
|
近年の急激なコンピュータ技術の発達により人口知能(AI)技術がロボットや自動車の安全運転、スマホによる自然言語や音声の認識、フィンテック、さらには、セキュリティ・システムやIoTのインフラ技術などに応用されるようになってきました。人工知能(AI)技術の基礎は深層学習(deep learning)と言われる分野での研究開発に多くを負っています。深層学習も機械学習(machine learning)の一つの分野であり、または大量のデータを用いてパラメータの学習をするという意味では、データサイエンスと呼ばれている分野における研究にも属します。
Deep Learning(CNN)を応用した一般物体検出の代表的なフレームワークであるCaffeやDetectron上で、SSD: Single Shot MultiBox Detector 、 YOLO(You Only Look Once) 及び R-CNN (Regions with CNN features) などを用いてモデル学習を実行させるためには、NVIDIA GPUのようなCUDAを実装した高速なGPUが前提とされています。ここでは、GPUでのモデル学習を前提としない物体検出のライブラリを取り上げて、学習済みのモデルを用いた物体検出を試みます。
CaffeおよびDetectronでのモデル学習では、NVIDIA GPU向けのCUDAを前提にしていますが、FacebookがCaffeの軽量バージョンとしてCaffe2およびDetecron2をオープンソース・ソフトウエア型式で公開しました。このページでは、CUDAのインストールを前提としないCaffe2とDetectron2の実装事例を取り上げてみたいと思います。Caffe2およびDetectron2 のすべての機能を活用することはまだ出来ていませんが、学習済みのモデルを利用した機械学習の部分は利用可能です。手持ちの画像やWebcameraからの映像から物体を検出することを試みましょう。なお、Python関連のパッケージがインストールされていることを前提とします。
Googleが提供するGoogle Colaboratoryは、Jupyter Notebook をベースとした、Googleの仮想マシン上で動くPython実行環境です。Googleアカウントを登録すれば、インストール等の作業に手間を取られることなく、すぐに機械学習のコードを実行することができます。AIや機械学習に関するページで説明されるPython コードを自分の手で実行したいと希望する方は、Googleのアカウント登録、および、GitHubのアカウントの登録をすることをお勧めします。両方とも無料で行えます。
Caffe2 & Detectron2 を用いた物体検出のコードはこの GitHub Repo にあります。Google Colab で実行可能になっています。
Last updated: 2022.4.15(first uploaded 2019.4.6)
caffe2におけるImage Classifierの実装 |
最近、FacebookがCaffeの軽量バージョンとしてCaffe2をオープンソース・ソフトウエア型式で公開しました。Caffe2のすべての機能を活用することはまだ出来ていませんが、初歩的な部分は利用可能です。Caffe2のホームページはhttps://caffe2.ai です。このサイトに使用上のtutorialsがあります。ソースコードはホームページ上の手続きに従ってダウンロードできます。例えば、MacあるいはWindowsにインストールするときは、このページにある手順に従ってインストールします。
しかし、Tutorialsだけでcaffe2を活用するだけならば、caffe2そのものをインストールする必要はありません。なぜなら、caffe2のコアモジュールがPytorchライブラリの中に収納されているからです。従って、とりあえずは、tutorialsを活用したいので、Pytorchをインストールしてください。Pytorchがインストールされている時は、これをスキップして下さい。このページにある手順に従って、OSの選択をして、pipを選択し、Python、そして、CPUを選択すると、run this commandの欄に以下のコマンドが表示されます。ターミナルから
$ pip3 install torch torchvision
とこのコマンドを入力します。pytorchのインストールが始まります。PyTorchは、ディレクトリ /python3.x/site-packages/ の下に 'torch' とういう名前でインストールされます。
次に、caffe2-tutorialsをダウンロードします。Caffe2のホームページのtutorialsにある説明の通りに、 ターミナルから
$ git clone --recursive https://github.com/caffe2/tutorials caffe2_tutorials
と入力します。ホームディレクトリにcaffe2_tutorialsがインストールされます。
以上で、caffe2_tutorialsの利用は可能となりますが、下記のパッケージがインストールされていないときは、
pip3 install \
graphviz \
hypothesis \
ipython \
jupyter \
matplotlib \
notebook \
pydot \
python-nvd3 \
pyyaml \
requests \
scikit-image \
scipy\
future
pip3でインストールします。anacondaを用いてpython環境をインストールしていケースでは、これらのモジュールの大部分はインストール済みのはずです。なお、zeromq パッケージを使用しますので、インストールされていないときは、
$ brew install unzip zeromq
とインストールして下さい(Macのケース)。Jupyter Notebookを起動して、caffe2_tutorialsを開いてください。その中に、Model_Quickload.ipynbというノートブックがあるので、これを開きます。そこには、pretrained modelのsqueezenetのダウンロードの仕方が説明されています。ターミナルから
$ sudo python -m caffe2.python.models.download -i squeezenet
と打って、caffe2のModel Zooの中にあるsqueezenetをダウンロードします。squeezenetが/lib/python3.x/site-packages/caffe2/python/models/
の中にインストールされます。
