規模画像認識のコンペILSVRC(ImageNet Large Scale Visual Recognition Challenge) で圧倒的な成績で優勝しました。それ以来、ディープラーニングの手法(CNN)が画像分類での主役に躍り出ました。2014年に開催されたILSVRCでの優勝者はGoogLeNetでした。GoogLeNetは複雑に見える構成ですが、基本的には、AlexNetのようなCNNと本質的には同じです。ただ、GoogLeNetには、縦方向に深さがあるだけでなく、横方向にも深さがあるという点で異なっています。横方向の幅はinception構造と呼ばれています(Inceptionモデルと呼ばれます) 。
このとき、VGGは2位の成績に終わりましたが、シンプルな構成なので応用面ではよく使用されます。ちなみに、VGGでは、3x3のフィルターによる畳み込み層を2回から4回連続して、プーリング層でサイズを半分にするという処理を繰り返します。重みのある層を16層にしたモデルをVGG16、19層にしたものをVGG19と呼んでいます。
2015年のILSVRCでの優勝者はResNetで、Microsoftのチームによって開発されたニューラルネットワークでした。その特徴は、層を深くしすぎると過学習などの問題が起きるのを回避するために、スキップ構造(ショートカット)と呼ばる概念を導入した点です。ResNetは、VGGのネットワークをベースにして、スキップ構造を取り入れて、層を深くしています。具体的には、畳み込み層を2層おきにスキップしてつなぎ、層を150層以上まで深くしています。ILSVRCのコンペでは、誤認識率が3.5%という驚異的な成果を出しています。
画像分類(Image Classification)は同じクラスの物体の画像に写っている物体のラベルの分類を目指すものです。一方、一つの画像の中に写っている複数の物体を検出して、その物体の分類を行うことを物体検出(Object Detection)と言います。物体検出の中で、物体の分類処理に使用されアルゴリズムが画像分類で開発されてきた CNN モデルです。また、この物体検出に付随して、画像内の各pixelごとに、あるいは、グリッドごとのラベルの分類を与えることを Segmentation あるいは region proposal と言います。画像の特定の領域が物体であるかどうかを判断する( Bounding Boxの) region proposal アルゴリズムが必要となります。
現実の課題として、例えば、自動車の自動運転を実現するためには、センサーから入手したデータから一般物体(人間、車、歩道、樹木など)の検出を可能とするソフトウエアが必要です。これを担う物体検出ソフトが、ライブ映像の画像の中から定められた物体の位置とラベル(クラス)を検出します。物体検出の問題は、性質のわからない、数が不明な物体をビデオ画像やカメラ画像から特定するという問題になります。
画像分類と物体検出の学習で用いられるデータセットや指標はまったく異なります。Image Classification(画像分類)でよく利用されるデータセットは MNIST データセットや ImageNet の画像セット、Kaggleのイメージ画像などです。一方、物体検出の精度の比較によく用いられているデータセットは PASCAL VOC2007 と PASCAL VOC2012 、あるいは、別の年度の PASCAL VOC や MS COCO などのデータセットです。物体検出の学習では、物体のラベルだけでなく、各物体の位置情報も必要となります。また、物体検出の分野で重要とされている指標は、mAP (mean Average Precision) と FPS (Frame Per Second) です。
PASCAL VOC2007のデータセットは、以下のような分類となっています。
20 classes: Person: person Animal: bird, cat, cow, dog, horse, sheep Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor Train/validation/test: 9,963 images containing 24,640 annotated objects
MS COCO (Microsoft Common Object in Context) データセットは、Microsoft が提供しているアノテーション付きの画像データです。以下のように80 classesに分類されたデータセットです。
person, bicycle, car, motorbike, aeroplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot hot dog, pizza, donut, cake, chair, sofa, pottedplant, bed, diningtable, toilet, tvmonitor laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator book, clock, vase, scissors, teddy bear, hair drier, toothbrush
Deep Learning(CNN)を応用した一般物体検出アルゴリズムで有名なものとしては、3種類挙げられます。Faster R-CNN(R-CNN の発展系)、YOLO(You Only Look Once)、SSD( Single Shot MultiBox Detector)に大別できます。
TensorFlow や Pytorch などのライブラリに実装されている物体検出のアルゴリズムでは
