Transformer の構造
|
従来、 自然言語処理 における Deep Learning アルゴリズムと言えば、 LSTM や GRU といった RNN (Recurrent Neural Network) でした。ところが、2017年6月、"Attention Is All You Need" という強いタイトルの論文が Google から発表され、機械翻訳のスコアを既存の RNN モデル等から大きく引き上げます。論文”Transformer: A Novel Neural Network Architecture for Language Understanding”において、RNN や CNNを使わず Attention のみ使用したニューラル機械翻訳 Transformer が提案された。
Transformer をテキストや画像だけでなく、動画や音声など多種類のデータに応用するマルチモーダルAIが多数発表されています。従来は、コンピュータビジョンでは畳み込み畳み込みニューラルネットワーク(CNN)を用いたアーキテクチャーがが圧倒的な存在感を示していた。現在では、Transformer ベースのアーキテクチャーが浸透しています。
Transformerを画像認識に応用した初期の例はグーグルが2021年に発表した「Vision Transformer(ViT)」です。現在は、Transformer を組み込んだAIが画像識別のタスクでも認識精度を向上させています。従来のCNNは画像をまず小さなピクセルの部分に分割して、各部分ごとに特徴を抽出していました。それに対して、Transformer を基礎とするアーキテクチャーは画像を自然言語の形態素解析と同じ形式で、ベクトルの系列として埋め込んで、それに「Positional Embedding」を加えて、画像全体から特徴を一度に抽出します。画像全体に配置する物体の輪郭の関係を適切に把握できるようになります。
OpenAI が提供している画像生成 AI の DALLE 音声生成 AI の Whisper も Transformer を組み込んでいます。
Last updated: 2024.8.31
Transformer の特徴 |
周知の通り、Transformer のアーキテクチャーは、主に自然言語処理 (NLP)の分野で使用され、BERT、LLaMA 2やChatGPT などの基礎となっています。 Transformer は、文章を理解するために「エンコーダ」と「デコーダ」という二つのネットワークから構成されています。この二つは、Self-Attentionメカニズムという処理方法を組み込んでおり、Self Attention メカニズムによる処理を行う点に特徴があります。Self Attention とは、系列データ、例えば、テキスト、音声、などに含まれる各要素(トークン)と他の要素(トークン)との系列的な位置関連性を考慮して計算する仕組みです。この Self Attention Mechanism により、文中に含まれる各単語間(トークン)の系列上の関連性を効率的に捉えることが可能になっています。
下のTransformerの構造図の左側のネットワークがエンコーダで、右側がデコーダです。 この図から分かる通り、エンコーダとデコーダの最初に「Positional Encoding」があります。これは、トークンの位置情報を加えるための処理です。Input Embedding は、文章をトークン化(形態素解析と言います)して、各トークンをベクトル化する(埋め込みベクトル化)役割をします。
エンコーダは、Self-Attention層と Position-wise Feed-Forward Networks(FFNN)という二つのネットワークから構成されています。このエンコーダは、入力文章の各トークンの重要性や関連性を加味して、ベクトルの系列に変換することです。各トークンを文中に現れる順番で見るのではなく、文章内の各トークンの位置や関連性に関する情報が付加されて、各トークンに固有の番号を割り当てます。出力されるトークンのベクトルは「その単語がどのような単語と一緒に出現しているか」という情報、つまり文脈の情報を含んでいます。