一般的的には、Caffe及びCaffe2には、AlexNet、GoogleNet、VGGなど、多数の学習済み畳み込みニューラルネットワークのモデル(pretrained models)が収集されています。これらはModel Zooという名称で呼ばれているフォルダーに配置されています。Model ZooモデルはGitHubのrepository https://github.com/caffe2/models/ にあります。
以下のプログラムでは、squeezenetは /lib/python3.x/site-packages/caffe2/python/models/ にインストールされていることを前提しています。
Jupyter Notebookを開いて、[Python3],[File],[open]をクリックして、/caffe2-tutorials/Model_Quickload.ipynbを開くと、以下のようなセルが表示されます。
# load up the caffe2 workspace from caffe2.python import workspace # choose your model here (use the downloader first) from caffe2.python.models import squeezenet as mynet # helper image processing functions import helpers # load the pre-trained model init_net = mynet.init_net predict_net = mynet.predict_net # you must name it something predict_net.name = "squeezenet_predict" workspace.RunNetOnce(init_net) workspace.CreateNet(predict_net) p = workspace.Predictor(init_net.SerializeToString(), predict_net.SerializeToString()) # use whatever image you want (urls work too) # img = "https://upload.wikimedia.org/wikipedia/commons/a/ac/Pretzel.jpg" img = "images/cat.jpg" # img = "images/cowboy-hat.jpg" # img = "images/cell-tower.jpg" # img = "images/Ducreux.jpg" # img = "images/pretzel.jpg" # img = "images/orangutan.jpg" # img = "images/aircraft-carrier.jpg" #img = "images/flower.jpg" # average mean to subtract from the image mean = 128 # the size of images that the model was trained with input_size = 227 # use the image helper to load the image and convert it to NCHW img = helpers.loadToNCHW(img, mean, input_size) # submit the image to net and get a tensor of results results = p.run([img]) response = helpers.parseResults(results) # and lookup our result from the inference list print (response)
このセルの入力画像は[ img = "images/cat.jpg" ]で指定されます。このセルを実行すると、警告がいくつか表示されますが
Top-1 Prediction: 281 Top-1 Confidence: 0.5136005878448486 Raw top 3 results: [array([281.0, 0.5136005878448486], dtype=object), array([282.0, 0.3236496150493622], dtype=object), array([278.0, 0.07468508929014206], dtype=object)] The image contains a tabby, tabby cat with a 51.36005878448486 percent probability.
という結果が表示されます。画像がtabby cat である確率は51.33%であると。使用された画像は以下の猫の写真です。
いかがですか。他の画像を使用するときは、#記号を外して、[ img = ...]で指定します。その場合は、画像のあるディレクトリを必ず指定する必要があります。ここでの例では、画像があるディレクトリは[ caffe2-tutorials/images/ ]です。画像分類の1000クラス分けのラベルは ImageNet object codeを用いています。
分類に使用される画像はモバイルフォーン、webcamera、デジカメなど多種類の機器で取られたものです。これらの画像の種類や形式は異なりますので、画像認識に際しては同一のサイズに変換処理する必要があります。これを Image Pre-Processing と言います。この前処理の方法については、Image_Pre-Processing_Pipeline.ipynb で説明されています。Caffe2 は画像の分類をするときには、 CHW の形式で処理します。ここで、H: Height、W: Width、C: Channel (BGR in color)です。
読み込んだ画像の原サイズを、CHW形式で(3,227,227)に画像変換してから、画像分類を実行するプログラムを取り上げます。デフォルトでは、画像平均ピクセル数は128とされています。Jupuyter Notebook で caffe2_tutorials/Loading_Pretrained_Models.ipynb を開いて下さい。CAFFE_MODELS のパスの指定はフルパスで書く必要があります。そうでないと"WARNING: INIT_NET not found!"というエラーが出ます。IMAGE_LOCATIONのパス指定は相対パスで大丈夫です。例として、pyenvの仮想環境なので、以下のようにします。
... CAFFE_MODELS = "/Users/koichi/.pyenv/versions/3.9.4/lib/python3.9/site-packages/caffe2/python/models/" IMAGE_LOCATION = "images/flower.jpg" ...