という 3 phase に大きく別れています。
以下では、PyTorch を用いた物体検出のPython API ライブラリ、SSD系のアルゴリズムを実装する事例などをいくつか紹介します。また、YOLO系モデルの一つであるDarkentを活用する方法についても紹介します。
SSD in PyTorch framework: VGG16 |
既に触れた通り、Deep Learning(CNN)を応用した一般物体検出アルゴリズムで有名なものとしては、3種類挙げられます。 Faster R-CNN 、YOLO(You Only Look Once) 、SSD(Single Shot MultiBox Detector) に大別できます。YOLO と SSD 以前のモデルでは、バウンディング・ボックスの提案をする処理と物体識別をする処理の2種類の CNN が必要でした。そのためリアルタイムでの物体検出における処理時間に課題がありました。YOLO と SSD では、バウンディング・ボックスの提案をする処理を入力画像の物体識別の CNN と統合することにより、処理時間を短縮しました。
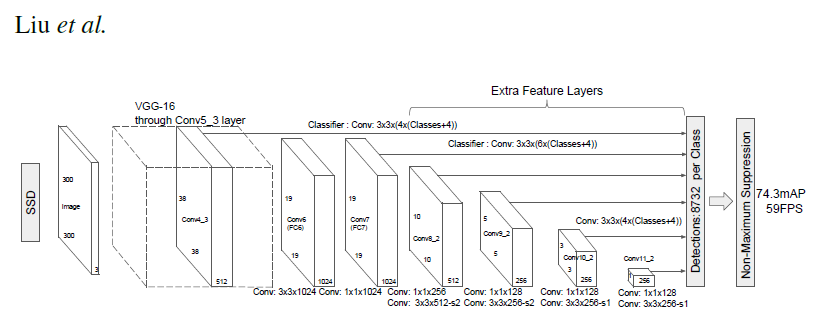
始めに、SSD の特徴を簡単に説明します。SSD モデルでは、デフォルト・ボックスという概念を使用します。デフォルト・ボックスとは画像マップの各セルを中心とする4種類または6種類の(各辺の長さが異なる)四角形のことです。画像識別の CNN 、例えば、VGG16やResNetなどに、みられるように、畳み込み層は様々なサイズの特徴マップを生成します。SSD では、これらのうちサイズ38x38 、 19x19 、 10x10 、 5x5 、3x3 、 1x1 の特徴マップにおいて、各マップをデフォルト・ボックスで覆います。したがって、総数で8732個(38x4+19x6+10x6+5x6+3x4+1x4))のデフォルト・ボックスが存在します。これらのボックスの中に何らかの物体が存在するか否かを調べて、その物体を識別します。物体識別の確率が最も高いデフォルト・ボックスだけを残し、それを物体検出のバウンディング・ボックスとします。
SSD ネットワークの構成
SSD モデルの Pytorch 実装を説明するコードとして最も分かり易い例として、この GitHub Repの ssd.pytorch を利用します。この Repo を git clone すると、以下の構成になっているフォルダーが作成されます。
. ├── LICENSE ├── README.md ├── data │ ├── __init__.py │ ├── coco.py │ ├── coco_labels.txt │ ├── config.py │ ├── example.jpg │ ├── dog.jpg │ ├── eagle.jpg │ ├── giraffe.jpg │ ├── herd_of_horses.jpg │ ├── messi.jpg │ └── person.jpg │ ├── scripts │ │ ├── COCO2014.sh │ │ ├── VOC2007.sh │ │ └── VOC2012.sh │ └── voc0712.py ├── demo │ ├── __init__.py │ ├── demo.ipynb │ └── live.py ├── doc │ ├── SSD.jpg │ ├── detection_example.png │ ├── detection_example2.png │ ├── detection_examples.png │ └── ssd.png ├── layers │ ├── __init__.py │ ├── box_utils.py │ ├── functions │ │ ├── __init__.py │ │ ├── detection.py │ │ └── prior_box.py │ └── modules │ ├── __init__.py │ ├── l2norm.py │ └── multibox_loss.py ├── utils │ ├── __init__.py │ └── augmentations.py ├── eval.py ├── ssd.py ├── test.py └── train.py
Google Colab で実行する時は、この Github Repo をGoogle Colab で git clone 方式で実行できます。
Colab にアップした ssd_pytorch_demo を使用することにましょう。その内容を簡単に説明します。
Repo を git clone したら、VGG16の重み (vgg16_reducedfc.pth) をフォルダー ssd.pytorch/weights に保存します。
! git clone https://github.com/mashyko/ssd.pytorch
import os
os.chdir('ssd.pytorch')
! mkdir weights
%cd weights
! wget https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth
フォルダー weights が作成され、そこに必要なVGG16学習済みモデルが保存されます。さらに、VOC0712のデータセットで学習された SSD300 pretrained model( PyTorch 用のweights)も
! wget https://s3.amazonaws.com/amdegroot-models/ssd300_mAP_77.43_v2.pth %cd ..