一方、デコーダの役割は、エンコーダによって変換されたベクトルの系列を受け取り、処理内容に応じて別の形式へ変換することです。例えば、英語からフランス語への翻訳を行う際は、ベクトルの系列に変換された英語の文章をフランス語の文章へと変換します。エンコーダは英語の文章を解析しその文章の埋め込みベクトルの系列を出力します。デコーダはエンコードから得た情報を活用してフランス語の文章を生成します。
デコーダの構成はエンコーダに似ていますが、Self-Attention層とPosition-wise Feed-Forward Networks(FFNN)の間に、Encoder-Decoder Attention層が存在します。下の図を参照ください。
![]()
Transformer の構造
Transformerを言語や画像だけでなく動画や音声、3次元データなど多種類のデータに適用するマルチモーダル AI のモデルも次々と登場しています。従来は、畳み込みニューラルネットワーク(Convolutional Neural Network、CNN)を用いて構築されていた画像認識の分野でも、現在はTransformerベースの AI が開発されています。
Transformerを画像認識に応用した代表例はグーグルが2020年に発表した「Vision Transformer(ViT)」です。現在では、Transformerベースの画像認識AIが認識精度でCNNベースのAIを上回り始めています。理由は簡単です。CNNは画像をまず小さなピクセルの部分に分割して、各部分ごとに特徴を抽出します。それに対して、Transformer では画像を分割せずに、画像を一つのシーケンスとして、各物体の位置関係と特徴を抽出します。従って、画像全体にまたがるような大きな物体の輪郭も適切に把握できるようになります。
HugginFace の GitHub レポジトリには Transormer を組み込んだ Vision Transformer や DEtection TRansformer などの画像生成 AI、音声生成 AI のモデルのコードが多数紹介されています。以下で、これらのコードを紹介します。
Vision Transformer を用いた物体識別 |
Vision Transformer(ViT) は、2021年に論文"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale"によって提案されたモデルです。
ViT は画像をいくつかのパッチに分け、それらを自然言語のトークンのように扱います。これにより、画像データの形式と Transformer エンコーダが想定する文章の形式とを整合させています。言い換えると、 自然言語処理のTransformerを使用して処理を行うためには、文章データと同じ形式に画像を変換する必要があリます。従って、ViTのはじめに行う処理として、入力画像を(トークンに対応する)固定サイズのパッチに分割する必要があります。このパッチの系列をトークンの系列のように扱うことによって、Transformerの処理を実現します。自然言語処理の場合でいう形態素解析が、ViT での画像分割に対応します。
Transformerは画像データの各パッチをベクトルに変換するために、Flatten(1次元化)を行い、低次元空間への線形射影を行います。そのデータに Position Embedding 処理をして、Transformer Encoder に入力します。
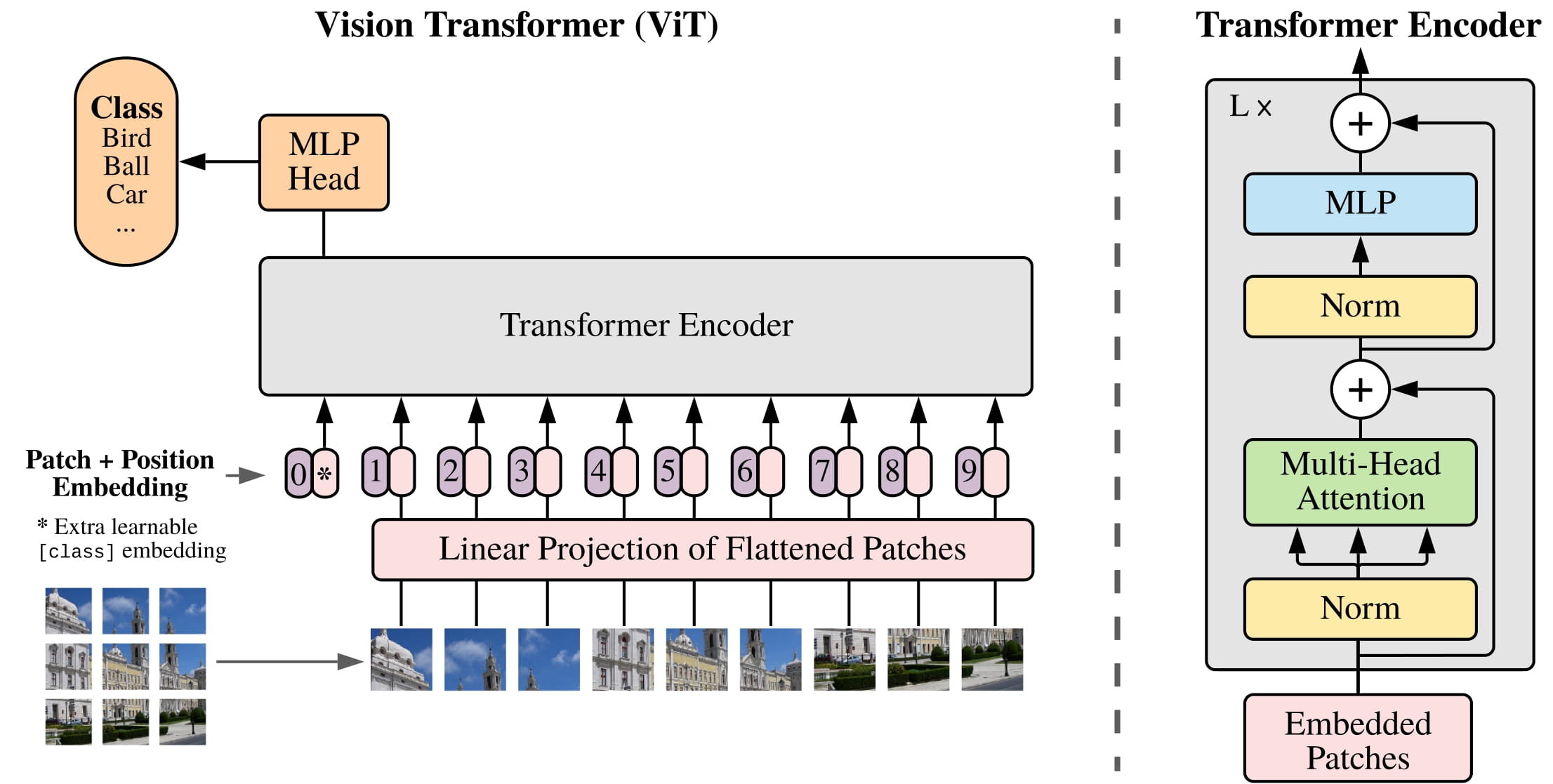
Vision Transformer の構造
COCO 2017 datasetの中の一つの画像で ViT による物体識別を実行してみましょう。以下のコードを実行します。PyTorch を使用するので、 PyTorch もインストールします。最初に、ターミナルから、以下のコマンドを入力します。その後、Python 環境下で実行します。Jupyter Notebook を使用することもできます。
$pip install torch torchvision torchaudio $pip install transformers $pip install timm