このプログラムを実行すると、以下のような画像処理が行われます。
 Image Shape after rescaling: (227, 386, 3)
Image Shape after rescaling: (227, 386, 3)
 Image Shape after cropping: (227, 227, 3)
Image Shape after cropping: (227, 227, 3)
 CHW Image Shape: (3, 227, 227)
CHW Image Shape: (3, 227, 227)
画像分類の結果は
Raw top 5 results: [array([985.0, 0.9642124772071838], dtype=object), array([946.0, 0.021648133173584938], dtype=object), array([309.0, 0.012225959450006485], dtype=object), array([944.0, 0.0004903553635813296], dtype=object), array([325.0, 0.0004374832205940038], dtype=object)] Top 5 classes in order: [985, 946, 309, 944, 325] Model predicts 'b"'daisy'"' with 96.42% confidence Model predicts 'b"'cardoon'"' with 2.16% confidence Model predicts 'b"'bee'"' with 1.22% confidence Model predicts 'b"'artichoke"' with 0.05% confidence Model predicts 'b"'sulphur butterfly"' with 0.04% confidence
となります。ImageNetでclass 985 がdaisy です。
このノートブックを Google Colab で実行するためには、caffe2_tutorials を /My Drive/ に git clone する必要があります。Colab で、以下のノートブックLoading_Pretrained_Models.ipynb を実行します。このコードを実行すると /My Drive/に上記のフォルダー( caffe2_tutorials )が展開されます。
このノートブックは Colab で使用可能なように修正しています。この結果、上の例と同じ結果がでます。なお、私にGithub repoにあるModel_Quickload.ipynb および Image_Pre-Processing_Pipeline.ipynb も Colab 上で実行できます。
Detectron2におけるObject Detectionのpython実装 |
Detectron2を用いて、学習済みモデルによる Object Detection を試みることにします。Detectron2のライブラリを Detetron2 のGit Repからダウンロードします。INSTALL.mdの手順に沿ってインストールします。Python 、 Pytorch 、OpenCV 、fvcore 、 pycocotools などはインストール済みとします。まず、detectron2 をインストールします。
$ git clone https://github.com/facebookresearch/detectron2.git $ python -m pip install -e detectron2
以上で、Detectron2 にあるpython スクリプトは実行可能になります。Model ZOOにある学習済みモデルの一つ、mask_rcnn_R_50_FPN_3x.yaml を用いた物体検出を試みます。
YOLOで使用される画像dog.jpgを用いて、物体検出を行います。画像dog.jpgをディレクトリ/detectron2/demo/にコピぺして下さい。以下のコマンドを打って下さい。検出された画像がディレクトリ demo に output.png として保存されます。
detectron2 $ python demo/demo.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \ --input demo/dog.jpg --output demo/output \ --opts MODEL.DEVICE cpu MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
ImportError: cannot import name '_registerMatType' from 'cv2.cv2' というエラーが出るかもしれません。それは、以下のようにバージョンが異なるからです。
opencv-python 4.5.2.52
opencv-python-headless 4.5.5.62
この時、インストールを入れ替える必要があります。
$ pip uninstall opencv-python-headless==4.5.5.62 Then reinstall headless 4.5.2.52 with opencv-python package. $ pip install opencv-python-headless==4.5.2.52
Detectron2 のDetectron2 Model Zoo and Baselinesから種々の学習済みモデルがダウンロードできます。例えば、R50-FPN-1xをダウンロードしたときは
detectron2 $ python demo/demo.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \ --input demo/dog.jpg --output demo/output \ --opts MODEL.DEVICE cpu MODEL.WEIGHTS model_final_a54504.pkl R50-FPN-3xのケースでは、 detectron2 $ python demo/demo.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \ --input demo/dog.jpg --output demo/dog_output \ --opts MODEL.DEVICE cpu MODEL.WEIGHTS model_final_f10217.pkl
とします。モデルの学習率が異なるR50-FPN-1xとR50-FPN-3xの結果を比べると、検出精度は同じようなものです。
YOLOV3の結果と比較して、検出の正確度はどうでしょうか。セグメンテーションが加わっています。
Detectron2 は基本的にGPUを用いることを想定していますので、CPUを用いたときの処理速度は遅くなります。Webcameraのライブ映像から物体検出を行うときは
detectron2 $ python demo/demo.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \ --webcam --opts MODEL.DEVICE cpu MODEL.WEIGHTS model_final_f10217.pkl
と入力します。 OpenCVの映像に検出が表示されます。YOLOに比較すると、処理速度は相当に遅いです。GPUが必須です。
同様に、Faster R-CNN を用いた物体検出を行うときは、当該学習済みモデルをダウンロードして、configs/COCO-Detection/以下のyamlファイルを指定します。例えば、
detectron2 $ python demo/demo.py --config-file configs/COCO-DETECTION/faster_rcnn_R_50_FPN_3x.yaml \ --input demo/dog.jpg --output demo/output \ --opts MODEL.DEVICE cpu MODEL.WEIGHTS model_final_280758.pkl
セグメンテーションなしの通常の物体検出だけが行われます。
demo.py の使用法については、
$ python demo/demo.py -h
とコマンドを入力します。すると、以下の通りの説明が表示されます。
usage: demo.py [-h] [--config-file FILE] [--webcam]
[--video-input VIDEO_INPUT] [--input INPUT [INPUT ...]]