とダウンロードする必要があります。この後に、画像を読み込みます。
import os
import sys
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
from torch.autograd import Variable
import numpy as np
import cv2
if torch.cuda.is_available():
torch.set_default_tensor_type('torch.cuda.FloatTensor')
from ssd import build_ssd
net = build_ssd('test', 300, 21) # initialize SSD
net.load_weights('weights/ssd300_mAP_77.43_v2.pth')
image = cv2.imread('./data/dog.jpg', cv2.IMREAD_COLOR) # uncomment if dataset not downloaded
%matplotlib inline
from matplotlib import pyplot as plt
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# View the sampled input image before transform
plt.figure(figsize=(10,10))
plt.imshow(rgb_image)
plt.show()
dog.jpg の画像が表示されます。その後に、物体検出をするコードを置きます。
x = cv2.resize(image, (300, 300)).astype(np.float32)
x -= (104.0, 117.0, 123.0)
x = x.astype(np.float32)
x = x[:, :, ::-1].copy()
x = torch.from_numpy(x).permute(2, 0, 1)
xx = Variable(x.unsqueeze(0)) # wrap tensor in Variable
if torch.cuda.is_available():
xx = xx.cuda()
y = net(xx)
from data import VOC_CLASSES as labels
top_k=10
plt.figure(figsize=(10,10))
colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist()
plt.imshow(rgb_image) # plot the image for matplotlib
currentAxis = plt.gca()
detections = y.data
# scale each detection back up to the image
scale = torch.Tensor(rgb_image.shape[1::-1]).repeat(2)
for i in range(detections.size(1)):
j = 0
while detections[0,i,j,0] >= 0.6:
score = detections[0,i,j,0]
label_name = labels[i-1]
display_txt = '%s: %.2f'%(label_name, score)
pt = (detections[0,i,j,1:]*scale).cpu().numpy()
coords = (pt[0], pt[1]), pt[2]-pt[0]+1, pt[3]-pt[1]+1
color = colors[i]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2))
currentAxis.text(pt[0], pt[1], display_txt, bbox={'facecolor':color, 'alpha':0.5})
j+=1
dog.jpg の画像に対する物体検出が行われます。実行すると、以下のような物体検出の画像が表示されます。

なお、GitHub repo にある ssd_pytorch_demo.ipynb も Colab でそのまま実行できます。/content/ssd.pytorch/data/ の中には、画像データとして以下のものが用意されています。
dog.jpg eagle.jpg example.jpg giraffe.jpg herd_of_horses.jpg img1.jpg img2.jpg img3.jpg img4.jpg messi.jpg person.jpg
data フォルダーにある画像を交互に使用して物体検出を実行してみて下さい。
次に、SSDモデルの学習を取り上げます。SSD の学習用データセットとしては、 Microsoft CoCo2014 または PASCAL Visual Object Classes (VOC2007, VOC2012)を使用します。ここでは、VOC2007 を利用します。VOC は20クラスのデータセットで、画像ファイルとアノテーション・ファイルから構成されます。モデルの学習はGPU の使用を前提としていますので、Google Colab を使用することにします。
それゆえ、私のGitHub Repo フォルダーを Google Colab に git clone します。ssd.pytorch というノートブックが配置されていますので、それを開いて下さい。以下のようにセルから始まります。
!git clone https://github.com/mashyko/ssd.pytorch !sh data/scripts/VOC2007.sh >& VOC2007.log !sh data/scripts/VOC2012.sh >& VOC2012.log
VOC2007.sh(VOC2012.sh)がVOC2007(VOC2012) データセットを読み込むためのファイルです。VOCdevkit というディレクトリの下にVOC2007 と VOC2012 という名称のフォルダーが作成され、その中に画像ファイルとアノテーション・ファイルがダウンロードされます。2ギガ以上のサイズがあります。
このノートブックを用いてモデルの学習をしてみましょう。以下のセルを順番に実行します。
!mkdir /root/data/coco !cp ssd.pytorch/data/coco_labels.txt /root/data/coco/ !cd ssd.pytorch; python train.py --dataset VOC --dataset_root ~/data/VOCdevkit --batch_size 16 --lr 1e-5
train.py を実行すると、/root/data/coco/coco_labels.txt をアクセスするので、先頭の2行のコードが必要です。これがないと、coco_labels.txt がないというエラーが出ます。max_iter = 20000 とエポック数を少なくしていますが、20時間以上かかると思われます。
ここで説明した ssd.pytorch のオリジナルコードをPytorch 1.3 以上のバージョンでもより使いやすい形に改良したプログラムがあります。『PyTorchニューラルネットワーク実装ハンドブック』の第7章で、SSD の説明とその使用法が解説されていて、それに対応するコードが提供されています。この書籍に付録するコードは、この GitHub Repo にあります。Google Colab で利用可能になっています。この書籍で提供されたコードを部分的に修正したプログラムは、この Colab のコードで実行できます。学習済みモデルを使った物体検出および VOC データセットを用いたモデルの学習が実験できますので、ご利用ください。ただし、学習には半日以上の時間がかかります。 Google Colab は連続で12時間までですので、config.py ファイルでの設定で max_iterを少なくして、途中で切れないようにして下さい。