from transformers import ViTImageProcessor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
このコードを実行すると、以下の結果が表示されます。
Predicted class: Egyptian cat
Transformer を用いた物体検出:DETR (DEtection TRansformer) |
Transformer を用いた物体検出モデル、DETR (DEtection TRansformer)を使ってみましょう。DETR は、End-to-end object detection with Transformersとして提案されたモデルです。そのコードはFacebook Research の GitHubに掲載されています。
複雑な手作業によるオブジェクト検出パイプラインを Transformer に置き換え、Faster R-CNN を ResNet-50 と一致させ、半分の計算能力 (FLOP) と同じ数のパラメーターを使用して COCO で 42 AP を取得します。50 行の PyTorch での推論を実行します。また、以下のように説明されています。下のDETR の構造図を参照ください。「DETR は、従来のコンピューター ビジョン技術とは異なり、オブジェクト検出を直接セット予測問題として扱います。二部マッチングを用いた一意の予測を強制する集合ベースのグローバル損失と、Transformer エンコーダー/デコーダー・アーキテクチャで構成されます。学習されたオブジェクト・クエリの固定された小さな集合が与えられると、DETR はオブジェクトの関係とグローバル画像コンテキストを推論して、最終的な予測セットを直接並列に出力します。この並列性により、DETRは非常に高速で効率的です。

DETR の構造
HuggingFace の公式サイトに説明されている Quick Tour を参考にして、物体検出の実験を行なってみましょう。Transformer をインストールする必要があります、同時に、関連するパッケージもインストールします。ここでは、PyTorch を使用するので、 PyTorch もインストールします。Jupyter Notebook の最初のセルに以下のコマンドを入力します。
!pip install torch torchvision torchaudio !pip install transformers !pip install timm
すぐに使用できる pretrained pipeline モジュールがあるのでこれを利用します。自然言語処理のみならず、コンピュータビジョン関連のコードもあります。画像からの物体検出も容易にできます。
import requests
from PIL import Image
from transformers import pipeline
# Download an image with cute cats
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
image_data = requests.get(url, stream=True).raw
image = Image.open(image_data)
# Allocate a pipeline for object detection
object_detector = pipeline('object-detection')
object_detector(image)
以下の結果が出ます。
No model was supplied, defaulted to facebook/detr-resnet-50 and revision 2729413
(https://huggingface.co/facebook/detr-resnet-50).
Using a pipeline without specifying a model name and revision in production is not recommended.