[--output OUTPUT] [--confidence-threshold CONFIDENCE_THRESHOLD]
[--opts ...]
Detectron2 Demo
optional arguments:
-h, --help show this help message and exit
--config-file FILE path to config file
--webcam Take inputs from webcam.
--video-input VIDEO_INPUT
Path to video file.
--input INPUT [INPUT ...]
A list of space separated input images
--output OUTPUT A file or directory to save output visualizations. If
not given, will show output in an OpenCV window.
--confidence-threshold CONFIDENCE_THRESHOLD
Minimum score for instance predictions to be shown
--opts MODEL.DEVICE cpu the option to run on CPU
Detectron2をGoogle Colabで実行する |
Detectron2のコードはGPUを使用することを前提に開発されていますので、GPUを搭載しないPCやモバイルでもGoogle ColabのGPUサービスを利用すれば、Detectron2のコードを実行することが容易にできます。Detectron2のGitHub Repoにある Colab Notebook を用いて実験します。このColab Notebook を開くと、Google Colabのサイトに行きます。
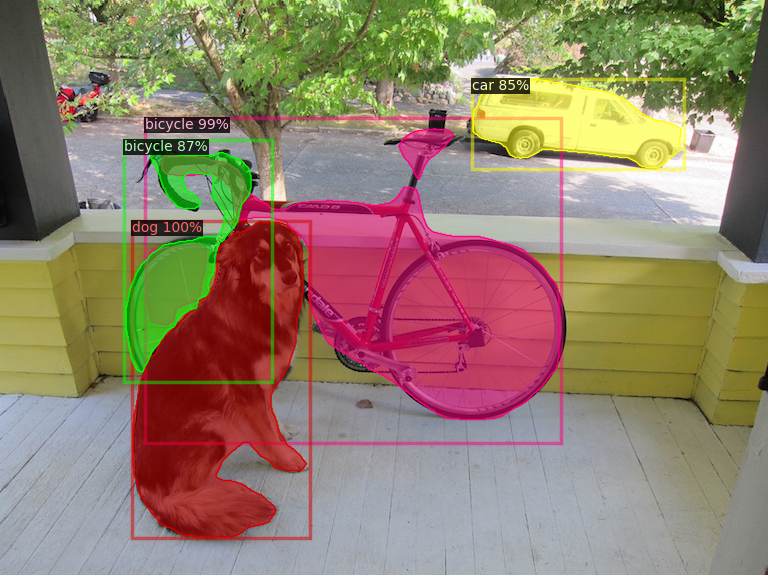
「Detectron2 Beginner's Tutorial」というタイトルのノートブックが表示されます。左上にある「Playground で開く」をクリックします。ランタイムの設定はGPUを使用する設定になっています。このノートブックを自分のGoogle Driveに保存して使用したいときは、「ドライブにコピー」をクリックして下さい。コピーせずそのままでも実行できます。各セルの左にある三角形の実行ボタンを上から順にクリックすると、順次セルが実行されていきます。ランタイムで「すべてのセルを実行」をクリックすれれば、ノートブック全体のセルを実行します。Colab Notebook で、学習済みモデルを使った画像(COCO datasetから)のセグメンテーションが実行されます。MASK R-CNN R50 FPN_3xモデルを用いたとき、以下のようにセグメンテーションが行われます。

なお、maskrcnn-benchmarkモデルを用いて、Google Colabで実行した物体検出のもう一つの例は

です。maskrcnn-benchmarkモデルは廃止になるとアナウンスされています。
「Train on a custom dataset」のセクションでは、 the balloon segmentation dataset を用いた再学習を取り扱っています。COCO datasetには風船のカテゴリがないので、風船を検出するためには coco-pretrained R50-FPN Mask R-CNN model の再学習が必要です。 Colab の GPU を用いる場合、2分程度で学習は終了します。以下のようなセグメンテーションが実行された画像となります。

Recurrent Neural Network のページへ