NVIDIA が提供しているSSDモデルは、ResNet-50 modelを用いています。このColab で実行できます。また、(白血球、赤血球、血小板の画像ファイル)BCCD Dataset を用いて、新たなクラスの物体検出が試みた SSD モデルのコードは、このサイトにありますが、セキュリティーの警告が出ます。
ところで、PyTorch で Pascal VOC のデータセットを使うのに、 Torchvision の VOCDetection というクラスです。 Pascal VOC のデータを簡単に読み込めるようなクラスが用意されています。 クラスは下のような引数をとります。image_set は train, trainval, val の3種類を取ります。
torchvision.datasets.VOCDetection(root, year='2012', image_set='train', download=False, transform=None, target_transform=None, transforms=None)
返り値は、(image,target)で、imageはPILの画像、targetはxml treeの辞書となっている。 targetには画像サイズやbounding boxの位置などの情報が入っている。
2012年のデータセットのtrainを使う例を取り上げます。 download=Trueなので、実行するとデータがrootで指定した ./VOCDetection/2012 にダウンロードされます。
import torchvision voc_dataset=torchvision.datasets.VOCDetection(root="./VOCDetection/2012",year="2012",image_set="train",download=True)
データセットから一番最初のデータを取得してみます。 返り値は、画像とアノテーション情報になります。画像を表示してみます。
image,target=voc_dataset[0] from IPython.display import display display(image)
SSD in PyTorch framework: Mobilenet |
次に、軽量CNN モデルの MobileNet を使用した SSD アルゴリズムを組み込んだ Pytorch コードを取り上げます。ライブカメラからの映像の物体検出を行いたいので、Google Colab は使用しません。 MobileNet モデルによるライブ映像から物体検出を試みましょう。この作業を実行するにあたり、github repo にあるpytorch-ssdを利用します。このリポジトリを git clone しましょう。
git clone https://github.com/mashyko/pytorch-ssd
展開後に、pytorch-ssd という名称のフォルダーが作成されます。
README.md に 「 Single Shot MultiBox Detector Implementation in Pytorch 」なるタイトルの下に使用するための記述が並んでいます。ここまでにインストールした環境で正常に作動しますので、新たにインストールすべきモジュールはありません。このパッケージは、MobileNetV1、 MobileNetV2、および VGG based SSD/SSD-Lite を用いた物体検出ができます。ここでは、MobilenetV1 SSD を用いた物体検出の事例を取り上げます。
MobilenetV1 SSDを用いた画像からの物体検出、および、webcameraの映像からの物体検出は以下の手順で行います。はじめに、学習済みのモデルの重みをダウンロードして、データのラベル分類をダウンロードします。
$ wget -P models https://storage.googleapis.com/models-hao/mobilenet-v1-ssd-mp-0_675.pth $ wget -P models https://storage.googleapis.com/models-hao/voc-model-labels.txt
画像から物体検出を行うときは、ディレクトリ data/ を作成し、その中に画像を配置します。python script "run_ssd_example.py" を使用します。引数の1番目は、net_type を指定するので、ここでは「mb1-ssd」とします。2番目の引数は model_path の指定なので 、「models/mobilenet-v1-ssd-mp-0_675.pt」とし、3番目の引数でlabel_path を指定するので、「models/voc-model-labels.txt」とします。 引数の最後に検出対象の画像へのパスを追加します。ターミナルのシェルプロンプトをpytorch-ssdのディレクトリにおいて、以下のようにして実行します。
$ python run_ssd_example.py mb1-ssd models/mobilenet-v1-ssd-mp-0_675.pth models/voc-model-labels.txt data/dog.jpg ********** result***** Inference time: 0.09679794311523438 Found 3 objects. The output image is run_ssd_example_output.jpg
この結果、run_ssd_example_output.jpg という画像ファイルで保存されます
webcam からのライブ映像から物体検出を行うとき、python script "run_ssd_live_demo.py"を実行します。ターミナルのシェルプロンプトをpytorch-ssdのディレクトリにおいて下さい。
$ python run_ssd_live_demo.py mb1-ssd models/mobilenet-v1-ssd-mp-0_675.pth models/voc-model-labels.txt
最新の OpenCV を使用するとき、ssd_live_demo.py を修正しないとエラーが出ます。以下のように修正して下さい。
from vision.ssd.vgg_ssd import create_vgg_ssd, create_vgg_ssd_predictor
from vision.ssd.mobilenetv1_ssd import create_mobilenetv1_ssd, create_mobilenetv1_ssd_predictor
from vision.ssd.mobilenetv1_ssd_lite import create_mobilenetv1_ssd_lite, create_mobilenetv1_ssd_lite_predictor
from vision.ssd.squeezenet_ssd_lite import create_squeezenet_ssd_lite, create_squeezenet_ssd_lite_predictor
from vision.ssd.mobilenet_v2_ssd_lite import create_mobilenetv2_ssd_lite, create_mobilenetv2_ssd_lite_predictor
from vision.utils.misc import Timer
import cv2
import sys
if len(sys.argv) < 4:
print('Usage: python run_ssd_example.py
修正する必要がある部分は、71行と74行の int(box[...])のように整数にした箇所です。これは cv2.rectangle() の引数が整数であるという要求からです。OpenCV のバージョンのアップデートによります。
ライブ映像が表示されて、COCOデータセットのラベルで物体検出が行われます。以下のよう形式で表示されると思います。

MobileNetV2 SSD Liteを使用するときは、それに対応するモデルを使用しますので、以下のように入力してダウンロードします。
$ wget -P models https://storage.googleapis.com/models-hao/mb2-ssd-lite-mp-0_686.pth
webcamera のライブ映像から物体検出を行うためには、以下のコマンドで実行します。
$ python run_ssd_live_demo.py mb2-ssd-lite models/mb2-ssd-lite-mp-0_686.pth models/voc-model-labels.txt
上記のモデルと同様なライブ映像が表示されますが、それよりも軽くて速いです。
写真ファイルの画像を使用するときは、コマンドの最後に検出対象の画像へのパスを追加します。ディレクトリ data/ を作成し、その中に配置して、以下のように
$ python run_ssd_example.py mb2-ssd-lite models/mb2-ssd-lite-mp-0_686.pth models/voc-model-labels.txt data/dog.jpg
と実行します。run_ssd_example_output.jpg という名称で保存されます。エラーが出たら、run_ssd_live_demo.py と同様の修正をします。
Caffe2 モデルを用いることできます。
$ wget -P models https://storage.googleapis.com/models-hao/mobilenet_v1_ssd_caffe2/mobilenet-v1-ssd_init_net.pb $ wget -P models https://storage.googleapis.com/models-hao/mobilenet_v1_ssd_caffe2/mobilenet-v1-ssd_predict_net.pb $ python run_ssd_live_caffe2.py models/mobilenet-v1-ssd_init_net.pb models/mobilenet-v1-ssd_predict_net.pb models/voc-model-labels.txt
と実行すればいいのですが、ここではこれ以上の手順は省略します
YOLO(You Only Look Once) v3, v4 :darknet |
YOLO(You Only Look Once)とは、畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)を用いた物体検出アルゴリズムの一つです。現時点ではv4までのアップグレードが存在します。また、Tiny YOLOというサイズの小さなバージョンも開発されています。YOLOは、SSDの物体検出アルゴリズムとは異なり、画像をバウンディングボックスで分割してクラス分類を行なっている。このモデルはPyTorch などには依存しませんが、この後でPytorch を用いてYOLOを実装する前の準備として、説明します。
YOLOのバージョンはV.2からV.5まであります。YOLOv.3までは、当時大学院生だったJoseph Chet Redmon 氏が開発したものです。YOLO v.3はDarknetというC言語コードで書かれたスクリプトをコンパイルした実行ファイルを用いて処理を行います。こちらのホームページを参照ください。その後、Aleksey Bochkovskiy氏がDarknetの Githubに依拠して、YOLOV.4の開発を行いました。そのGithub サイトはgithub.com/AlexeyAB/darknetです。
2020年に入って、Roboflowという会社が Pytorch 向けの YOLOV4 を発表しました。そのGithubがここです。さらに最近(2020年6月に)、Ultralytics社がPytorch向けのYOLO v.5 を公開しました。そのGithubはgithub.com/ultralytics/yolov5です。YOLOv5は、検出精度と演算負荷に応じてs、m、l、xまでの4モデルがあります。YOLOv5のsモデルを使用することで、YOLOv3のfullモデルに近い性能を、1/4以下の演算量で達成することができています。
最初に、YOLOVv3をダウンロードして用います。ここで用いるYOLOのコードはdarknetと呼ばれるモジュールで実現されています。公式サイトはここです。この公式サイトで説明されている手続きに従って、インストールします。まずはGithubからクローンしましょう。そしてクローンしたフォルダに入ります。その後、makeしてビルドします。ここでは、Linux 系OSでのコンパイルをします。Windows ではCmakeを使用します。
$ git clone https://github.com/pjreddie/darknet.git $ cd darknet $ make
(darknet)$ ./darknet
usage: ./darknet
これで、darknetは正常に作動します。GPUを内蔵するPCで、CUDAをインストールしているときは、Makefile の先頭を
GPU=1
と修正します。その後に、make します。複数回のmake をする場合には、make clean コマンドを打ってください。
working directoryに cfg/ディレクトリが存在しているので、pretrained modelのweigtsをダウンロードすれば、YOLOV3の実行ができます。
(darknet)$ wget https://pjreddie.com/media/files/yolov3.weights
(darknet)$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BFLOPs
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs
4 res 1 208 x 208 x 64 -> 208 x 208 x 64
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BFLOPs
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
8 res 5 104 x 104 x 128 -> 104 x 104 x 128
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
11 res 8 104 x 104 x 128 -> 104 x 104 x 128
12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256 1.595 BFLOPs
13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
15 res 12 52 x 52 x 256 -> 52 x 52 x 256
-----(中略)
99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BFLOPs
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 10.278578 seconds.