Some weights of the model checkpoint at facebook/detr-resnet-50 were not used when initializing DetrForObjectDetection:
['model.backbone.conv_encoder.model.layer1.0.downsample.1.num_batches_tracked',
'model.backbone.conv_encoder.model.layer2.0.downsample.1.num_batches_tracked',
'model.backbone.conv_encoder.model.layer3.0.downsample.1.num_batches_tracked',
'model.backbone.conv_encoder.model.layer4.0.downsample.1.num_batches_tracked']
- This IS expected if you are initializing DetrForObjectDetection from the checkpoint of a model trained on another task
or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DetrForObjectDetection from the checkpoint of a model that you expect to
be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[{'score': 0.9982201457023621,
'label': 'remote',
'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
{'score': 0.9960021376609802,
'label': 'remote',
'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
{'score': 0.9954745173454285,
'label': 'couch',
'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
{'score': 0.9988006353378296,
'label': 'cat',
'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
{'score': 0.9986783862113953,
'label': 'cat',
'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
但し書きにある通り、ここで使用されたモデルは detr-resnet-50 です。Backbone は、CNNと Positional Embedding から構成されます。Backbone のCNNにResNet50を採用しています。このCNNは画像の特徴量をエンコードするために使われます。
類似のコードは、この Google Colaboratoryにあります。このコードも試してみてください。以下の画像結果が表示されます。
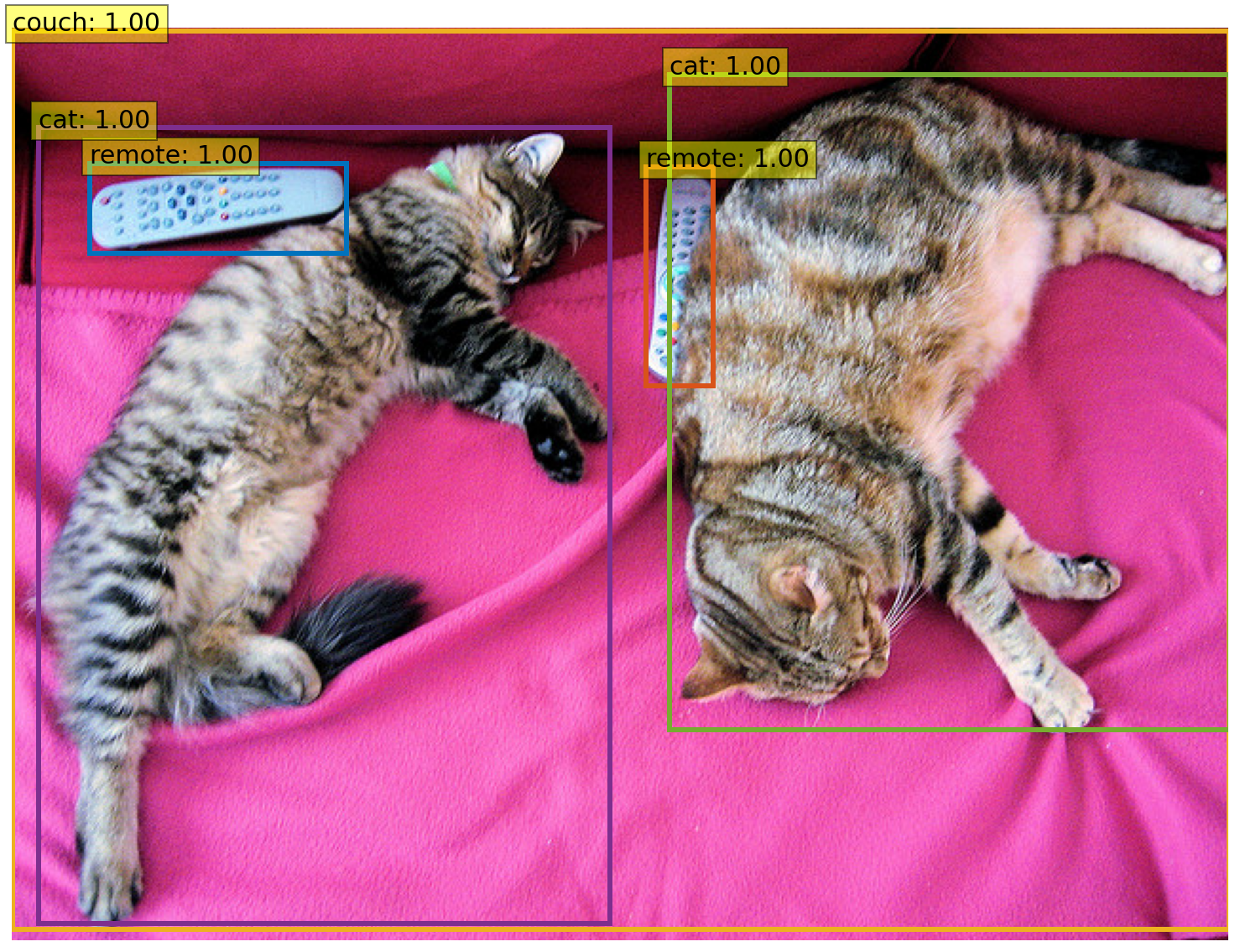
DETR の検出結果