truck: 92%
bicycle: 99%
dog: 99%
という結果が表示されます。検出された画像は

です。
次に、Yolov4 の使用について取り上げます。詳細は、Yolo v4 for Windows and Linuxを参照ください。対応する Google Colab はYOLO-v4.ipynbです。以下のように使用します。
$ git clone https://github.com/AlexeyAB/darknet $ cd darknet $ ./build.sh
ここでは、/build.sh を使用していますが、Cmake を使用するときに、バージョンの相違に関するエラーが起きるかもしれません。この時は、CMake のバージョンをアップデートして下さい。
$ wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights $ ./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg
結果はこうなります。pottedplant という新しい物体が検出されています。yolov3 比較して、検出精度は改善されていますが、処理スピードはかなり遅いです。やはり、GPUが必要です。
Loading weights from yolov4.weights... seen 64, trained: 32032 K-images (500 Kilo-batches_64) Done! Loaded 162 layers from weights-file Detection layer: 139 - type = 28 Detection layer: 150 - type = 28 Detection layer: 161 - type = 28 data/dog.jpg: Predicted in 27368.356000 milli-seconds. bicycle: 92% dog: 98% truck: 92% pottedplant: 33%
Yolov3 で行った物体検出と同様の画像「predictions.jpg」が保存されます。OpenCV へのアクセスがうまくいかないときは、「Not compiled with OpenCV, saving to predictions.png instead」と表示されます。
GPUを活用したYOLOv4の実証は、このColabにあります。GPUを使用するように Makefile を修正する必要があります。エディターを用いてもいいですが、以下のようなコードでも修正できます。
# change makefile to have GPU and OPENCV enabled %cd darknet !sed -i 's/OPENCV=0/OPENCV=1/' Makefile !sed -i 's/GPU=0/GPU=1/' Makefile !sed -i 's/CUDNN=0/CUDNN=1/' Makefile !sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile !make
以上のように、OPENCV=1、GPU=1、CUDNN=1、CUDNN_HALF=1 してから、 make します。実行ファイルdarknet がビルドされます。この後、画像からの物体検出を行うには、上記の .darknetb detect ... を実行します。
Scaled-YOLOv4という新しいバージョンも使用できます。上記のColabでは、このScaled-YOLOv4を用いた物体検出も実行できます。YOLOv4に比較してどの程度優れているかはよくわかりませんが、検出物体数が減少しますが、処理スピードは若干速いと思われます。
これは、Linux でのコンパイルの方法で、Windows でのコンパイルでは Visual Studio を使用します。以下の手順で行うことが推奨されています。Powershell を起動して(Start -> All programs -> Windows Powershell) 、以下のコマンドを打ちます。
PS Code\> git clone https://github.com/microsoft/vcpkg PS Code\> cd vcpkg PS Code\vcpkg> $env:VCPKG_ROOT=$PWD PS Code\vcpkg> .\bootstrap-vcpkg.bat PS Code\vcpkg> .\vcpkg install darknet[full]:x64-windows #replace with darknet[opencv-base,cuda,cudnn]:x64-windows for a quicker install of dependencies PS Code\vcpkg> cd .. PS Code\> git clone https://github.com/AlexeyAB/darknet PS Code\> cd darknet PS Code\darknet> powershell -ExecutionPolicy Bypass -File .\build.ps1
独自のデターセットでこのモデルの学習を行う方法については、このサイトを参照してください。
YOLO(You Only Look Once)v3, v4 : Pytorch |
YOLOの公式サイトはここです。このサイトには、インストールなどの手続きが説明されています。活用できるドキュメントも多数掲載されています。YOLO のアルゴリズムを解説している記事は Implement YOLO v3 from scratch にあります。
TensorFlowを使用しないので、処理速度はかなり速くなります。なお、コマンド"wget"を使用しますので、インストールされていないときは、"wget"をインストールして下さい。($ brew install wget)
最初に、Yolov3バージョンを取り上げます。パッケージ 'pytorch-yolo-v3' をダウンロードします。'pytorch-yolo-v3'は このGitHubからgit clone できます。
$git clone https://github.com/ayooshkathuria/pytorch-yolo-v3
学習済みモデルの重みをダウンロードする必要があります。ここでは、'yolov3.weights'を使います。このファイルを pytorch-yolo-v3 フォルダーの下に配置してください。
$ cd pytorch-yolo-v3 $ wget https://pjreddie.com/media/files/yolov3.weights
サイズは248MBです。物体検出にはPython コード 'detect.py' を使います。オプションを見るために、
$python detect.py -h
と打って見てください。検出するときの様々なオプションが表示されます。以下のように入力します。
$python detect.py --images imgs --det det
--images flag は検出対象の画像ファイルの指定をします。ここでは、 'imgs' に画像が入っています。--det は検出済みの画像ファイルを保存するフォルダーを指定します。'det' というフォルダーになっています。コマンドが正常に動作して、下のような表示が出ます。
Loading network..... Network successfully loaded dog.jpg predicted in 1.781 seconds Objects Detected: bicycle truck dog ---------------------------------------------------------- eagle.jpg predicted in 1.751 seconds Objects Detected: bird ---------------------------------------------------------- giraffe.jpg predicted in 1.784 seconds Objects Detected: zebra giraffe giraffe ---------------------------------------------------------- herd_of_horses.jpg predicted in 1.755 seconds Objects Detected: horse horse horse horse ---------------------------------------------------------- img1.jpg predicted in 1.847 seconds Objects Detected: person dog ---------------------------------------------------------- img2.jpg predicted in 1.842 seconds Objects Detected: train ---------------------------------------------------------- img3.jpg predicted in 1.817 seconds Objects Detected: car car car car car car car truck traffic light ---------------------------------------------------------- img4.jpg predicted in 1.768 seconds Objects Detected: chair chair chair clock ---------------------------------------------------------- messi.jpg predicted in 1.812 seconds Objects Detected: person person person sports ball ---------------------------------------------------------- person.jpg predicted in 1.850 seconds Objects Detected: person dog horse ---------------------------------------------------------- SUMMARY ---------------------------------------------------------- Task : Time Taken (in seconds) Reading addresses : 0.001 Loading batch : 3.065 Detection (11 images) : 20.594 Output Processing : 0.000 Drawing Boxes : 0.190 Average time_per_img : 2.168 ----------------------------------------------------------
Tensorflowを使うときに比較して処理速度はより速いです。保存された画像の一つは

です。carとtruckの違いを検出しています。信号機まで検出されています。
リアルタイムでの物体検出の仕方について説明します。web cameraからの映像を取り込むコードは 'cam_demo.py' です。USB接続されたwebcamからの映像をキャプチャーしたいときは、この 'cam_demo.py' の106行が 'cap = cv2.VideoCapture(0)' となっているときは、 'cap = cv2.VideoCapture(1)' に修正してください。
以下の通りに、シンプルにコマンドを入力します。1回目の入力で実行されないときは、2回目の入力をすると実行されます。
$ python cam_demo.py FPS of the video is 0.24 FPS of the video is 0.42 FPS of the video is 0.56 FPS of the video is 0.69 FPS of the video is 0.78 ------
と表示が現れて、webcamの映像で検出された物体に枠がついた動画がリアルタイムで表示されます。動画映像は保存されません。webcamの映像の動きと連動して、ほとんど瞬間的に検出画像が切り替わります。速いです
次に、Yolov4バージョンのPytorch実装を取り上げます。Github repoはpytorch-YOLOv4です。ただ、このpytorchバージョンはGPUを前提としますので、Google Colabを利用した方がいいです。作成したColabはここにあります。
$ git clone https://github.com/Tianxiaomo/pytorch-YOLOv4 $ pip install requirements.txt # 必要がある時
学習済みモデルの重み'yolov4.weights'をダウンロードする必要があります。このファイルを pytorch-YOLOv4 フォルダーの下に配置してください。
$ cd pytorch-YOLOv4 $ wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
サイズは257MBです。物体検出にはPython コード 'demo.py' を使います。以下のように入力します。
$python demo.py -cfgfile cfg/yolov4.cfg -weightfile yolov4.weights -imgfil data/dog.jpg
結果は、predictions.jpgとして保存されます。この画像を表示したいときは、python スクリプトで
from IPython.display import Image
imShow('predictions.jpg')
と入力します。
Pytorch-YOLOv5 |
次に、Yolo(You Only Look Once)v5 バージョンの実装を取り上げます。このパッケージを利用するためには、Python>=3.8 および PyTorch>=1.7 がインストールされていることが必要です。ultralytics/yolov5を参照してください。そのGoogle Colab は YOLOv5_tutorials_roboflow.ipynbにあります。以下のように git clone します
$ git clone https://github.com/ultralytics/yolov5 $ cd yolov5 $ pip install -r requirements.txt
これで準備はできました。通常は、Jupyter notebook を起動して、tutorial.ipynb を使用して実行します。
ここでは、Python スクリプトを用いた物体検出を行ってみましょう。以下のように入力して下さい。
$ python detect.py --source data/images --weights yolov5s.pt --conf 0.25
これは data/images ディレクトリにある2種類の画像からの物体検出の実行例です。結果は以下のように、 runs/detect/exp 内に保存されます。bus.jpg 、 zidane.jpg です。
result: Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='data/images', update=False, view_img=False, weights=['yolov5s.pt']) YOLOv5 v4.0-83-gd2e754b torch 1.7.1 CPU Fusing layers... Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS image 1/2 /Users/koichi/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.313s) image 2/2 /Users/koichi/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.242s) Results saved to runs/detect/exp

Zidane.jpg
「Error #15: Initializing libiomp5.dylib, but found libomp.dylib already initialized.」というエラーが出た場合は、detect.py の中に
import os os.environ['KMP_DUPLICATE_LIB_OK']='True'
という1行を挿入して下さい。このエラーは消えます。
次に、webcamera のライブ映像から物体検出を実行しましょう。webcamera を接続して、以下のように打って下さい。
$ python detect.py --source 0 ----- result: Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='0', update=False, view_img=False, weights='yolov5s.pt') YOLOv5 v4.0-83-gd2e754b torch 1.7.1 CPU Fusing layers... Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS 1/1: 0... success (1280x960 at 25.00 FPS). 0: 480x640 3 bottles, 1 sandwich, 4 books, Done. (0.365s) 0: 480x640 1 cat, 3 bottles, 1 laptop, 6 books, Done. (0.336s) 0: 480x640 3 bottles, 1 laptop, 7 books, Done. (0.341s) 0: 480x640 1 cat, 3 bottles, 1 laptop, 5 books, Done. (0.343s) --- ---
コマンドは非常に簡単です。検出速度は非常に速いです。コマンドの実行時に、「AttributeError: 'NoneType' object has no attribute 'shape'」というエラーが時々出ますが、再度実行すれば正常に作動します。
PyTorch Hub を利用したYOLOv5 の実装については、Load YOLOv5 from PyTorch Hubを参照ください。その説明にそって、以下のスクリプトを作成して、detailed_example.pyとして保存して下さい。
# Detailed Example
import cv2
import torch
from PIL import Image
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True) # for file/URI/PIL/cv2/np inputs and NMS
# Images
for f in ['zidane.jpg', 'bus.jpg']: # download 2 images
print(f'Downloading {f}...')
torch.hub.download_url_to_file('https://github.com/ultralytics/yolov5/releases/download/v1.0/' + f, f)
img1 = Image.open('zidane.jpg') # PIL image
img2 = cv2.imread('bus.jpg')[:, :, ::-1] # OpenCV image (BGR to RGB)
imgs = [img1, img2] # batched list of images
# Inference
results = model(imgs, size=640) # includes NMS
# Results
results.print() # print results to screen
results.show() # display results
results.save() # save as results1.jpg, results2.jpg... etc.
ターミナルから以下のコマンドを打って下さい。
$ python detailed_example.py
二枚の画像(bus.jpg, zidane.jpg)を使った結果が、ディスプレイ上にポップアップ表示され、ディレクトリ result に保存されます。作成するコードが非常に簡単です。

bus.jpg
最近では(2021年3月)、YOLOv5は pip コマンド用いてインストールできるようになっています。例えば、
$ pip install "numpy>=1.18.5,<1.20" "matplotlib>=3.2.2,<4" $ pip install yolov5
と入力すると、使用できます。
PyPIのサイトには、具体的な例として以下のコードが掲載されています。
from PIL import Image
from yolov5 import YOLOv5
# set model params
model_path = "yolov5/weights/yolov5s.pt" # it automatically downloads yolov5s model to given path
device = "cuda" # or "cpu"
# init yolov5 model
yolov5 = YOLOv5(model_path, device)
# load images
image1 = Image.open("yolov5/data/images/bus.jpg")
image2 = Image.open("yolov5/data/images/zidane.jpg")
# perform inference
results = yolov5.predict(image1)
# perform inference with higher input size
results = yolov5.predict(image1, size=1280)
# perform inference with test time augmentation
results = yolov5.predict(image1, augment=True)
# perform inference on multiple images
results = yolov5.predict([image1, image2], size=1280, augment=True)
この後、train.py, detect.py and test.py などのpython スクリプトを pip を用いてダウンロードすることができます。
ご質問、コメントなどは こちらからメール送信して下さい。